
[O texto abaixo é um resumo do artigo “Tidy Data” publicado no Journal of Statistical Software, por Hadley Wickham, em 2014. O resumo em português foi feito por Adriano Belisário, no contexto do MOOC de jornalismo de dados realizado pelo Knight Center em parceria com a Escola de Dados.]
Hadley Wickham é estatístico e um dos mais proeminentes membros da comunidade de desenvolvedores da linguagem R, em especial por seu papel na criação de bibliotecas de softwares que tornam mais fácil a vida de quem trabalha com dados. Em um artigo de 2014, ele sintetizou um pouco da filosofia por trás de suas contribuições em um artigo – já clássico – intitulado “Tidy Data”.
Wickham inicia o artigo apontando que há poucas pesquisas sobre o processo de limpeza e preparação de dados, apesar desta etapa consumir boa parte do tempo na hora de analisá-los. Seu texto foca em um pequeno, porém importante, aspecto deste processo: a organização dos dados (data tidying).
Mas o que significa isso? Antes de explicar a ideia de “dados arrumados/organizados” ou “tidy data”, vamos começar por algumas definições básicas.
A maioria dos conjuntos de dados estatísticos são tabulares. Ou seja, são representados por uma tabela, contendo linhas e colunas. No entanto, os mesmos dados podem ser representados de diferentes maneiras. Veja, por exemplo, as duas tabelas abaixo: os valores são os mesmos, mas a estrutura delas é diferente.

Tabela 1: Apresentação típica de conjunto de dados.

Tabela 2: Os mesmos dados da Tabela 1, mas estruturados de maneira diferente.
Vejamos um terceiro exemplo. A tabela a seguir reorganiza os dados da primeira tabela para tornar os valores, variáveis e observações mais evidentes. No caso, temos três variáveis:
- pessoa (person), com três valores diferentes (John, Mary e Jane)
- tratamento (treatment), com dois valores distintos (A e B)
- resultado (result), com os valores numéricos associados a cada tratamento

Tabela 3: Os mesmos dados da Tabela 1, mas com variáveis em colunas e observações em linhas.
Apesar de ser fácil identificar o que são variáveis e observações para uma tabela específica, é difícil fazer uma definição geral. A proposta de Wickham dos “dados organizados” (tidy data) é justamente fixar um padrão que fornece um elo entre a estrutura dos dados e seus significados.
Este padrão é simples, basta atender a três regras fundamentais:
- Cada variável é uma coluna;
- Cada observação é uma linha;
- Cada tipo de unidade observacional é uma tabela;
Assim, qualquer outro dado que não obedeça a este formato poderiam ser considerados bagunçados (messy data). A Tabela 3 é a versão organizada da Tabela 1.
Na sequência, Wickham lista 5 dos problemas mais comuns na hora de organizar os dados de acordo com estes princípios.
- Os cabeçalhos (a primeira linha da tabela) são valores, não o nome das variáveis;
- Diversas variáveis estão armazenadas na mesma coluna;
- Variáveis armazenadas tanto em linhas, como em colunas;
- Diferentes tipos de unidades observacionais estão armazenadas na mesma tabela;
- Uma única unidade observacional está armazenada em diferentes tabelas.
Vejamos cada um destes problemas.
1. Os cabeçalhos (a primeira linha da tabela) são valores, não o nome das variáveis;
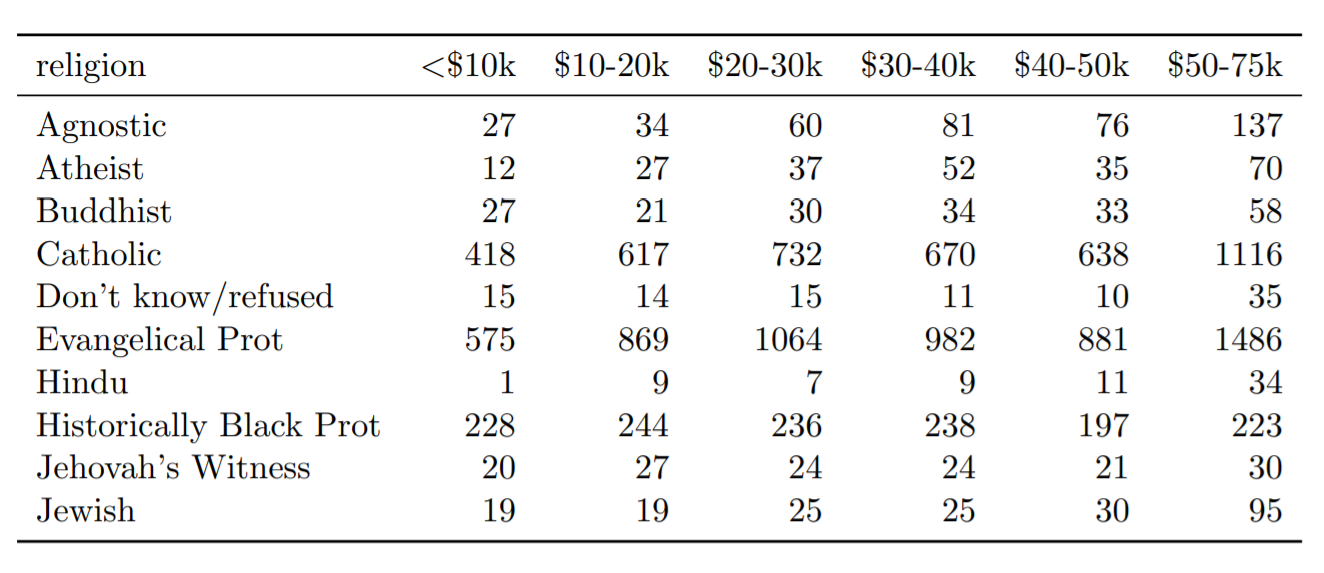
Tabela 4: As dez primeiras linhas de dados sobre renda e religião do Fórum Pew. Três colunas $ 75-100k, $ 100-150k e >150k, foram omitidas.
