
Muitas vezes o acesso aos dados não é fácil. Por mais que a gente desejasse que tudo estivesse disponível em CSV ou no formato da nossa preferência, dados são divulgados de forma diferente na internet. E se você quiser combiná-los com outros dados ou explorá-los de maneira independente? Raspagem neles! Raspagem de dados é como se chama o método para extrair os dados escondidos em documentos como páginas da web e PDFs e torná-los usáveis, possíveis de serem processados.
A raspagem de dados é uma das habilidades mais úteis se você vai investigar dados, e na maioria da vezes não é algo muito difícil. Para raspadores mais simples, você não precisa saber escrever códigos. Nesse tutorial vamos mostrar como raspar dados usando três ferramentas: o Google Sheets, o IFTTT e uma extensão do navegador Chrome/Chromium chamada Web Scraper.
Como raspar dados usando o Google Sheets
Vamos usar a seguinte fórmula do Google Sheets para raspar tabelas ou listas em páginas da web: =importHTML(“”; “table”; N)
Observação: os parâmetros são separados por “ponto e vírgula” se a sua planilha no Google Sheets estiver configurada para o Brasil. Caso contrário, o separador pode ser a vírgula. Clique em “Arquivo” e depois em “Configurações de planilha…” para conferir essas opções.
Os dois primeiros parâmetros precisam estar entre aspas. O primeiro é o endereço da página. O segundo é “table” (tabela) ou “list” (lista), dependendo do que você está querendo raspar. O terceiro é um número, começando do 1, que identifica a enésima tabela ou lista na página que você está tentando raspar.Vamos ver como funciona na prática.
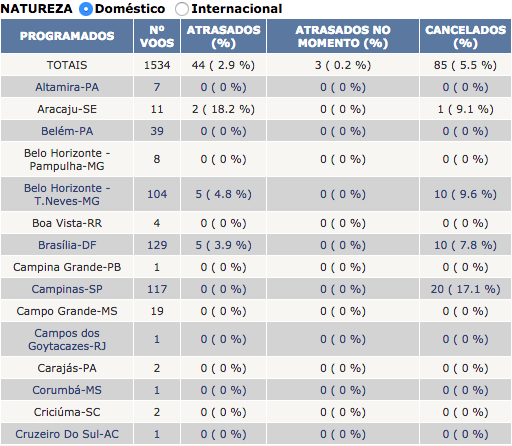
Para raspar os dados mais atualizados da Infraero em relação aos voos atrasados ou cancelados no Brasil, tiramos as informações dessa tabela aqui:
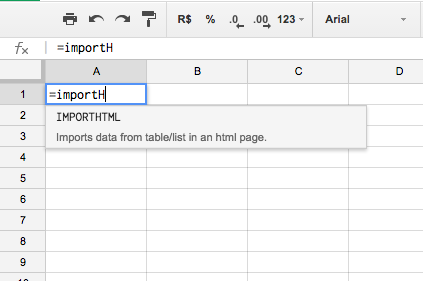
Crie uma tabela em branco no Google Sheets e comece a digitar =importHTML na primeira célula. Veja que você vai digitando a fórmula e o Sheets já autocompleta para você.
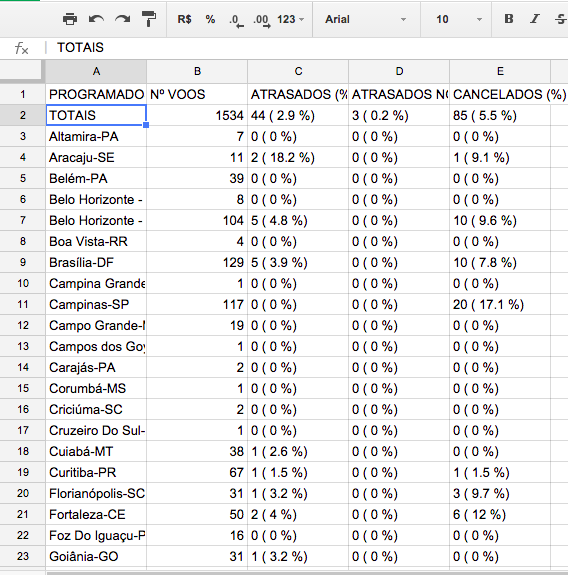
Finalize o comando colocando o endereço da página, e os outros parâmetros, assim:
=importHTML("http://voos.infraero.gov.br/hstvoos/RelatorioPortal.aspx"; "table"; 1)

Espere um pouco e os dados serão carregados para sua planilha!
