
Estratégias para uma visualização de dados efetiva
Por Dipanjan Sarkar, publicado originalmente no canal The Startup.
Tradução de Cássia Sampaio
| O texto original foi separado em três seções. O post abaixo traz a parte I. – Parte I – Introdução à gramática dos gráficos; Parte II – Análise multivariada e visualização de dados multidimensionais (publicada neste notebook); Parte III – Visualizando dados não estruturados e conclusão; |
Introdução
A análise descritiva é um dos componentes essenciais de qualquer análise do ciclo de vida de um projeto de ciência de dados ou mesmo de uma pesquisa específica. Agregação, sumarização e visualização de dados são alguns dos principais pilares que sustentam a área de análise de dados. Desde os dias do tradicional B.I. (Business Intelligence), e mesmo nesta era da Inteligência Artificial, a Visualização de Dados tem sido uma ferramenta poderosa, amplamente adotada pelas organizações devido à sua eficácia em abstrair a informação correta, entendendo e interpretando resultados de forma clara e fácil.
No entanto, lidar com datasets (conjuntos de dados multidimensionais com mais de dois atributos ou features) começa a nos causar problemas, uma vez que nosso meio de análise e comunicação de dados é tipicamente restrito a duas dimensões. Eu escrevi alguns textos populares sobre visualização de dados eficaz no passado e também falei sobre isso em conferências. Este artigo será uma compilação da minha experiência até agora em lidar com dados estruturados e não estruturados!
Neste artigo, iremos explorar os seguintes aspectos:
- A Gramática dos Gráficos.
- Estratégias efetivas de visualização de dados multidimensionais estruturados (variando de 1-D até 6-D).
- Algo breve sobre a visualização de dados não estruturados, incluindo texto, imagens e áudio.
Os exemplos serão mostrados em Python, no entanto, se for do seu interesse, você pode replicá-los em R ou em qualquer outra linguagem de sua escolha.
Motivação
A visualização de dados e o storytelling sempre foram uma das fases mais importantes de qualquer fluxo de trabalho (pipeline) de ciência de dados envolvendo a extração de insights significativos dos dados, independentemente da complexidade desses dados ou do projeto.
Repare em um exemplo simples de ‘Datasaurus Dozen’ (Dúzia do Datassauro) – doze diferentes datasets retratados na figura a seguir.
Você consegue adivinhar o que é comum entre esses datasets aparentemente muito diferentes?

The Datasaurus Dozen — O que é comum entre esses datasets diversos?
Resposta: O sumário estatístico de todos os datasets é exatamente o mesmo!

Esta é uma variante divertida do conhecido quarteto de Anscombe, com o qual muitos de vocês podem estar bastante familiarizados, como ilustrado na figura a seguir.
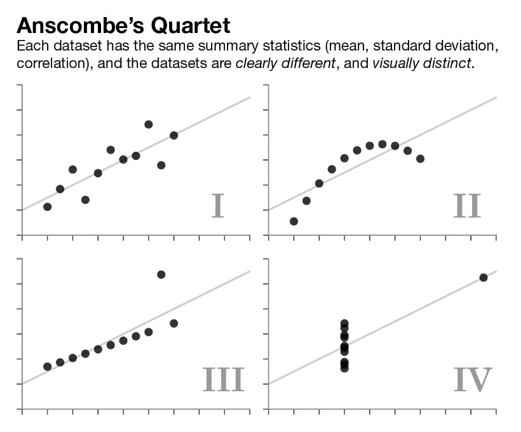
Quarteto de Anscombe – Os conjuntos de dados acima possuem as mesmas estatísticas descritivas (média, desvio padrão, correlação) e os dataset são claramente diferentes e visualmente distintos.
O ponto mais importante dessas demonstrações seria: “não confie cegamente em seus dados a ponto de começar imediatamente a modelá-los”. O sumário estatístico sempre pode ser enganoso. Sempre visualize e compreenda seus dados antes de passar para a “feature engineering” (engenharia de características) e a construção de modelos estatísticos de aprendizado de máquina (machine learning) ou de aprendizagem profunda (deep learning).
Outra fonte muito importante de motivação, particularmente para uma visualização de dados eficaz, pode ser derivada de alguns excelentes casos de estudo que datam de vários séculos atrás quando não tínhamos nem computadores, muito menos Python ou R! O primeiro é a famosa visualização do John Snow que descreve a epidemia do cólera na Broad Street em Londres, Inglaterra, em 1854!