Apesar de reconhecer que tal estrutura de armazenamento de dados pode ser extremamente eficiente, a depender do propósito da análise, Wickham mostra que esta forma de estruturar os dados não segue os princípios definidos anteriormente. O conjunto de dados acima possui três variáveis (religião, renda e frequência) e, para ser arrumado, Wickham mostra que ele precisaria ser “fundido” (melt) ou “empilhado” (stack). Ou seja, é preciso transformar as colunas em linhas.
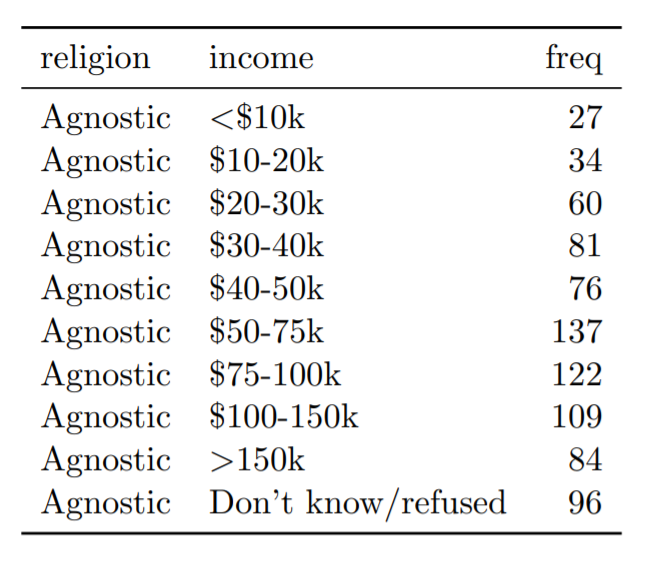
Tabela 6: As dez primeiras linhas do conjunto de dados da pesquisa Pew organizado sobre renda e religião. As colunas foram renomeadas para renda, valor e freq.
Na tabela 6, é possível ver como o conjunto de dados se pareceria neste novo formato.
Outro exemplo é esta tabela com um ranking de músicas. Repare nas últimas três colunas, que representam a semana (wk1, wk2, etc) e a posição no ranking.
