
Este vídeo conta com o áudio original da transmissão. Veja o vídeo com a tradução simultânea abaixo.
Neste workshop, o criador do Datasette, Simon Willison, explica na prática como utilizar o software de exploração, publicação e visualização de dados, para explorar dados extraídos de sites com o Git Scraping. A técnica é realizada a partir do GitHub Actions, ferramenta de automação gratuita fornecida pelo GitHub.
ASSISTA AO VÍDEO COM TRADUÇÃO SIMULTÂNEA
Abaixo, você confere a tradução integral para o português do passo a passo elaborado por Willison:
Raspando dados com o GitHub Actions e analisando com o Datasette
Por Simon Willison (@simonw)
Documento original: https://bit.ly/dados-datasette
Tópicos:
- Git scraping
- Exercício 1: Construir um raspador usando o GitHub Actions
- Exercício 2: Teste o Datasette com alguns dados raspados
- Exercício 3: Use sqlite-utils e Datasette para construir um de você mesmo
- Exercício 4: Os dados dos buracos, com git-history, no GitPod
Git scraping
Links úteis
- Git scraping: rastreie as alterações ao longo do tempo, raspando para um repositório
- Git scraping, a apresentação relâmpago de cinco minutos
Meu git scraper favorito que construí é para as árvores em São Francisco: https://github.com/simonw/sf-tree-history
Todos os dias ele verifica se alguém atualizou o arquivo oficial de árvores da cidade – são mais de 195.000 árvores! Na maioria dos dias da semana, há alguma atualização: https://data.sfgov.org/City-Infrastructure/Street-Tree-List/tkzw-k3nq
Como a página de histórico de commits está quebrada agora, aqui estão algumas alterações recentes monitoradas:
- 96528d0 Thu Nov 11 11:32:01 2021 +0000 18 trees changed, 80 trees added
- 6680fe7 Sun Nov 7 11:29:47 2021 +0000 12 trees changed, 11 trees added
- 5cc6330 Thu Nov 4 11:30:20 2021 +0000 13 trees changed, 2 trees added
- 92814f5 Sun Oct 31 11:29:53 2021 +0000 2 trees changed, 6 trees added
Exercício 1: Construir um raspador usando o GitHub Actions