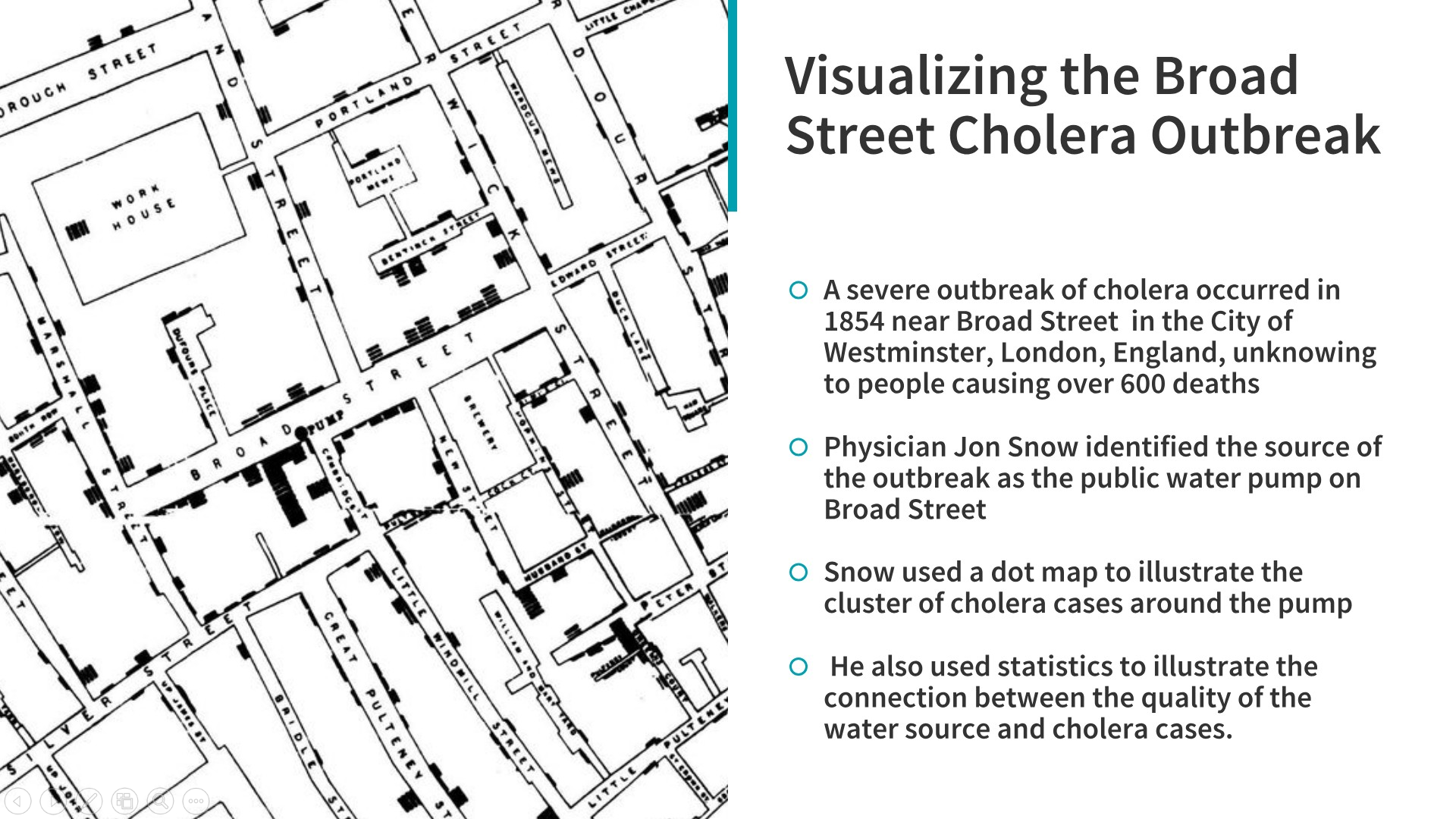
Visualizando a epidemia do cólera na Broad Street, que ajudou a encontrar a causa raiz da explosão da doença! – 1) Uma grave e desconhecida epidemia de cólera ocorreu em 1854 próximo da Broad Street, na cidade de Westminster, em Londres, na Inglaterra, causando mais de 600 mortes; 2) O médico Jon Snow identificou a origem da epidemia em uma bomba de água na Broad Street; 3) Snow usou pontos em um mapa para ilustrar o conjunto (cluster) de casos cólera perto da bomba; 4) Ele também usou estatística para ilsutra a conexão entre a qualidade da fonte de água e os casos de cólera (Fonte: https://github.com/dipanjanS/art_of_data_visualization)
Você pode ver como uma simples visualização desenhada à mão ajudou a encontrar a causa raiz da epidemia do cólera na Broad Street nos anos 1850. Outra visualização interessante foi construída por Florence Nightingale, a mãe da moderna prática de enfermagem, que tinha um interesse profundo em enfermagem e estatística.
