
(Este é o quarto tutorial de nossa série sobre PDFs. Confira também o primeiro (introdutório), o segundo sobre o Rows e o Tabula e o terceiro que também explora o Tabula via linha de comando)
A primeira coisa a se fazer para libertar dados em PDF é verificar se se seus arquivos são imagens ou não. Se você não consegue selecionar os textos, então, possivelmente está diante de uma imagem e antes de qualquer coisa precisa fazer um reconhecimento ótico de caracteres (o famoso OCR, Optical Character Recognition).
O tesseract-ocr é uma das ferramentas gratuitas e de código-aberto de OCR que mais se destacam. Ela é mantida atualmente pelo Google. Para instalá-lo, seja no Linux, Windows ou Mac OS, confira o passo a passo na wiki do projeto. Ele roda na linha de comando, mas também foram desenvolvidas também diversas interfaces gráficas baseadas neste projeto. Entretanto, mesmo na linha de comando, o funcionamento do Tesseract não é complicado.
Neste tutorial, vamos usar como exemplo esta tabela com a série histórica de vencimentos e salários da Câmara dos Deputados, que foi obtida via Lei de Acesso à Informação. O arquivo está em PDF e tem 36 páginas com muitos, muitos números. Vamos usar o Tesseract e outras ferramentas via linha de comando para transformar alguns dados em textos.
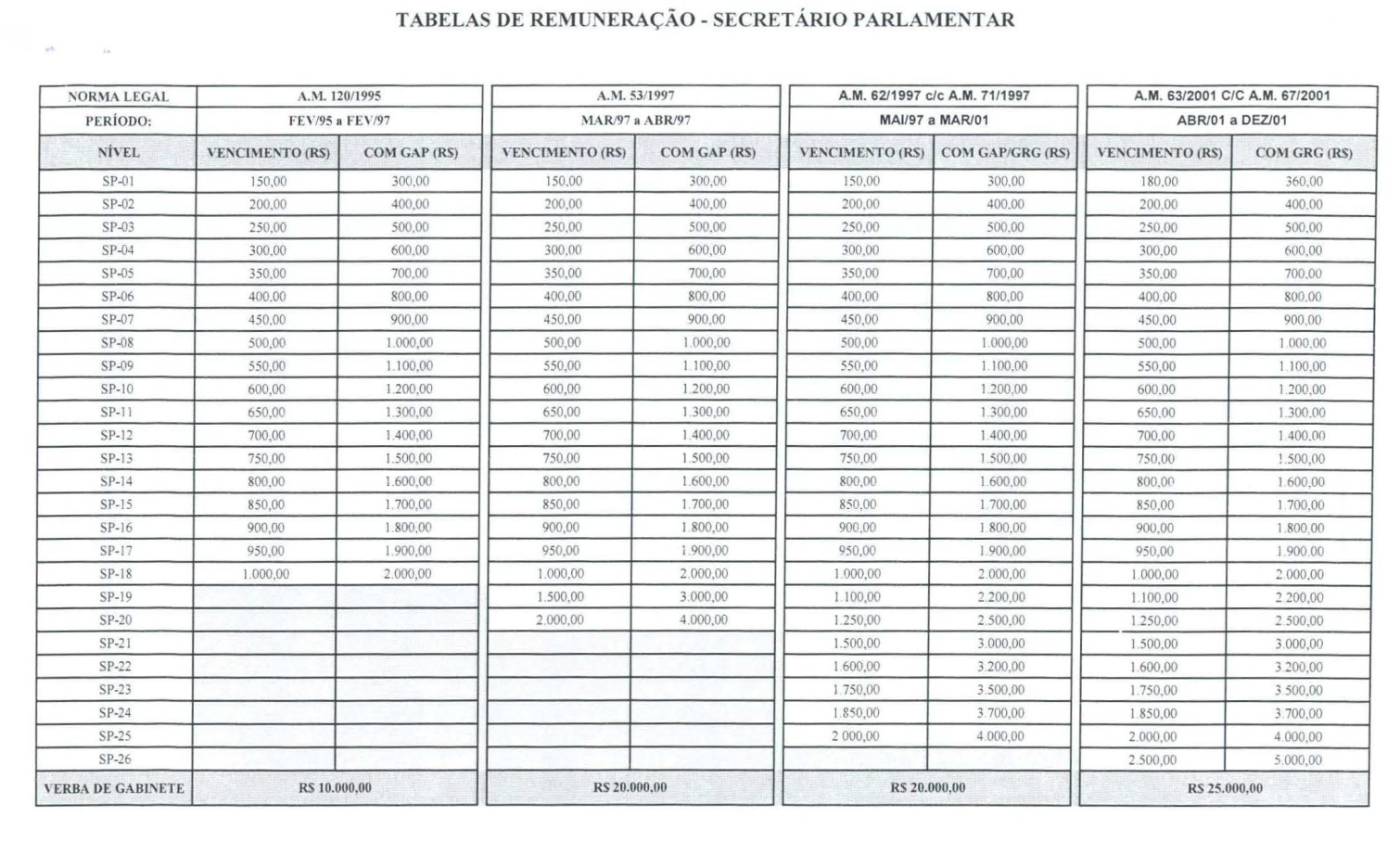
Tabela original, extraída do PDF
Começando os trabalhos
Existem diversos fatores da imagem que podem influenciar o resultado final do OCR: rotação da tabela, ruídos, rabiscos, fontes, imagens de fundo, etc. Por isso, parte importante do trabalho consiste em uma preparação prévia do material.