Se os dados na tabela no site da Infraero forem atualizados, os dados na sua planilha também serão toda vez que você recarregar a página ou executar a fórmula na planilha de novo.
Saber a estrutura de um site é o primeiro passo para extrair e usar os dados. Vamos colocar os nossos dados em uma planilha. Um modo fácil de fazer isso nos é proporcionado por uma fórmula especial do Google Spreadsheets. Economize horas de agonia de copia-e-cola com a função =importHTML() no Google Sheets.
Raspando dados com o IFTTT
O IFTTT é um serviço que reúne uma série de ferramentas e redes sociais na web. Nele é possível conectar coisas como sua conta de email e até a Nasa: toda vez que a agência espacial americana publicar a foto astronômica do dia, você recebe a foto por email. Ou então, conectar algum serviço de notícia com seus favoritos: quando uma reportagem sobre, digamos, saúde, for publicada pelo The New York Times, o artigo é salvo automaticamente na sua lista de leitura. Parece confuso? É o site mais legal da web! Pense nele como um robô que conecta um determinado serviço a outro e executa automaticamente o que você configurar, baseado em algumas condições.
IFTTT é uma sigla em inglês que significa If This, Than That ou seja, “Se isso, então aquilo”. O nome já diz muita coisa sobre o funcionamento do IFTTT: “Se isso acontecer, então outra coisa deve acontecer em seguida”. Nesse guia vamos mostrar como raspar dados do Instagram usando o IFTTT e guardá-los em uma planilha do Google Sheets. Sempre que alguém postar uma foto no serviço e ela se encaixar no seu parâmetro de busca, as informações sobre a postagem, incluindo a foto, serão salvas automaticamente na planilha. Demais, não é mesmo?
Vá até o site do IFTTT e crie uma conta. Clique no botão azul no centro da tela. Basta digitar seu email e uma senha. Você vai receber um email de confirmação. Clique no botão azul e sua conta estará confirmada.

Página inicial do IFTTT, a página mais legal da Web
Voltando à tela inicial do IFTTT ele vai te mostrar algumas “receitas”… que é o nome que a ferramenta dá para algum procedimento que conecta dois serviços.
As receitas do IFTTT são rotinas prontas para realizar uma série de tarefas legais!
Clique em Channels e digite “instagram” na caixa de procura. Clique no ícone do instagram e no botão azul escrito “connect”. Você vai precisar colocar suas credenciais do instagram. Uma mensagem verde vai confirmar que sua conta está habilitada para ser usada com o IFTTT. Clique em Channels novamente e conecte o canal do Google Drive, que é o canal que permite a criação e manipulação de planilhas do Google Sheets. Digite Google Drive na caixa de busca e conecte o canal do Google Drive. Você vai precisar colocar suas credenciais da sua conta Google. A mesma coisa pode ser feita com o Twitter ou qualquer outro serviço que você queira conectar.
A barra de procura permite encontrar diversos canais no IFTTT
Agora, clique em My Recipes. Clique no botão azul (Create a Recipe) e vamos escolher o nosso primeiro serviço: o Instagram.
Clique no botão azul para criar sua primeira receita!
A ideia desse raspador é capturar as informações dos posts de Instagram (inclusive as fotos) tiradas em um local específico. Ou seja, toda vez que alguém tirar uma foto cujas coordenadas geográficas coincidam com a nossa escolha, as informações vão direto para uma nova linha em uma planilha do Google. Primeiro, clique na palavra this, em azul e digite “instagram”. Selecione o canal.
Selecione o canal Instagram usando a barra de procura
Agora vamos escolher um “gatilho”, que é um evento que precisa acontecer no Instagram para ativar o próximo passo, a ação. Nesse caso, precisamos do gatilho New photo by anyone in area, que significa: “Nova foto tirada por qualquer pessoa em uma área”.