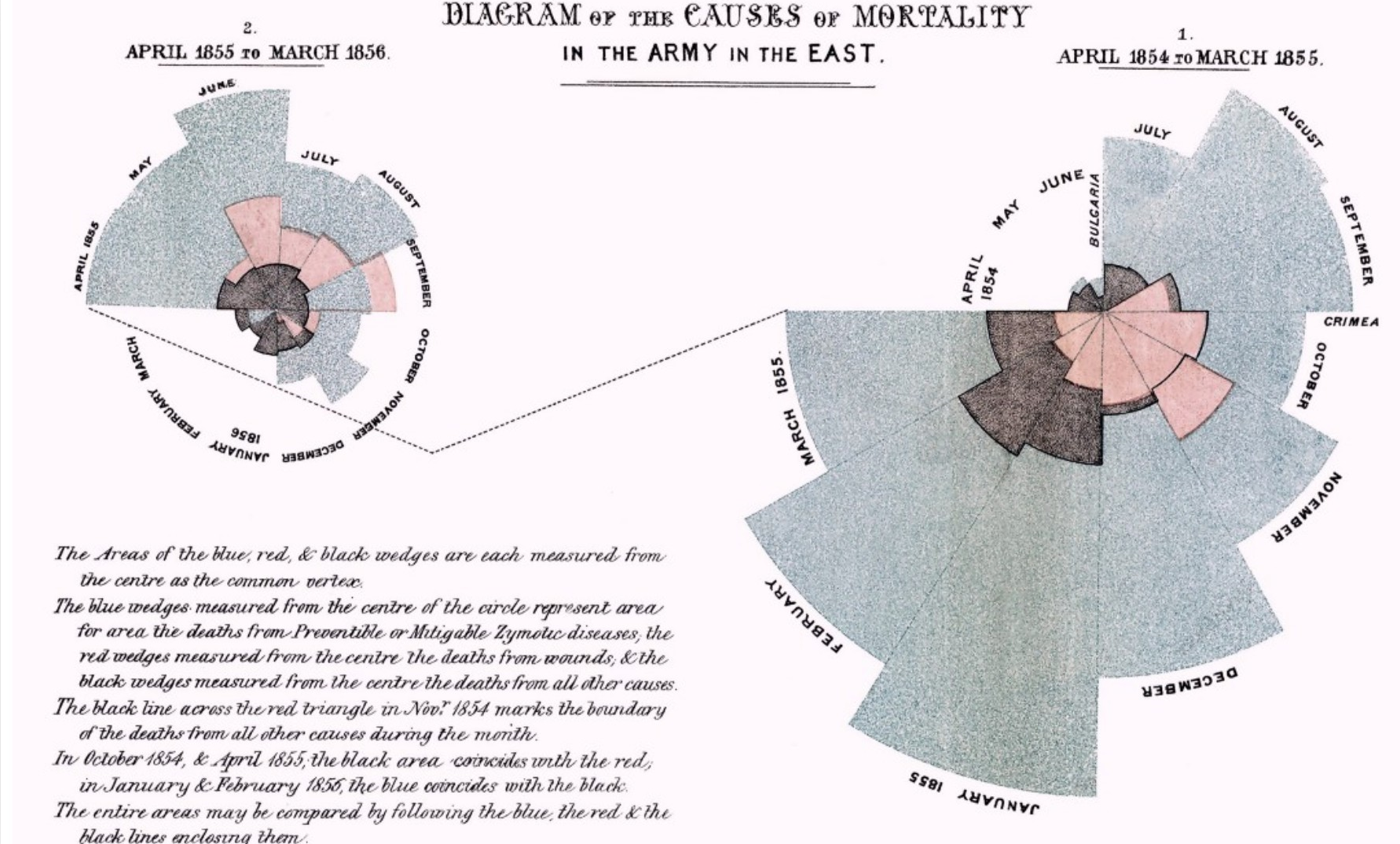
Causas da Mortalidade no Exército do Leste – Florence Nightingale (Fonte: https://github.com/dipanjanS/art_of_data_visualization)
A figura acima exibe um diagrama de área polar que descreve as causas de mortalidade (por morte) no exército na década de 1850. Podemos ver que a visualização definitivamente não é simplista, ainda assim transmite os insights corretos – mostrando claramente a proporção de soldados que morreram devido a doenças evitáveis, com base em ferimentos ou outras causas. Isso deve servir como motivação suficiente para uma visualização de dados eficaz!
Uma atualização rápida na visualização
Estou assumindo que quem está lendo esse texto já lê sobre o tema conhece os gráficos essenciais usados para visualizar dados, portanto, não vou entrar em explicações detalhadas, mas iremos cobrir a maior parte deles durante nossos experimentos práticos aqui. A visualização de dados deve ser aproveita para comunicar padrões e insights com ‘clareza, precisão e eficiência’, como mencionado pelo notável pioneiro da visualização e estatístico, Edward Tufte.
