
* Texto livremente adaptado do tutorial publicado por Andrew Andrade no Data Science Guide e traduzido pela editora/analista de dados Bruna Baldini, com revisão e comentários da Escola de Dados em colchetes.
Clique aqui para ver a primeira parte deste tutorial.
Dataset Iris
Para este artigo sobre Análise Exploratória de Dados, vamos investigar o quarteto de Anscombe e o conjunto de dados (dataset) Fisher’s Iris.
“O quarteto de Anscombe compreende 4 datasets que têm propriedades estatísticas quase idênticas e mesmo assim aparecem muito diferentes quando visualizados em grafos. Cada dataset consiste de 11 pontos (x,y). Eles foram construídos em 1973 pelo estatístico Francis Anscombe para demonstrar tanto a importância de colocar os dados em grafos antes de analisá-los, como o efeito dos outliers em propriedades estatísticas”.
O dataset de Iris é um conjunto de dados multivariado e foi introduzido por Ronald Fisher em seu artigo de 1936 “The use of multiple measurements”. Ele mostra a variação das flores de Iris de 3 espécies diferentes.
Sínteses estatísticas
Sínteses estatísticas são medições feitas para descrever dados. No campo da estatística descritiva, há muitas mensurações pontuais, mas deixaremos a definição (e derivação) para os livros didáticos. Exemplos de estatística descritiva, ou síntese estatística, para variáveis numéricas são a média, mediana, moda, máxima, mínima, intervalo, quartil/porcentagem, variância, desvio padrão, coeficiente de determinação, assimetria e curtose. Síntese estatística para variáveis categóricas é o número de contagem e valores distintos. A estatística mais básica para dados em formato de texto é a frequência de termos e o inverso da frequência nos documentos. Para dados bivariados, a síntese estatística é a correlação linear, teste Qui-quadrado , ou o valor de p com base no teste z, teste t ou análise de variância. Este link destaca a sínteses estatísticas comuns, suas equações básicas e uma descrição. Isso deve servir como uma revisão, uma vez que você deve ter um entendimento sólido de estatística a esta altura.
Você pode baixar a planilha de Anscombe com sínteses estatísticas e o dataset de planilhas do Iris com a síntese estatística para cada variável.
Perceba como no dataset de Anscombe a média, o desvio padrão e a correlação entre x e y são quase idênticos. Quando aprendermos sobre regressão linear, vamos ver também os mesmos coeficientes para regressão linear.
Visualização
Além de síntese estatística, visualizações podem ser usadas para explorar e descrever dados. Vamos aprender nos tutoriais a importância da visualização, e que não é suficiente usar propriedades estatísticas simples para descrever dados. O quarteto de Anscombe demonstra isso, como destacado no artigo “Por que visualizações de dados (são importantes)?”. Este é também é um ótimo artigo e livro sobre as imperfeições das médias.
Exemplos de visualização para dados numéricos são gráficos em linha com barras de erros, histogramas e diagramas de caixas; para dados categóricos, gráficos de barras e “gráficos de waffle” (waffle charts) e para dados bivariados são gráficos de dispersão ou gráficos combinados. O tutorial de AED perpassa muitas dessas visualizações.
Há muitas ferramentas e bibliotecas que podem ser usadas para elaborar visualizações: Excel, Libre Office – Weka – matplotlib (python) – seaborn (Python) – Gramática de grafos (ggplot2) – infovis – rshiny – documentos orientados a dados (D3.js) – panoramix.
Para complementar: Tibco, Spotfire e Tableau são populares, contudo são soluções comerciais para visualização de dados.
Para o próximo conjunto de imagens, clique na imagem para ser redirecionado ao exemplo com o código-fonte.
Dados univariados (uma variável)
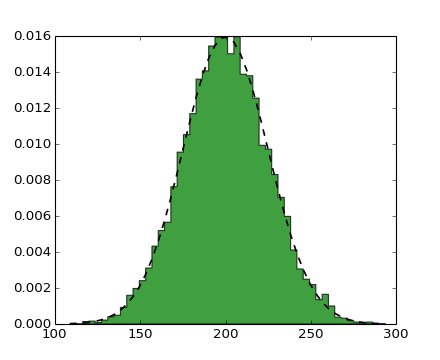
As duas visualizações usadas para descrever dados univariados (uma variável) são gráfico de caixa e o histograma. O gráfico de caixa pode ser usado para mostrar o mínimo, o máximo, a média, a mediana, os quartis e os intervalos.
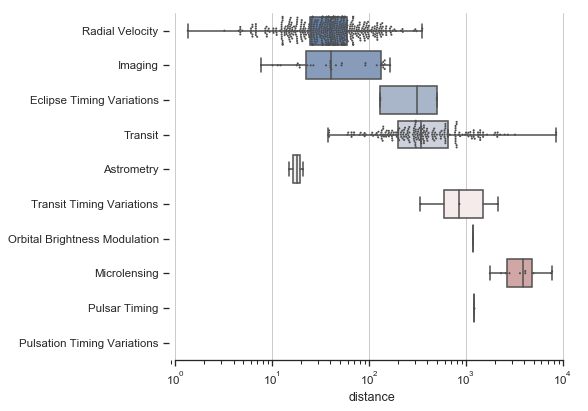
O histograma pode ser usado para mostrar contagem, moda, variância, desvio padrão, coeficiente de variação, assimetria e curtose.
Dados bivariados (Duas variáveis)
Quando se visualiza a relação entre duas variáveis, podemos usar um gráfico de dispersão.