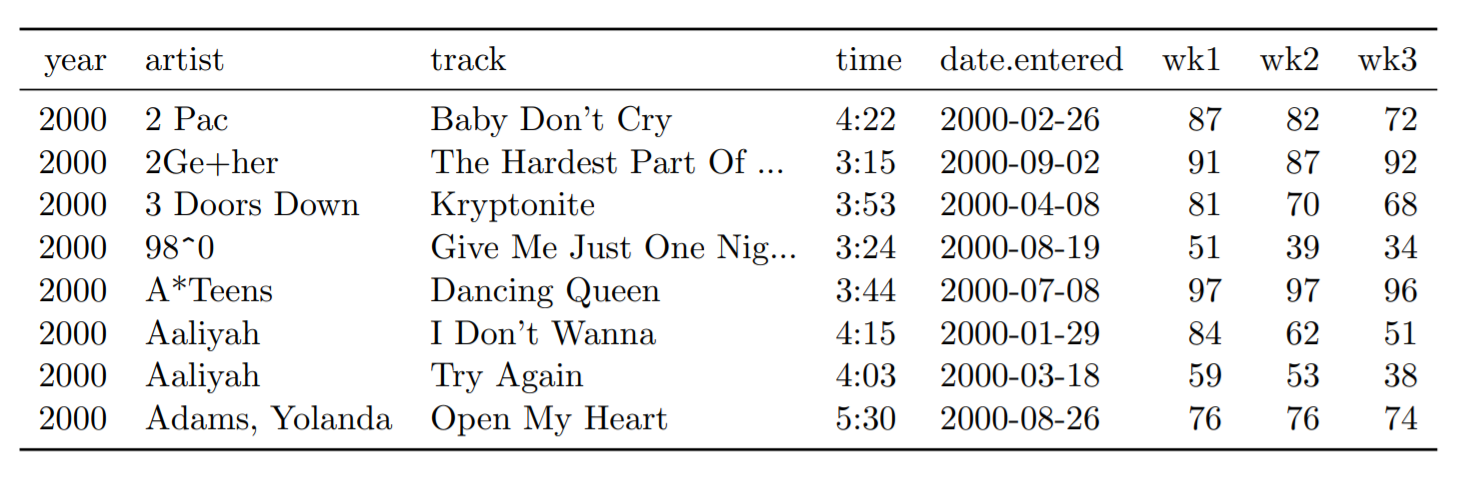
Tabela 7: Os oito primeiros hits do topo da Billboard em 2000. Outras colunas não mostradas são wk4, wk5, …, wk75.
Nos dados acima, o cabeçalho da tabela contém um valor: o número da semana em questão. Já na tabela abaixo os mesmos dados estão arrumados no formato “tidy”. Agora, o número das semanas é representado como valores de uma variável chamada “week”.
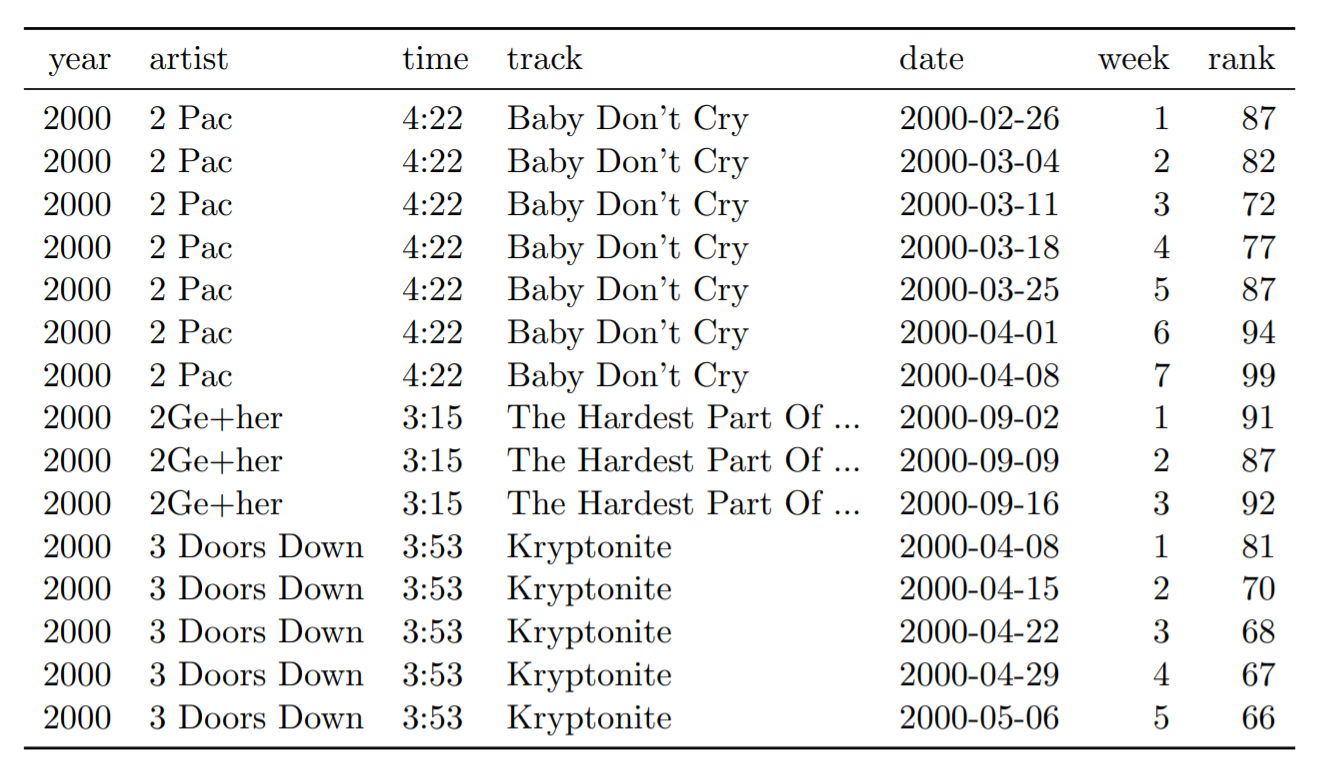
Tabela 8: Primeiras quinze linhas do conjunto de dados organizados do quadro de avisos. A coluna da data não aparece na tabela original, mas pode ser calculada a partir de date.entered e week.