Nosso PDF de exemplo reúne no mesmo arquivo tabelas com formatos diferentes e inclusive anotações feitas a mão. Obviamente, isto não é nada bom para o Tesseract. Então, primeiro vamos selecionar apenas as tabelas finais do PDF, que possuem um padrão mais uniforme e estão nomeadas como “Tabelas de Remuneração – Secretário Parlamentar”. Elas compreendem as páginas entre a numeração 32 e 36. Existem diversas maneiras de separar páginas específicas de um arquivo PDF. Uma delas é usando o utilitário pdftk, que permite manipular este formato a partir da linha de comando.
Para separar as páginas do PDF com ele, supondo que você já tenha baixado o arquivo e aberto a pasta onde ele se encontra no terminal, bastaria rodar o comando abaixo.
pdftk salarios.pdf cat 32-36 output tabela-assessores.pdf
O que o comando acima fez? Primeiro, chamou o programa (pdftk). Depois, selecionou o arquivo original (salarios.pdf) e a função de concatenação (cat) que por sua vez é sucedida por um intervalo de páginas (32-36). Pronto, agora que já selecionamos o que nos interessa basta especificar no comando que queremos escrever o resultado (output) em um arquivo (tabela-assessores.pdf no caso, mas poderia ser outro nome qualquer).
Transformando o PDF em imagens
Para utilizar o OCR do Tesseract na linha de comando, você precisa transformar seu PDF em um arquivo de imagem. Antes de fazer o reconhecimento de caracteres propriamente, é recomendável deixar a imagem o mais limpa possível, aumentando o contraste e deixando-a em escala de cinza.
Vale a pena conferir o ImageMagick, se você precisa automatizar os ajustes em vários arquivos. Para fazer o pré-processamento de imagens para OCR no nosso exemplo, nós rodamos o seguinte comando:
convert -quality 100 -density 300 -depth 8 -strip -background white -alpha off tabela-assessores.pdf tabela-assessore-img.tiff
Executando a linha acima, acionamos o programa (convert) e definimos uma série de parâmetros. Vejamos um por um:
- -quality 100: definimos a qualidade máxima do arquivo, para que ele não seja comprimido;
- -density 300: definimos uma resolução de 300 dpi;
- -depth 8: número de bits usados para definir a cor de um pixel
- -strip: remove alguns metadados da imagens e outras coisas desimportantes para o OCR;
- -background white: definimos branco como cor de fundo;
- -alpha off: removemos qualquer transparência do arquivo;
Por último, na mesma linha, passamos a ele um arquivo (tabela-assessores.pdf) que ele renomeará e converterá para outro formato (tabela-assessores-img.tiff).
O formato TIFF é especialmente interessante para OCR pois permite separar a imagem em páginas, ao contrário do JPEG ou PNG, por exemplo. Se o arquivo original possuir várias páginas e o formato escolhido for JPEG ou PNG, o programa automaticamente criará vários arquivos de imagens, numerados de acordo com as páginas.
Enfim, convertendo
Vale lembrar que, por ser código-aberto e rodar localmente na sua máquina, o Tesseract pode ser uma boa opção se você precisa fazer OCR com um volume muito grande de arquivos. Se você tiver instalado arquivos de línguas no seu tesseract – consulte a documentação da wiki para saber como – você pode colocar a opção -l por, para indicar que o documento está em português e melhorar o reconhecimento dos caracteres.