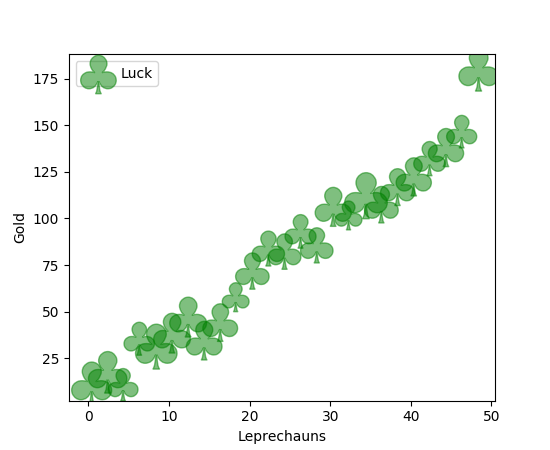
Se os dados são uma sequência cronológica ou têm uma ordem, podemos utilizar um gráfico de linha.
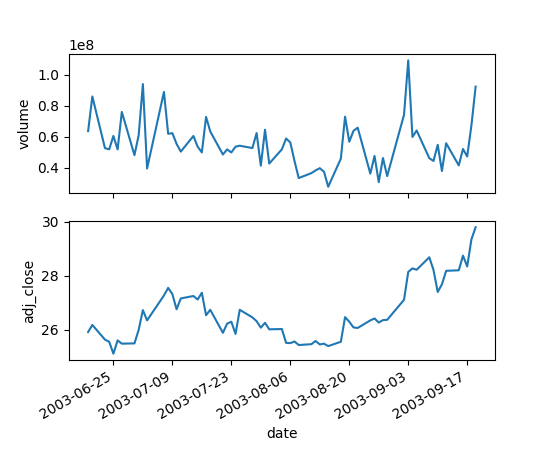
Visualizações multivariadas
Ao lidar com múltiplas variáveis, é tentador fazer três esquemas dimensionais (eixos), mas conforme se mostra a seguir, isso pode dificultar a compreensão dos dados:
Recomendo, preferencialmente, criar um gráfico de dispersão da relação entre cada variável:
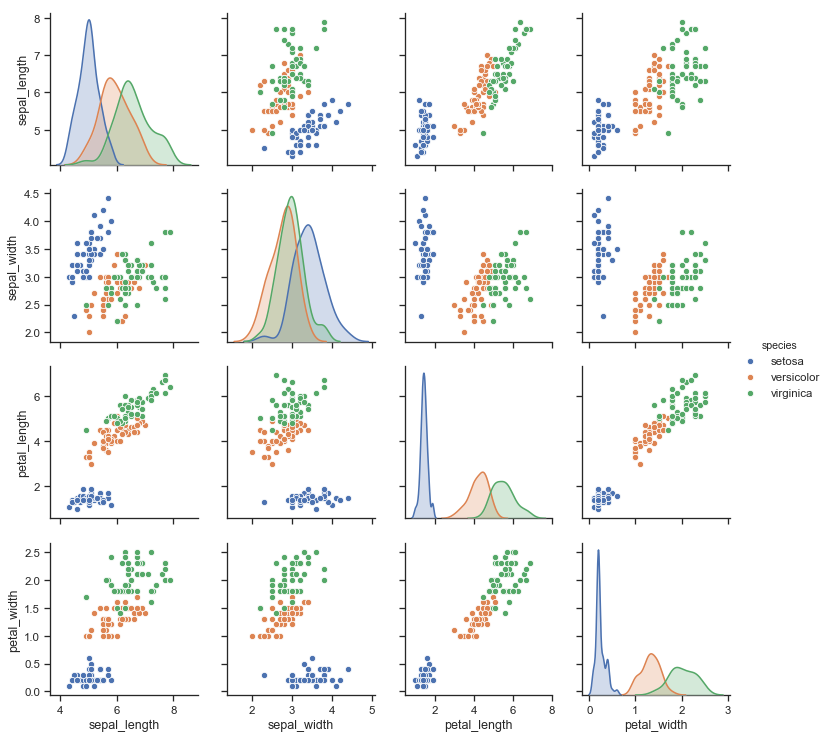
Gráficos combinados podem ser excelentes maneiras de visualizar dados, uma vez que cada gráfico por si só se torna mais simples de entender.
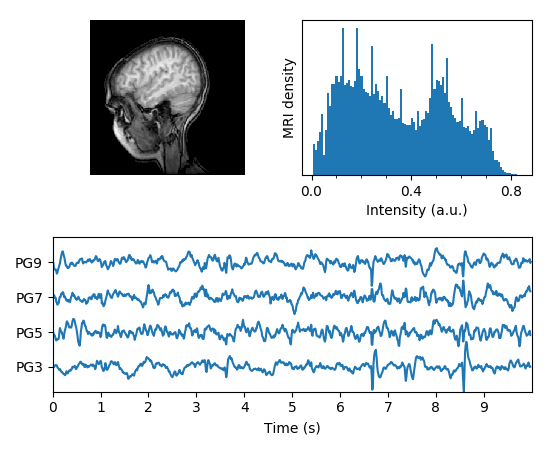
Para uma dimensionalidade muito grande, pode-se reduzi-la usando os principais componentes da análise, Alocação Dirichlet Latente ou outras técnicas e depois fazer um gráfico das variáveis reduzidas. Isto é particularmente importante para dados com grande amplitude de dimensionalidade e tem aplicações em deep learning, tais como a visualização natural de linguagem ou imagens.
—
Para conferir o texto completo, com as referências finais, confira o artigo original.