2. Diversas variáveis estão armazenadas na mesma coluna
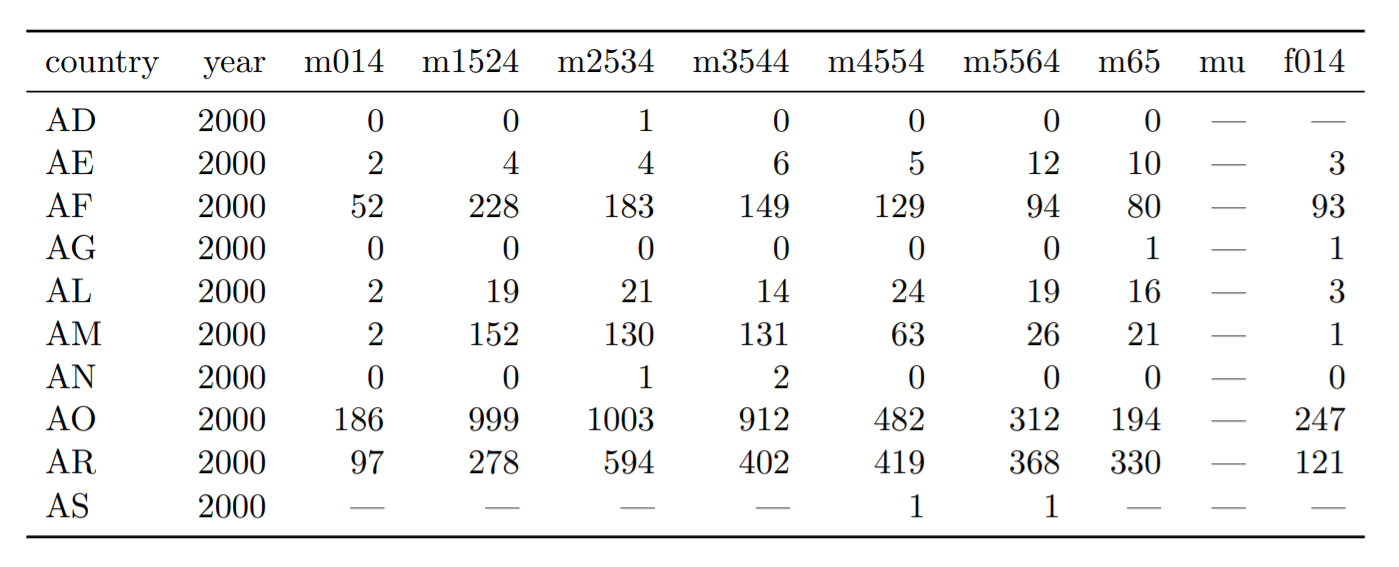
Tabela 9: Conjunto de dados de original, sobre casos de tuberculose. Para cada coluna ‘m’ para homens, há uma coluna ‘f’ para mulheres: f1524, f2534 e assim por diante. Elas não são mostrados para economizar espaço. Observe a mistura de zeros e valores ausentes (-). Isso se deve ao processo de coleta de dados. Esta distinção entre zeros e ausentes é importante para este conjunto de dados.
A tabela acima é da Organização Mundial de Saúde. Os registros trazem a contagem de casos confirmados de tuberculose por país, ano e grupo demográfico. Estes últimos estão representados nas colunas e são divididos por sexo (“m” para masculino e “f” para feminino) e idade (0-14,15-25-25-34). Para poupar espaço, nem todas colunas são apresentadas acima.
Na tabela abaixo (10b), vemos estes mesmos dados de forma organizada, onde as variáveis “sexo” e “idade” são decompostas em duas variáveis reais, representadas por colunas diferentes.