Iremos usar o ecossistema de aprendizado de máquina em Python aqui e recomendamos que você verifique os frameworks para análise e visualização de dados como pandas, matplotlib, seaborn, plotly e bokeh. Além disso, conhecer D3.js também é uma necessidade se você se interessar em criar visualizações bonitas e com significado usando dados. Recomendo a quem tiver interesse que leia “The Visual Display of Quantitative Information” (livro disponível apenas em inglês), de Edward Tufte.
Entendendo a gramática dos gráficos
Para entender a gramática dos gráficos, precisamos antes compreender o que entendemos por gramática. A figura a seguir resume brevemente esses dois aspectos.

Visualização efetiva com a gramática dos gráficos: 1) Gramática é definido como um conjunto de regras estruturais que ajudam a definir e estabelecer componentes de uma linguagem; 2) Todo sistema e estrutura de uma linguagem usualmente consiste em sintaxe e semântica; 3) Uma gramática dos gráficos é um framework que nos permite descrever de forma concisa os componentes de qualquer gráfico; 4) Ao invés de tentativas e erros aleatórias, siga uma abordagem em camadas, usando componentes definidos para a visualização (Fonte: https://github.com/dipanjanS art_of_data_visualization)
Basicamente, uma gramática de gráficos é um framework que segue uma abordagem em camadas para descrever e construir visualizações ou gráficos de uma maneira estruturada. Uma visualização envolvendo dados multidimensionais geralmente tem múltiplos componentes ou aspectos e usar essa gramática de gráficos em camadas nos ajuda a descrever e entender cada um dos componentes envolvidos na visualização – em termos de dados, estética, escala, objetos e assim por diante.
O framework original da gramática de gráficos foi proposto por Leland Wilkinson, e aborda em detalhes todos os principais aspectos relativos à uma visualização de dados eficaz. Eu recomendaria definitivamente a quem tem interesse que verifique o livro caso tenha uma chance!
The Grammar of Graphics | Leland Wilkinson | Springer
No entanto, iremos usar uma alternativa a esse framework – conhecido como o framework da gramática de gráficos em camadas, que foi proposto por Hadley Wickham renomado cientista de dados e criador do famoso pacote de visualização ggplot2 do R. É uma boa ideia conferir seu artigo intitulado “Uma gramática de gráficos em camadas” (“A layered grammar of graphics“) que aborda detalhadamente sua proposta de uma gramática de gráficos em camadas e também fala sobre seu framework de implementação open-source, ggplot2, que foi construído para a linguagem de programação R.
Eu identifiquei sete componentes principais que geralmente me ajudam a construir visualizações efetivas com dados multidimensionais. A figura a seguir ilustra isso com alguns detalhes sobre cada componente específico na gramática.

Principais componentes da gramática de gráficos: de cima para baixo, sistema de coordenadas (cartesiana, polar?); facetas (crie subgráficos baseados em diversas dimensões); estatística (média, quartil, intervalo de confiança?); objetos geométricos (barras, linhas, pontos?); escala (valores de escala, representa valores mútiplos?); estética (eixos, posição dos gráficos, codificações); dados (nossos datasets) (Fonte: https://github.com/dipanjanS/art_of_data_visualization)
Ilustramos esses componentes usando uma arquitetura de pirâmide que denota uma hierarquia inerente de componentes em camadas. Normalmente, para construir ou descrever qualquer visualização com uma ou mais dimensões, podemos usar os componentes da seguinte maneira.
- Dados: Sempre comece com os dados, identifique as dimensões que você deseja visualizar.
- Estética: Confirme os eixos com base nas dimensões dos dados e as posições dos pontos no gráfico. Verifique também se é necessária alguma forma de encoding (codificação) de caracteres, incluindo tamanho, forma, cor e assim por diante, o que é útil para plotar múltiplas dimensões de dados.
- Escala: Precisamos escalar potenciais valores, usar uma escala específica para representar diversos valores ou um intervalo?
- Objetos geométricos: são conhecidos popularmente como ‘geoms’. Isso cobriria a maneira como descreveríamos os pontos de dados na visualização. Ele deveriam ser pontos, barras, linhas etc?
- Estatísticas: Precisamos mostrar algumas medidas estatísticas na visualização como medidas de tendência central, dispersão e intervalos de confiança?
- Facetas: precisamos criar subplots (diversos gráficos menores) com base em dimensões específicas dos dados?
- Sistema de coordenadas: Em que tipo de sistema de coordenadas a visualização deveria se basear – cartesiana ou polar?
Na sequência, veremos como aproveitar essa estrutura em camadas para criar visualizações eficazes para dados multidimensionais com alguns exemplos práticos.
Confira aqui o notebook com a segunda parte do tutorial.









Estou realmente encantado com esse material e a forma de apresentar contexto.