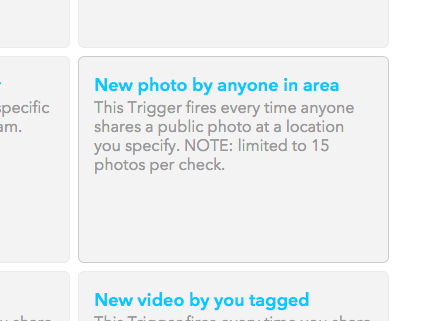
Selecione o gatilho: “New photo by anyone in area”
Agora, escolhemos a região geográfica de interesse. Podemos procurar usando a busca ou navegar pelo mapa usando a interface gráfica. Esse raspador vai capturar fotos tiradas próximas ao Mineirão, o maior estádio de futebol dos mineiros. Podemos ajustar aqui o tamanho da área de captura. Lembrando que todas as fotos do Instagram que forem postadas dentro dessa região demarcada farão parte da busca.
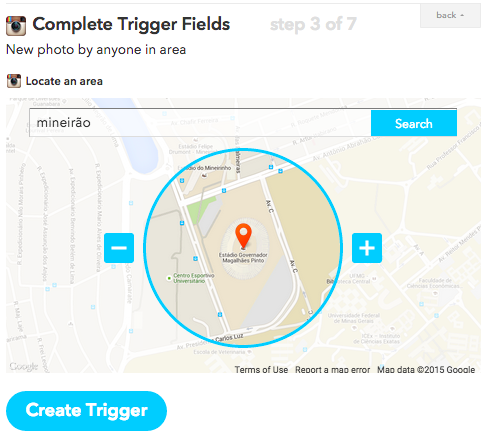
Digite alguma localidade na barra de busca. Nesse exemplo procuramos por “Mineirão”
Duas observações importantes: Fotos que forem tiradas em perfis privados, ou seja, que precisam de autorização do autor para serem vistos, não aparecerão nessa busca. A outra coisa é que há um limite de resultados que o Instagram entrega para o IFTTT cada vez que a busca é realizada. O limite é de 15 fotos cada vez que o IFTTT faz a busca. Clique em Create Trigger.
Pronto. Agora que o IFTTT vai separar para gente todas as fotos tiradas na região do Mineirão, vamos dizer para ele o que precisa ser feito com essas fotos. Vamos conectar o canal do Google Drive para que os dados sejam salvos em uma planilha do Google Sheets. Clique em that e digite Google Drive. Selecione o canal.
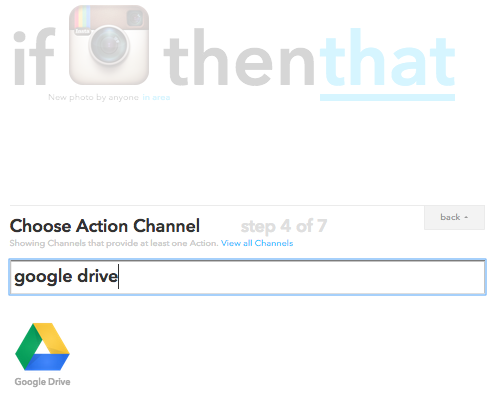
Selecione o canal que vai executar a ação da sua receita. Nesse caso, o Google Drive!
Agora vamos escolher uma ação que vai ocorrer toda vez que o IFTTT encontrar fotos no Instagram que foram tiradas na região do Mineirão. Escolha a ação Add row to spreasheet, que significa “acrescentar linha à planilha”. A observação aqui é que uma nova planilha será criada depois que 2000 linhas forem adicionadas.
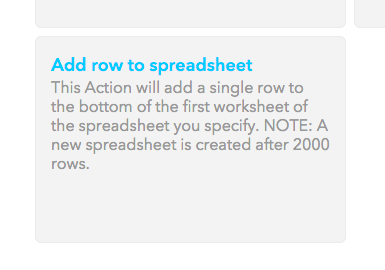
Selecione essa opção para que os posts do Instagram sejam salvos em uma nova planilha do Google
Vamos dar um nome para nossa planilha e escolher quais dados queremos incluir nela. Se você clicar no ícone azul, você vai ver a lista de dados que o Instagram permite incluir: a legenda da foto, o link para o post na página do Instagram, o link para a foto, o nome do usuário, informações sobre a geolocalização, a hora de criação e o código HTML para colocar o post em outras páginas da web.