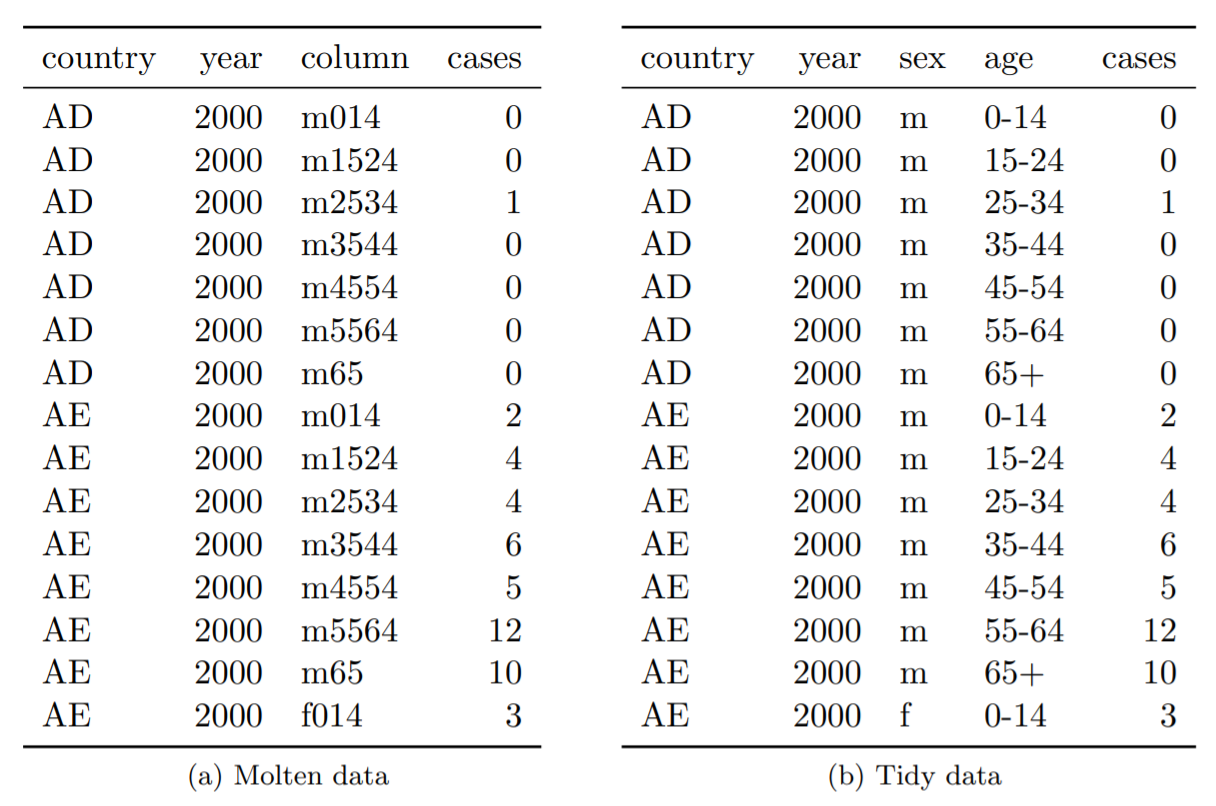
Tabela 10: Organizar o conjunto de dados de requer primeiro a fusão e depois a divisão de coluna em coluna em duas variáveis: sexo e idade.
3. Variáveis armazenadas tanto em linhas, como em colunas;
Segundo Wickham, esta seria a forma mais complicada, entre os “dados bagunçados”. A tabela abaixo mostra dados de um estação climática no México (MX17004) ao longo de cinco meses em 2010. Há variáveis como colunas individuais (id, ano, mês), mas também há variáveis espalhadas em várias colunas (dia, d1-31) e entre linhas (tmin, tmax – indicando a temperatura mínima e máxima).
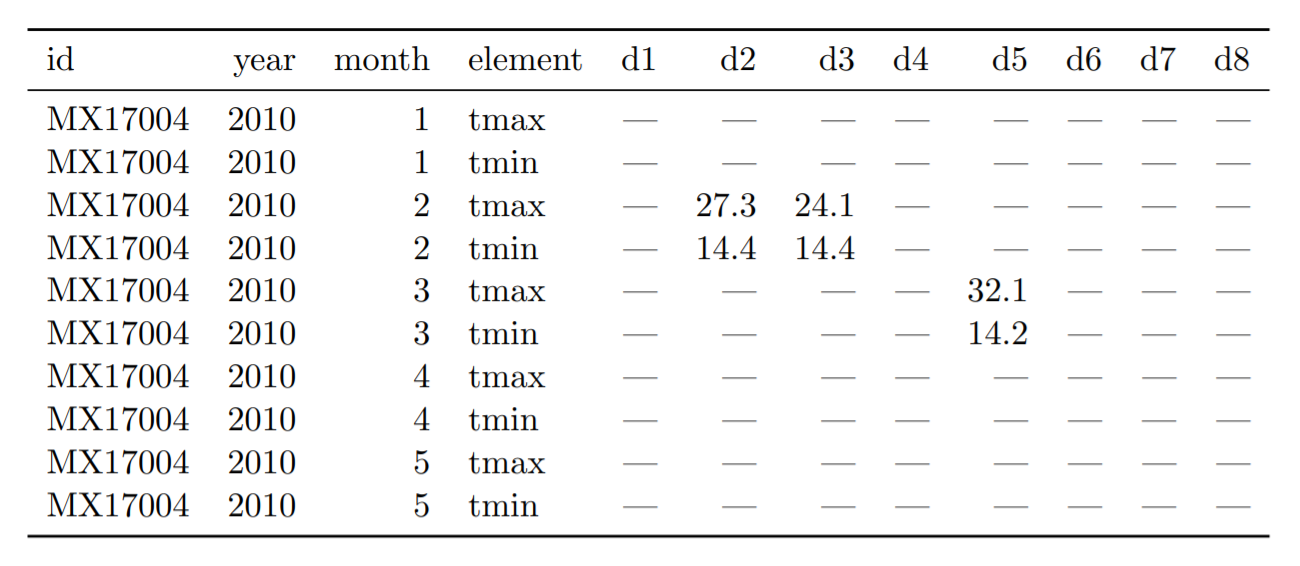
Tabela 11: Conjunto de dados meteorológicos originais. Há uma coluna para cada dia possível no mês. Colunas d9 a d31 foram omitidos para economizar espaço.