Vamos construir um Git scraper, usando apenas uma conta GitHub e nosso navegador. Vamos coletar os dados por trás do mapa do terremoto USGS em https://earthquake.usgs.gov/earthquakes/map/. Escolhi esse site porque os dados mudam com frequência, então devemos ver algumas mudanças durante o workshop.
Podemos usar o navegador Inspetor Web/DevTools para rastrear os dados por trás do mapa:
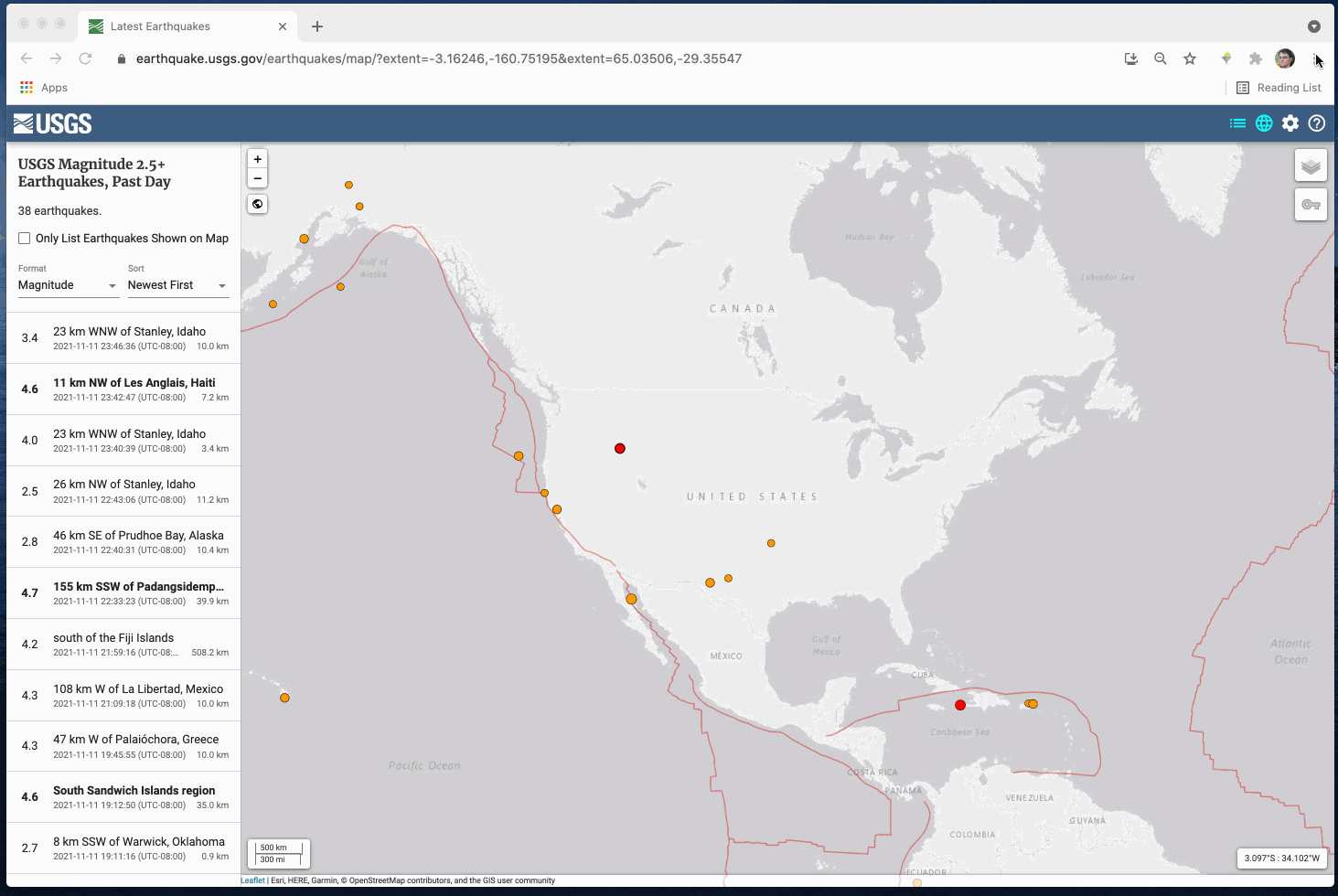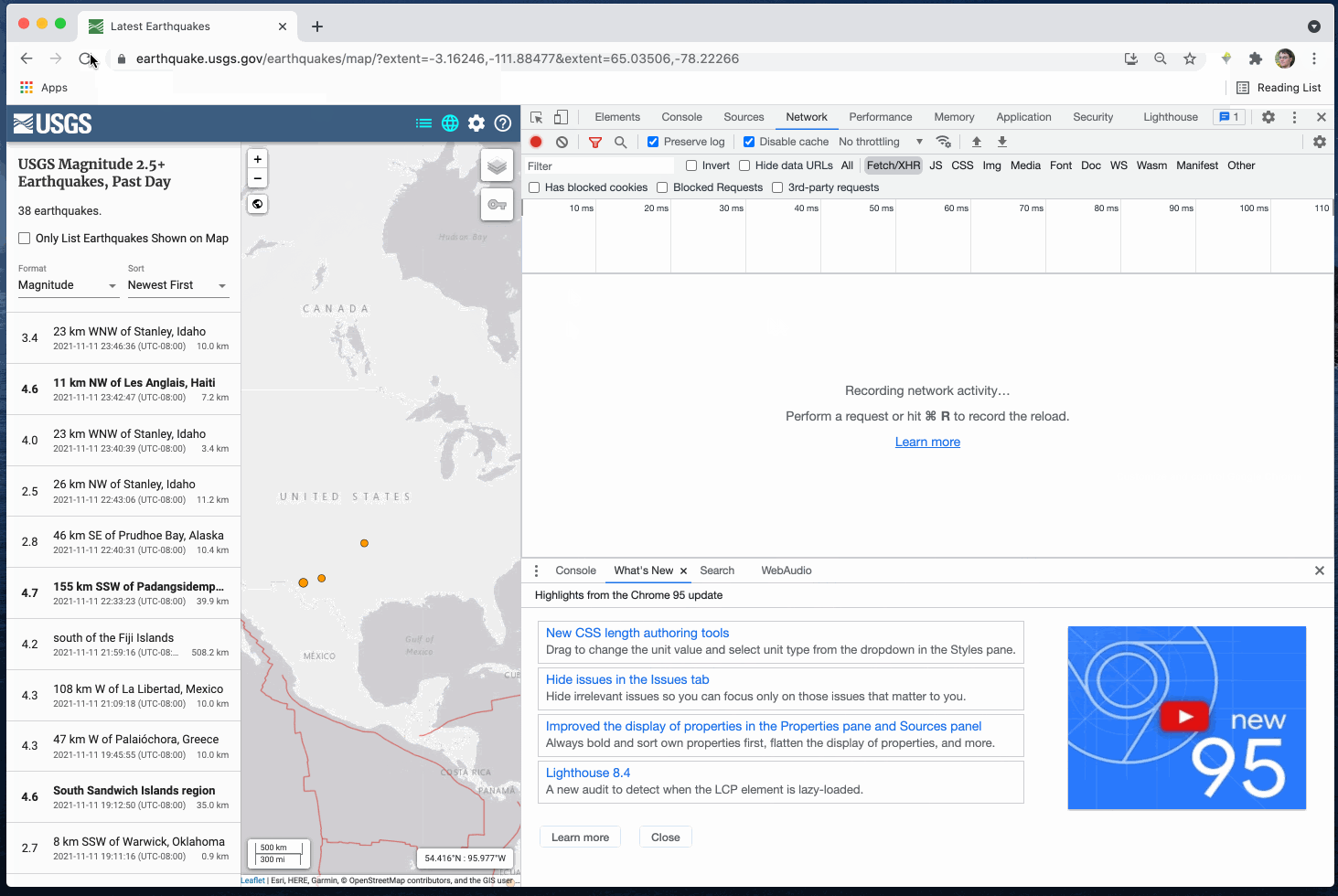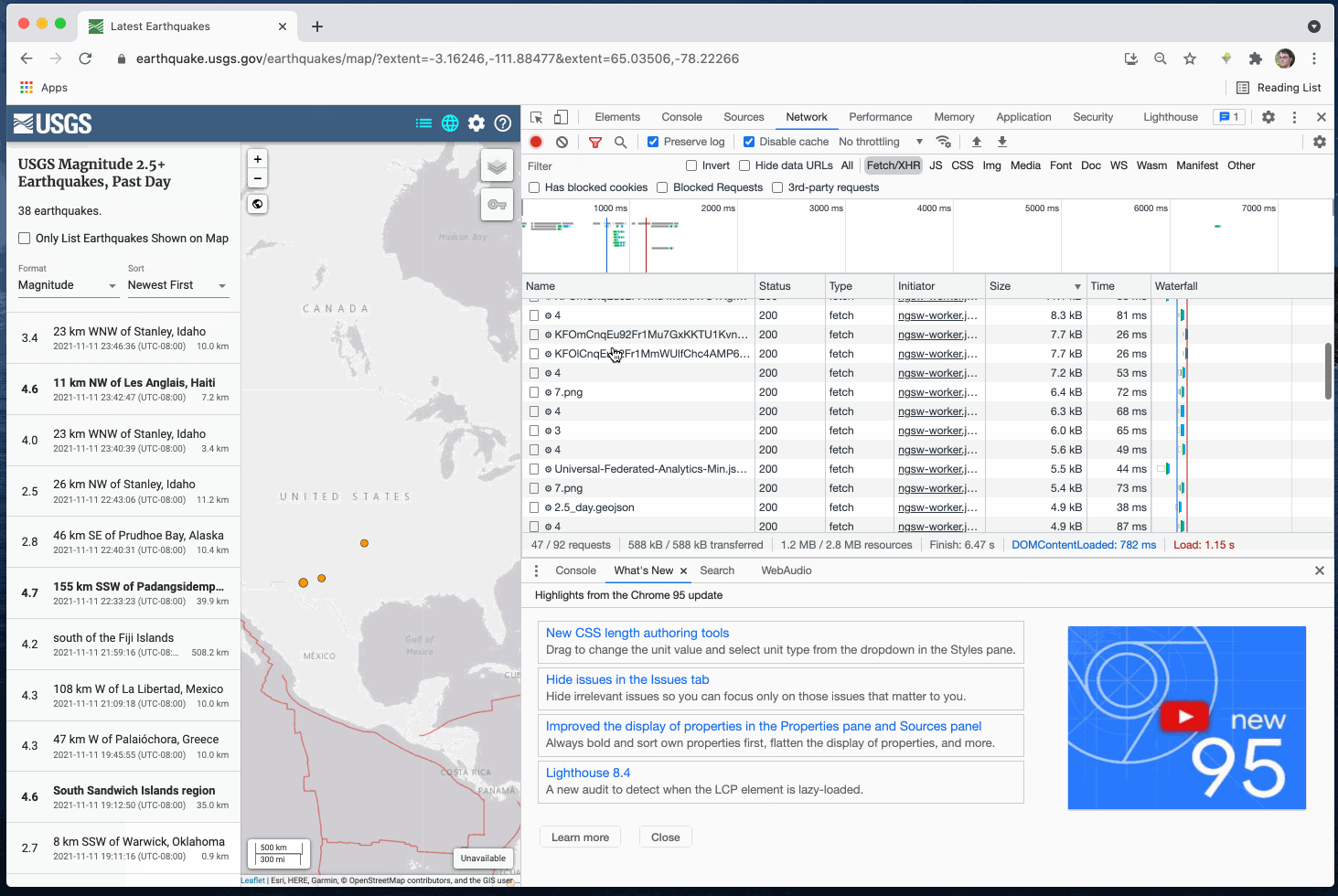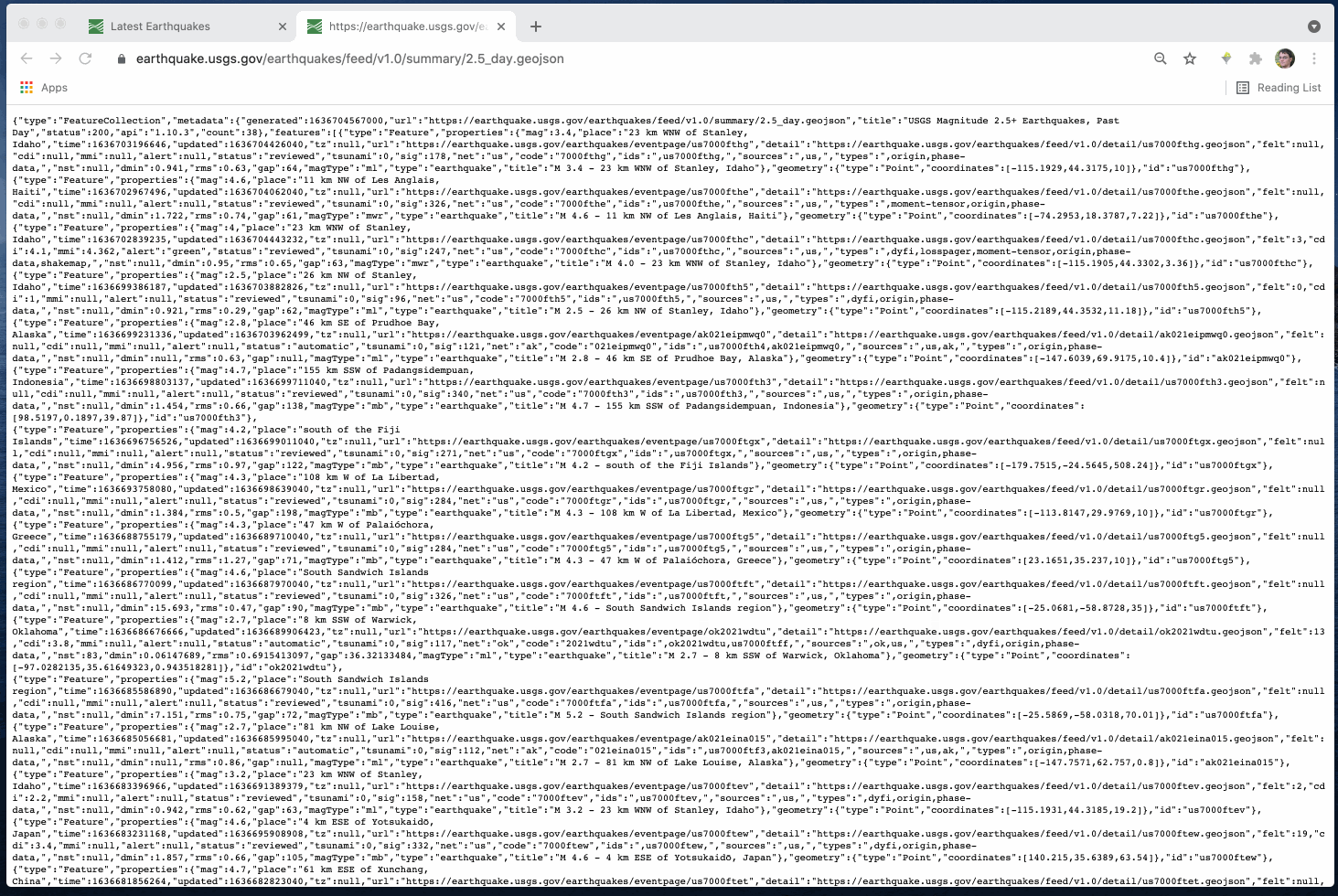 Neste caso, temos um arquivo em https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/2.5_day.geojson.
Neste caso, temos um arquivo em https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/2.5_day.geojson.
Isso também está documentado aqui: https://earthquake.usgs.gov/earthquakes/feed/v1.0/geojson.php.
Vamos começar a fazer a raspagem a cada dez minutos, usando o GitHub Actions.
- Certifique-se de ter uma conta em https://github.com/ – se você ainda não tem uma, inscreva-se agora;