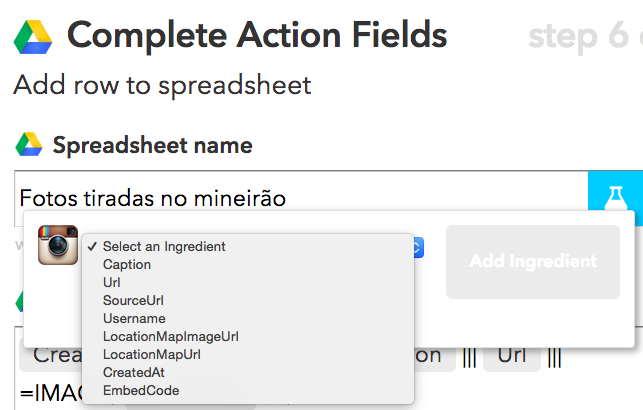
Dê um nome para sua planilha e veja a lista de ingredientes possíveis de serem adicionados a essa receita clicando no ícone azul
Por padrão, o IFTTT incluiu para gente as seguintes colunas: data de criação, nome de usuário, legenda, link para o post e a imagem. Cada coluna é separada por três “pipes”, o nome desse caractere que se parece com uma barrinha. Você pode criar mais colunas e acrescentar outros dados se quiser. Vamos incluir o link direto para imagem, pois isso pode servir para fazer uma galeria de fotos depois. Basta digitar os três “pipes” e selecionar SourceUrl.
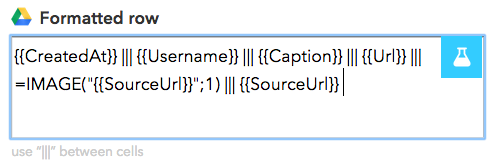
Digite “|||” para adicionar uma nova coluna à sua planilha!
Por último escolhemos onde a planilha será salva no nosso Google Drive. Do jeito que está ela vai ser salva na pasta Instagram, que está dentro de outra pasta, chamada IFTTT, na raíz do Google Drive. Agora é só clicar no botão azul Create Action e dar um nome para sua receita.
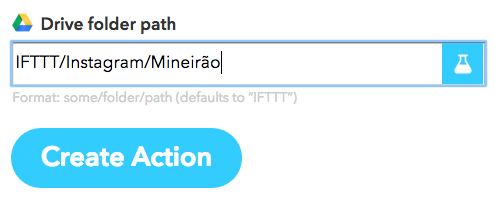
Selecione em qual pasta no seu Google Drive a planilha será salva. É só digitar o caminho, mesmo que a pasta não exista
Clique em Create Recipe para criar e ativar a receita. Agora é só aguardar que sua planilha será criada no Google Drive e os dados serão incluídos automaticamente por tempo indeterminado! Sensacional!
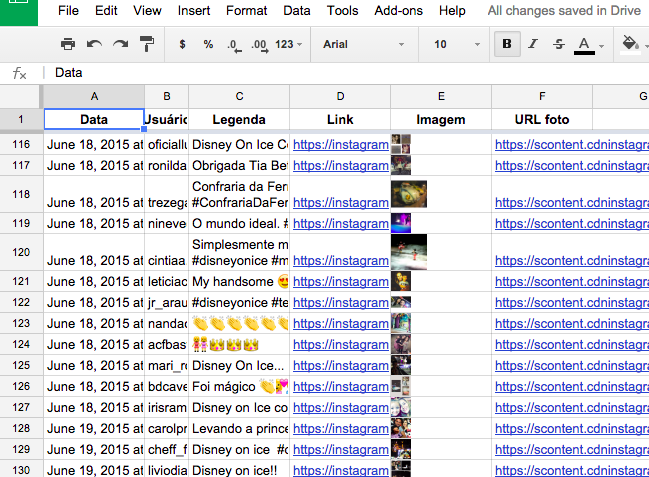
Os dados são salvos na planilha do Google automaticamente! \o/
Veja que a planilha exibe as informações que queríamos: a data, o nome do usuário, a legenda da foto e todo o resto. Agora você pode começar a analisar essa planilha e procurar por padrões, como objetos fotografados, se houve algum usuário que postou mais fotos, quais #hashtags foram as mais usadas ou se há algum assunto recorrente nas postagens.