Para organizar estes dados, a primeira coisa necessária é “empilhar” as variáveis sobre grupos demográficos. Com isso, chegaríamos à tabela da esquerda. Depois, a coluna é dividida em duas: uma para representar o sexo e outra para a idade. Com isso, como mostra a tabela da direita, os dados ficam no formato “tidy”.
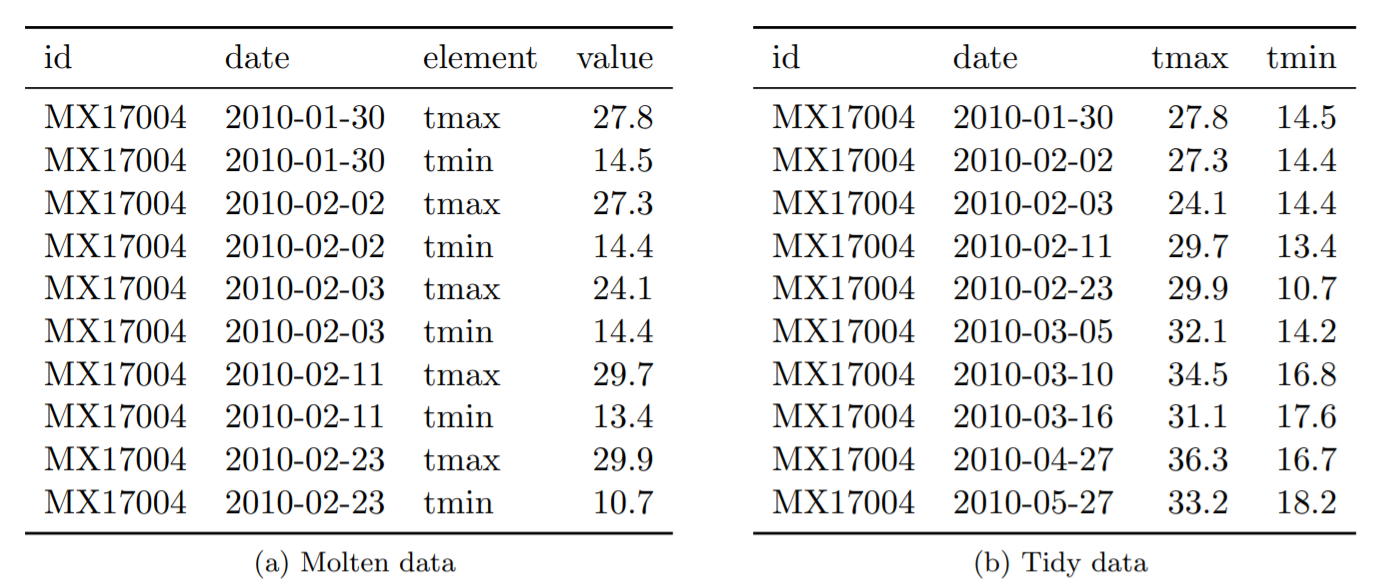
Tabela 12: (a) Conjunto de dados meteorológicos fundidos. Isso está quase organizado, mas, em vez de valores, a coluna element contém nomes de variáveis. Os valores ausentes foram descartados para economizar espaço. (b) Conjunto de dados meteorológicos organizados. Cada linha representa as medições meteorológicas para um único dia. Existem duas variáveis medidas, temperatura mínima (tmin) e máxima (tmax); todas as outras variáveis são fixas.