Um parâmetro importante no Tesseract é o modelo de segmentação de página (page segmentation model, abreviado para psm), que define para o programa qual o layout da página. No manual do Tesseract, há uma lista com todos estes modelos.
Caso você não declare explicitamente qual modelo quer usar, o Tesseract usará o número 3 (“Fully automatic page segmentation, but no OSD – Orientation and script detection”). Mas o modelo mais adequado vai depender do seu documento. Se você está lidando com tabelas, pode experimentar, por exemplo o número 6 (“Assume a single uniform block of text”).
tesseract tabela-assessores-img.tiff tabela-assessores -l por -psm 6
No comando acima, executamos o Tesseract passando para ele um arquivo de imagem (tabela-assessores-img.tiff). O texto seguinte, “resultado-assessores”, é o “nome base” que nomeará os arquivos em texto que serão gerado. A extensão “txt” é adicionada automaticamente, então não precisa ser declarada. Por último, definimos o idioma (language) com o “-l por”. E declaramos o modelo de segmentação de página que queremos, com o “-psm 6”.
Os resultados nem sempre são animadores. Portanto, a checagem dos resultados é obrigatória e, provavelmente, você ainda precisará fazer edições, correções ou inserções manuais.
No nosso caso, o arquivo final de texto reconheceu boa parte dos números de forma satisfatória, mas entre as transcrições da tabelas há enormes espaços em branco. Então, para utilizar efetivamente os dados ali, precisaríamos ainda de um trabalho extra com estruturação e limpeza da sequência de texto reconhecida pelo Tesseract.
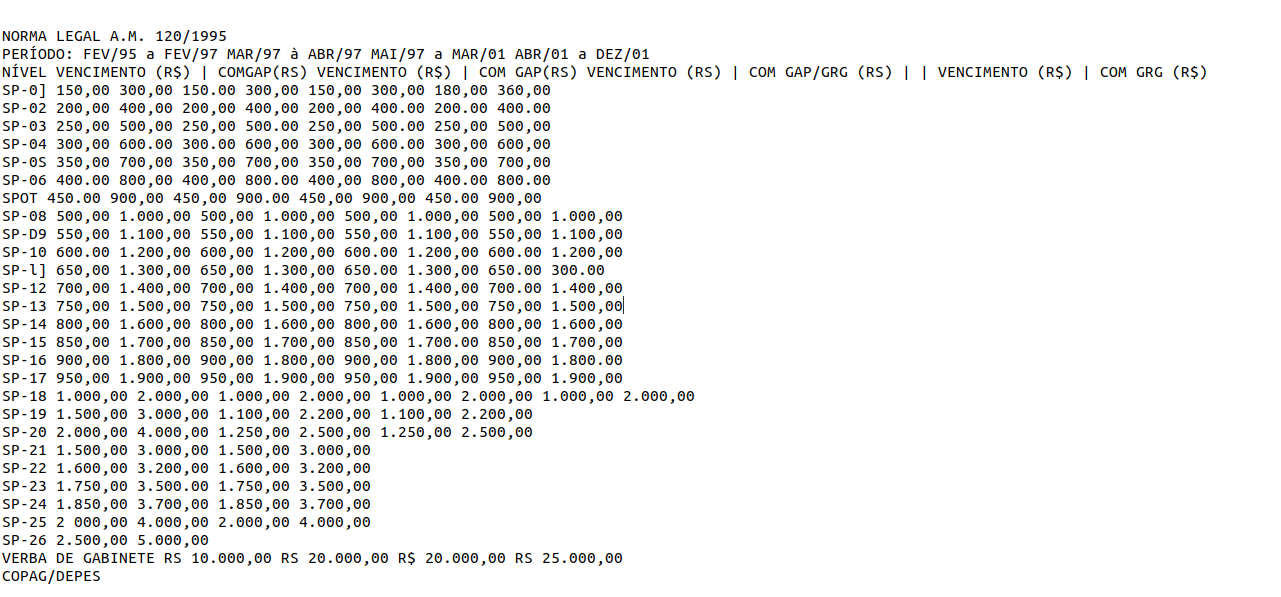
Captura de tela do texto transcrito pelo Tesseract, aberto no bloco de notas
Saiba mais
A eficácia do OCR é bastante afetada pela qualidade de imagem. Então, não é demais reforçar: dependendo do seu PDF, talvez valha a pena pré-processar a imagem – você pode seguir estas dicas do próprio Tesseract, por exemplo. Isso faz uma super diferença especialmente se sua imagem está “suja” ou com pouco contraste, por exemplo.