Tente criar uma receita semelhante, mas com o canal do Twitter. Procure por tweets postados a partir de um lugar específico, ou a partir de uma busca de hashtag ou palavra!
Crie robôs de raspagem com o Web Scraper!
Vamos ver agora como fazer raspagens mais elaboradas usando uma extensão do Chrome chamada Web Scraper. As rotinas que vimos anteriormente usam ferramentas que não dependem muito da estrutura das páginas. O Google Sheets raspa tabelas e listas e o IFTTT conecta serviços, contornando completamente o acesso às páginas.
Agora, com o Web Scraper, vamos poder raspar mais páginas da internet, sem depender, por exemplo, dos serviços conectados do IFTTT ou de tabelas ou listas incluídas na função importHTML() do Google Sheets.
A primeira coisa que vamos fazer é instalar a extensão Web Scraper para funcionar no seu navegador Chrome. Essa extensão não está disponível ainda para outros navegadores.
Clique no botão verde para instalar o Web Scraper no seu Chrome/Chromium
Clique no botão verde para adicionar a extensão ao Chrome. Você vai ver que um ícone de teia de aranha aparece do lado da barra de endereços.
Esse é o ícone do Web Scraper
Vamos raspar as tabelas do portal de transparência do Governo Federal. Apesar de ser possível baixar os dados, só é possível baixar a base completa em determinada categoria. Ou seja, a gente teria que baixar um arquivo grande, em alguns casos com milhões de linhas, e depois usar um outro programa para fazer o recorte das informações que são relevantes para gente. Isso pode até ser o melhor caminho, dependendo da sua investigação.
Vai lá no portal da transparência. Vamos escolher os Gastos Diretos do Governo, por programa, no ano de 2014.
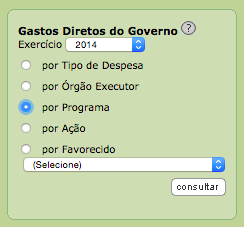
Clique em “consultar”!
Observe que a busca volta 18 páginas com todos os programas do Governo Federal e quanto ele gastou em cada um deles no ano de 2014. Temos o número do programa, o título e o valor gasto. Se fôssemos usar o importHTML() do Google Sheets, a gente teria que copiar e colar 18 vezes o endereço dessa página e ir montando a tabela, página por página.
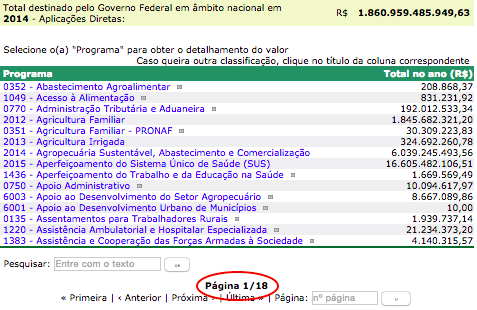
Copiar e colar 18 páginas seria uma grande perda de tempo!
Mas isso seria uma grande perda de tempo. O Web Scraper consegue capturar todos esses dados de forma automatizada, basta que a gente configure a rotina de raspagem. Vamos fazer isso, então? Clique em qualquer lugar da página e selecione “Inspecionar Elemento” para gente abrir a janela do webinspector do Chrome.
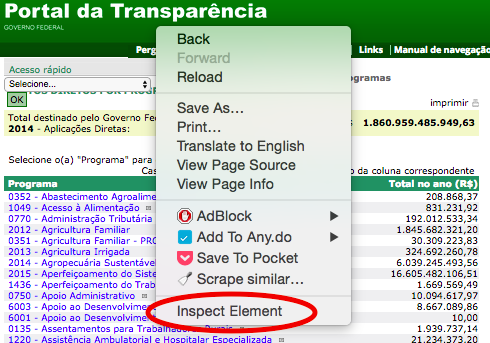
Selecione “inspecionar elemento” clicando em qualquer lugar da página
No menu superior do WebInspector, veja que agora tem uma opção chamada Web Scraper.