4. Diferentes tipos de unidades observacionais estão armazenadas na mesma tabela;
Conjuntos de dados (datasets) muitas vezes envolvem valores coletados em diferentes níveis, com diferentes tipos de unidades observacionais. Os dados abaixo mostram dois tipos de unidades observacionais: a música e sua posição no ranking de cada semana.
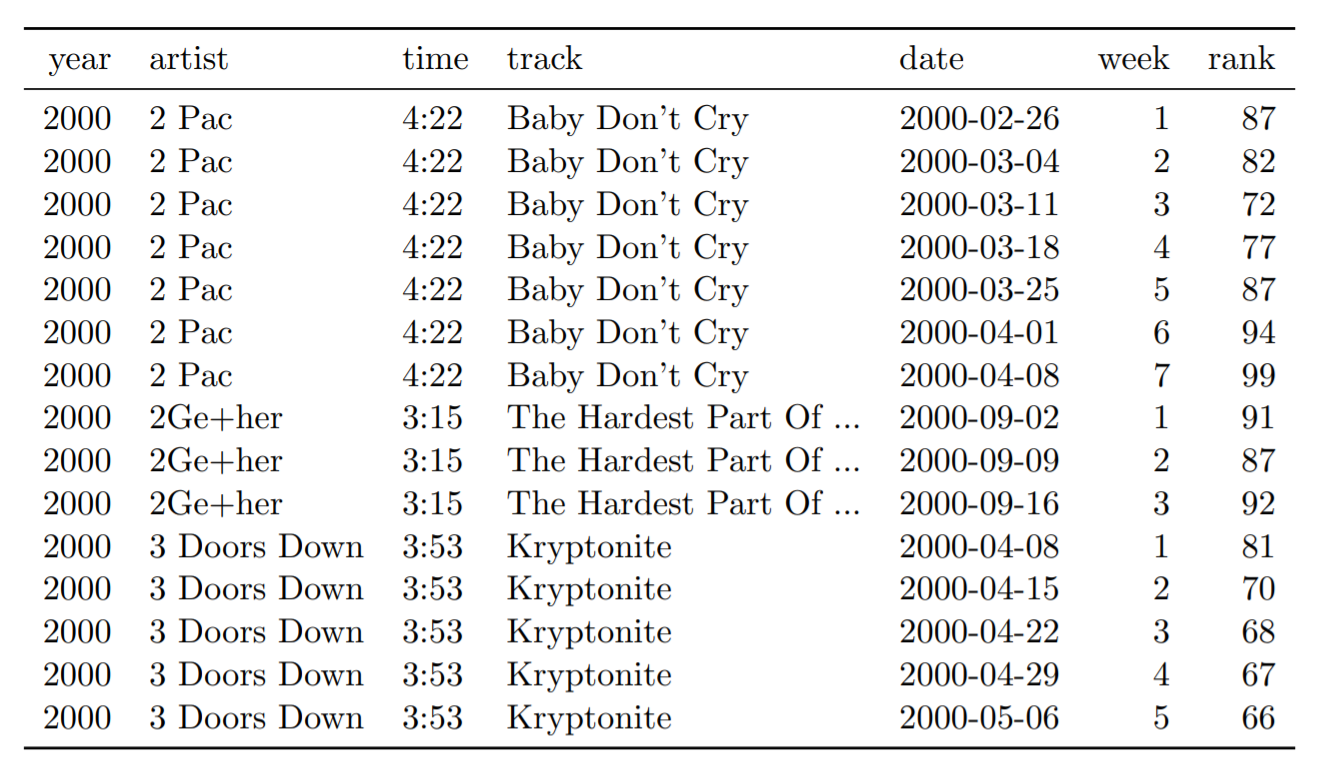
Tabela 8: Primeiras quinze linhas do conjunto de dados organizados do quadro de avisos. A coluna da data não aparece na tabela original, mas pode ser calculada a partir de date.entered e week.
No formato “tidy”, os dados seriam divididos em duas tabelas. Na primeira, temos as informações de cada música, como artista, nome da faixa e duração, além de um identificador único, representado na primeira coluna. Na segunda tabela, ao invés de repetir todas informações de cada música, é inserida apenas o identificador, a data e a posição da música no ranking.