Se você necessita dos seus dados de forma tabular, então ainda será necessário transformar o arquivo em texto em uma formato do tipo, como o CSV. Neste ponto, a solução depende do quão precisa foi a “transcrição” feita. Se há algum padrão muito bem delimitado, você pode tentar parsear com expressão regular ou tentar importá-lo como um tabela usando delimitadores de largura fixa. O Tesseract pode também exportar os resultados usando o formato TSV, porém, nos testes que realizamos com o exemplo acima, a leitura dos dados usando esta opção de exportação teve desempenho significativamente pior.
Além disso, você pode treinar seu Tesseract para melhor a performance do software, caso esteja sofrendo com a “transcrição” feita pelo problema. Outra solução de código-aberto que funciona de forma semelhante é o OCROpus, Kraken e o Calamari, baseado na biblioteca de aprendizado de máquina conhecida como Tensor Flow.
O Google também oferece serviços de OCR, como o Google Cloud Vision e o próprio Drive permite converter online PDFs ou imagens para texto de forma simples. Porém, esta solução pode não ser muito eficiente se você quer tabelas como o resultado final. Já outros serviços comerciais fazem um bom trabalho neste quesito. Existem diversas opções pagas para transformar PDF em tabelas (como a da Adobe, Microsoft e Abby), que não abordamos neste post.
Se você precisa converter pontualmente apenas algumas poucas tabelas que foram escaneadas, o Abby é uma boa opção que traz ótimos resultados, mesmo na versão gratuita. Recentemente, o Excel também anunciou uma função de OCR na sua versão para Android. A vantagem é que você também não precisa se preocupar em parsear os dados ou estruturá-los como tabela, já que estes programa já o convertem diretamente para formatos tabulares.
Em uma pesquisa, foi feita uma comparação de soluções OCR, testando os softwares do Tesseract, Abbyy e Google Docs. A conclusão? Abby e Google Docs apresentaram resultados melhores na hora de transformar uma imagem em texto.
Outro artigo – publicado no site Source da Open News – também comparou diversos softwares de OCR e publicou os resultados obtidos com cada um. A conclusão foi que o resultado depende muito do estado do documento. Se ele estiver bem limpo e legível, a maioria dos softwares se sai bem. Já com imagens mais enganosas, com rasuras por exemplo, nenhum teve resultados perfeitos. No fim das contas, na maioria dos casos, como dito, você precisará fazer uma revisão.
Give Me Text e DocumentCloud
A Open Knowledge Internacional oferece acesso às funcionalidades do Tesseract (com foco no suporte aos idiomas inglês e alemão) de forma online, através do Give Me Text – mas o serviço, como o nome indica, te retorna textos, não tabelas, sendo necessário ainda um trabalho adicional, neste caso. O serviço pode ser usado manualmente ou via API: ele recebe um arquivo do PDF e, como o nome indica, te dá o texto que ali está. É possível também usar o serviço pela linha de comando, com o curl, por exemplo.
Já se você precisa não só fazer OCR em diversos documentos, como também ter uma plataforma simples para uma equipe realizar buscas e anotações, então, provavelmente o DocumentCloud será a opção de código-aberto mais robusta para sua necessidade. O software tem ainda funcionalidades extras, como reconhecimento automático de nomes e outros tipos de processamento do conteúdo.
E você?
Sabe alguma dica ou ferramenta que não cobrimos neste tutorial? Possui sugestões ou dúvidas sobre o uso do Tesseract? Deixa seu comentário aqui e compartilha com a gente.









Maravilha de artigo!! Obrigado!
Muito bom e esclarecedor este tutorial.
Segui o tutorial, mas não obtive o mesmo resultado. Para o comando de conversão funcionar (tesseract tabela-assessores-img.tiff tabela-assessores -l por -psm 6), tive que instalar também o pacote de língua portuguesa (o tesseract-ocr-por) e acrescentar mais um tracinho (sinal de menos) antes do argumento psm.
Mas o artigo é excelente!
Valeu por compartilhar!