A aba do Web Scraper aparece por último, da esquerda para direita
São três opções no menu do Web Scraper:
- Sitemaps: aqui a ferramenta lista para gente os sitemaps, ou “robôs” de raspagem, que a gente for criando. Chamamos de robô de raspagem a rotina de captura de informações. Cada site vai ter uma rotina diferente, então cada site vai ter um robô diferente.
- Sitemap: aqui a gente configura um robô.
- Create Sitemap: a gente cria ou importa robôs configurados anteriormente ou em outros computadores. Digamos que uma colega sua fez um robô. Ela pode te passar essas configurações e você importa aqui e passa a usar o mesmo robô que ela.
Então, vamos lá. Clica em Create new sitemap e coloque um nome para o seu robô. Esse aqui vai se chamar “transparência”. Em seguida a gente coloca o endereço da página onde o robô vai começar a fazer a captura. Nesse caso é a própria página em que a gente está.
Um detalhe antes de continuarmos.
Veja que são 18 páginas. A gente quer que o nosso robô faça a raspagem dessas 18 páginas sozinho, sem que a gente tenha que ficar clicando para passar de página. Essa navegação vai ser automática. A gente precisa dizer para o Web Scraper qual é o endereço da primeira página e a progressão até a última.
Se a gente clicar em “Próxima”, você vai ver que o endereço da página muda, lá no fim. Aparece um parâmetro chamado Pagina=2. Se clicarmos em “Próximo”, de novo, veja que o parâmetro no endereço agora mudou para Pagina=3. Se a gente clicar na última página, a gente vai ver que agora o parâmetro é Pagina=18.
Isso quer dizer que cada página tem um endereço e a única coisa que muda de uma para outra é esse número depois do Pagina=. Podemos concluir também que o número progride de 1 em 1, começando do 1 até o 18.
Então, na hora de copiar e colar o endereço de onde o robô vai começar a raspagem, a gente vai dizer para o Web Scraper sobre essa progressão de páginas.
Pode copiar o endereço da última página mesmo e colar na caixa de texto. Lá no fim do endereço a gente vai trocar o número 18 pelo intervalo 1-18, entre colchetes. Basta digitar: [1-18].
http://www.portaltransparencia.gov.br/PortalTransparenciaGDProgramaPesquisaPrograma.asp?Desastre=0&Ano=2014&Pagina=[1-18]

Perceba as alterações feitas no fim do endereço!
Agora, clique no botão azul para criar o robô. Por enquanto ele estará sem nenhuma atribuição, seria um robô de raspagem “vazio”. Clique no botão Add new selector agora para gente poder começar a adicionar os elementos que vamos raspar.
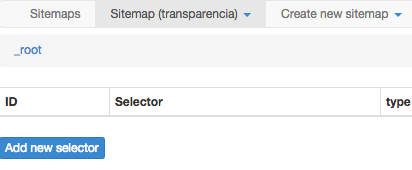
Com o robô criado, vamos começar a configurar suas tarefas de raspagem
Todos os passos seguintes estão refletidos na imagem abaixo:
- Vamos chamar esse seletor de “tabela”, no campo Id. O próximo campo é o Type. São diversas opções a gente só descobre navegando no código um pouco. Como vamos raspar a tabela do portal da transparência, selecionamos table.
- Na parte Selector a gente clica em Select e depois clicamos no topo da tabela. Dessa forma o Web Scraper mostra para gente o que ele acha que seja a tabela e ilumina de vermelho. Ele também coloca nesse campo de texto uma referência do código HTML para informar onde está essa tabela.
- Como ele reconheceu certinho, a gente clica no botão azul Done selecting! e a referência do código HTML vai lá para baixo baixo, na parte Selector. Veja que ele já preencheu os outros campos para gente. O campo do cabeçalho e o campo dos dados.