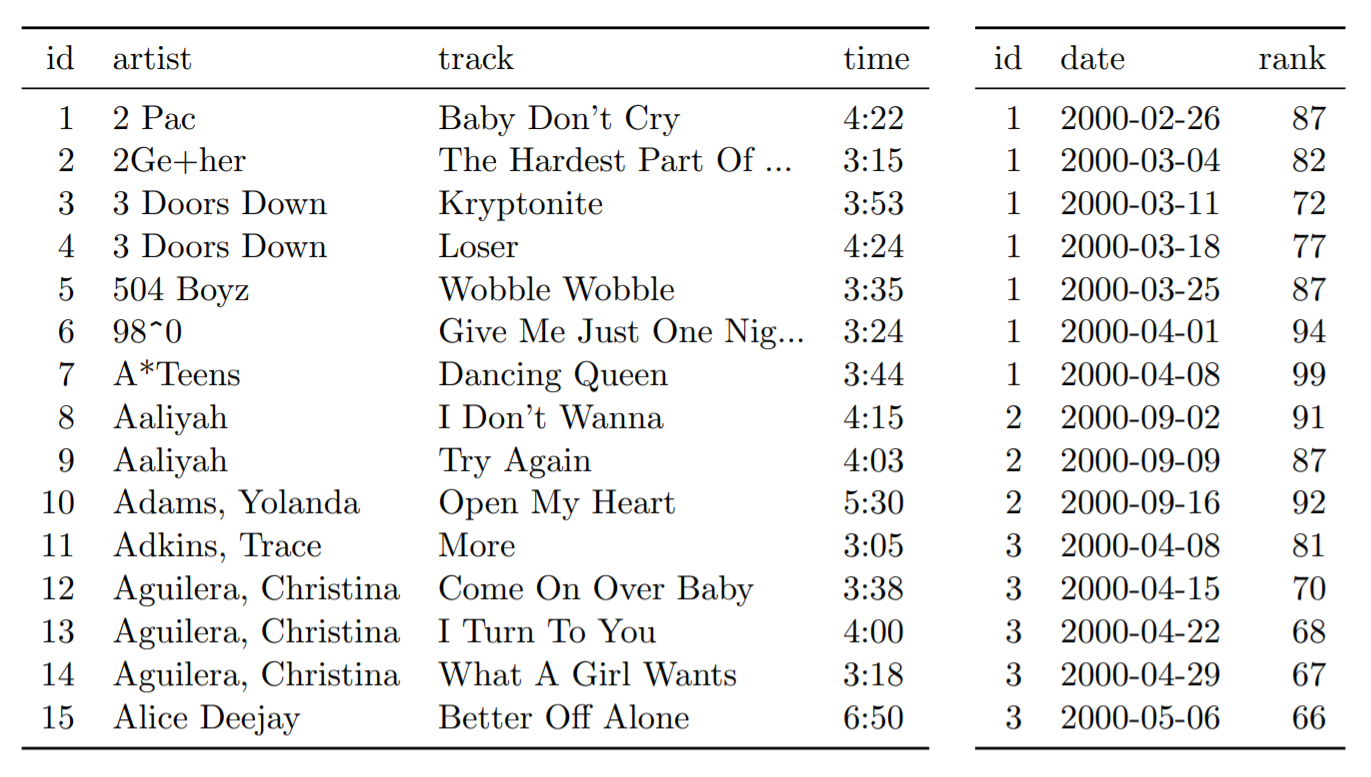
Tabela 13: Conjunto de dados normalizado de outdoors dividido em conjunto de dados de música (esquerda) e conjunto de dados de classificação (direita). Amostra das primeiras 15 linhas de cada conjunto de dados; gênero omitido no conjunto de dados da música, semana omitida no conjunto de dados da classificação.
5. Uma única unidade observacional está armazenada em diferentes tabelas
Também é comum encontrar dados sobre um mesmo tipo de unidade observacional espalhados em múltiplas abas, páginas ou arquivos, que muitas vezes estão separadas por alguma variável. Ou seja, casos onde cada tabela representa um ano, pessoa ou localização. Se o formato for sempre o mesmo, este é um problema fácil de resolver.
- Insira cada arquivo em uma lista de tabelas;
- Para cada uma, adicione uma nova coluna que registra o nome original do arquivo. Isto porque muitas vezes, como dito, o nome do arquivo é uma variável importante.
- Mescle todas tabelas em uma só;
No artigo, Wickham mostra um código em R que realiza esta operação. Nas outras seções do texto, ele apresenta ferramentas para manipulação, visualização e modelagem, além de apresentar um estudo de caso.









Olá, excelente explicação e muito útil. Como sou novo no tema, foi muito esclarecedor. Grato!
Ótimo explicação. Um conceito pouco visto em artigos sobre análise de dados.
Há um bom tempo tenho procurado conteúdo sobre este tema, mas sem sucesso. Felizmente encontrei este artigo. Obrigado pela abordagem clara e objetiva.
Muito bom!
Grato por compartilhar.
Grande artigo para aqueles que já trabalham como analistas de dados, mas não necessariamente têm demanda para mergulhar em estatística e programação.