- Como são muitos campos a gente vai marcar a opção Multiple.
Lá embaixo, ele mostra para gente as colunas da tabela. Nesse caso, “Programa” e o “Total” no ano em reais. A gente quer incluir essas duas colunas na nossa raspagem, então a gente deixa aquelas caixinhas ali marcadas. Agora é só salvar clicando no botão azul.
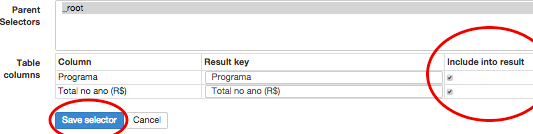
Clique em salvar!
Antes de começarmos a raspagem a gente pode clicar em Data preview, esse segundo retângulo azul, para dar uma visualizada nos dados que vão ser raspados.
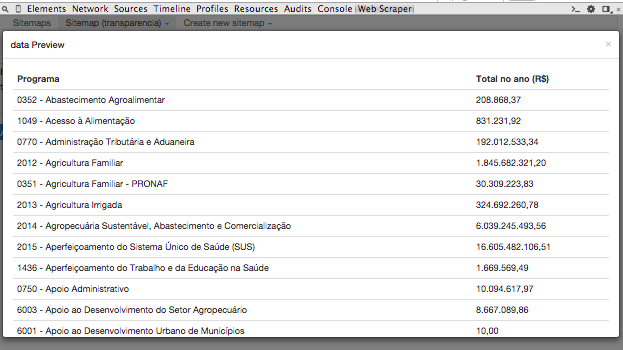
Veja que os dados foram capturados corretamente!
Está tudo certo, a coluna dos programas está aí e dos valores gastos também. Agora é só clicar em Sitemap (transparencia) e depois em Scrape.
Clique em “Scrape” para começar a rotina de raspagem!
Agora a gente configura quanto tempo o robô vai esperar para mudar de página em microssegundos. Vamos deixar 2000 mesmo, que são dois segundos, para que a gente não fique enviando requisições para o servidor do portal da transparência em curtos espaços de tempo. Se muitas pessoas fizessem isso, a rede pode ficar sobrecarrega e acabar prejudicando o acesso de todo mundo.
A segunda opção configura quanto tempo o robô vai esperar o carregamento da página antes de tentar raspar as informações. Esse número pode variar dependendo do tempo de resposta entre a sua conexão e a conexão do servidor do portal da transparência. Se você perceber que o robô não raspou tudo que você queria, aumente esse número para dar mais tempo para página carregar.
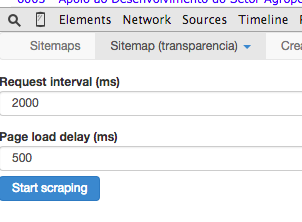
As configurações nessa tela são importantes para não sobrecarregar os sites que vamos raspar
Agora é só clicar em start scraping. Uma janela nova vai abrir e as páginas vão carregar automaticamente. O processo todo, nesse exemplo, vai demorar um minuto. Veja que os dados agora aparecem na própria interface do Web Scraper para gente poder conferir.
Depois que a raspagem é concluída, o Web Scraper mostra para gente o que ele conseguiu capturar
Se estiver tudo ok agora a gente vai exportar os dados para um arquivo CSV. Vai lá em Sitemap (transparencia) e escolha a última opção. Clica em Download now! e salve o arquivo no computador.
Só clicar em “Download now!” e correr para o abraço!
Esse arquivo agora pode ser manipulado no Google Sheets ou qualquer outro aplicativo de planilhas!
Resumo
Falamos de raspagem e sobre como extrair dados de alguns sites usando ferramentas gratuitas. A principal função da raspagem é converter dados semiestruturados em dados estruturados e, assim, torná-los aptos para novos processamentos. Isso é algo relativamente simples se você sabe um pouco de programação. Mais simples ainda para o caso de trabalhos com uma página só da internet, quando é possível executar a tarefa sem conhecimentos de programação. Apresentamos técnicas de raspagem usando o Google Sheets, o IFTTT e o Web Scraper!