- Crie um novo repositório – https://github.com/new – eu sugiro chamá-lo de usgs-scraper, mas você pode chamá-lo do que quiser;
- Clique em “Add README” para terminar de criar o repositório;
- Agora vamos adicionar o raspador. Clique em “Add file -> Create new file” – então no campo “Name your file…” digite cuidadosamente o seguinte: .github/workflows/scrape.yml
Copie e cole o texto daqui no novo arquivo: https: // gist.github.com/simonw/f010059f240fddab1ffd2a60ec9eb49d (clique em “Raw” para ter certeza de copiar o texto correto).
Isso define o que o GitHub chama de “workflow”. Ele será executado a cada dez minutos. Também será executado sempre que você der “push” em algum código (ou seja, editar arquivos em seu repositório) ou ainda quando clicar em um botão manual – é isso que “workflow_dispatch” significa.
Ele fará o download do arquivo sobre terremotos usando a ferramenta curl e, em seguida, executará o comando jq para imprimir o JSON – isso faciltia a exibição das diferenças do arquivo.
Em seguida, ele grava o resultado em um arquivo chamado usgs.json e confirma todas as atualizações de volta para o repositório.
Salve o arquivo … e pronto! Você criou seu primeiro raspador. Se você clicar na guia “Actions”, poderá vê-lo em execução.
Esta é a forma mais simples possível do Git scraper. Ele pode funcionar para páginas HTML ou arquivos CSV também, se você omitir a parte do comando com o |jq pois ele só funciona com arquivos JSON.
Alguns exemplos: https://github.com/topics/git-scraping
https://github.com/topics/git-scraping?o=desc&s=updated
https://github.com/datadesk/california-coronavirus-scrapers
Exercício 2: Teste o Datasette com alguns dados extraídos
Agora que sabemos como extrair dados, o que podemos fazer com os dados que coletamos?
Passei os últimos quatro anos construindo uma ferramenta chamada Datasette. É uma ferramenta para explorar, visualizar e publicar dados. É uma ótima opção para explorar dados coletados por meio de git scraping.
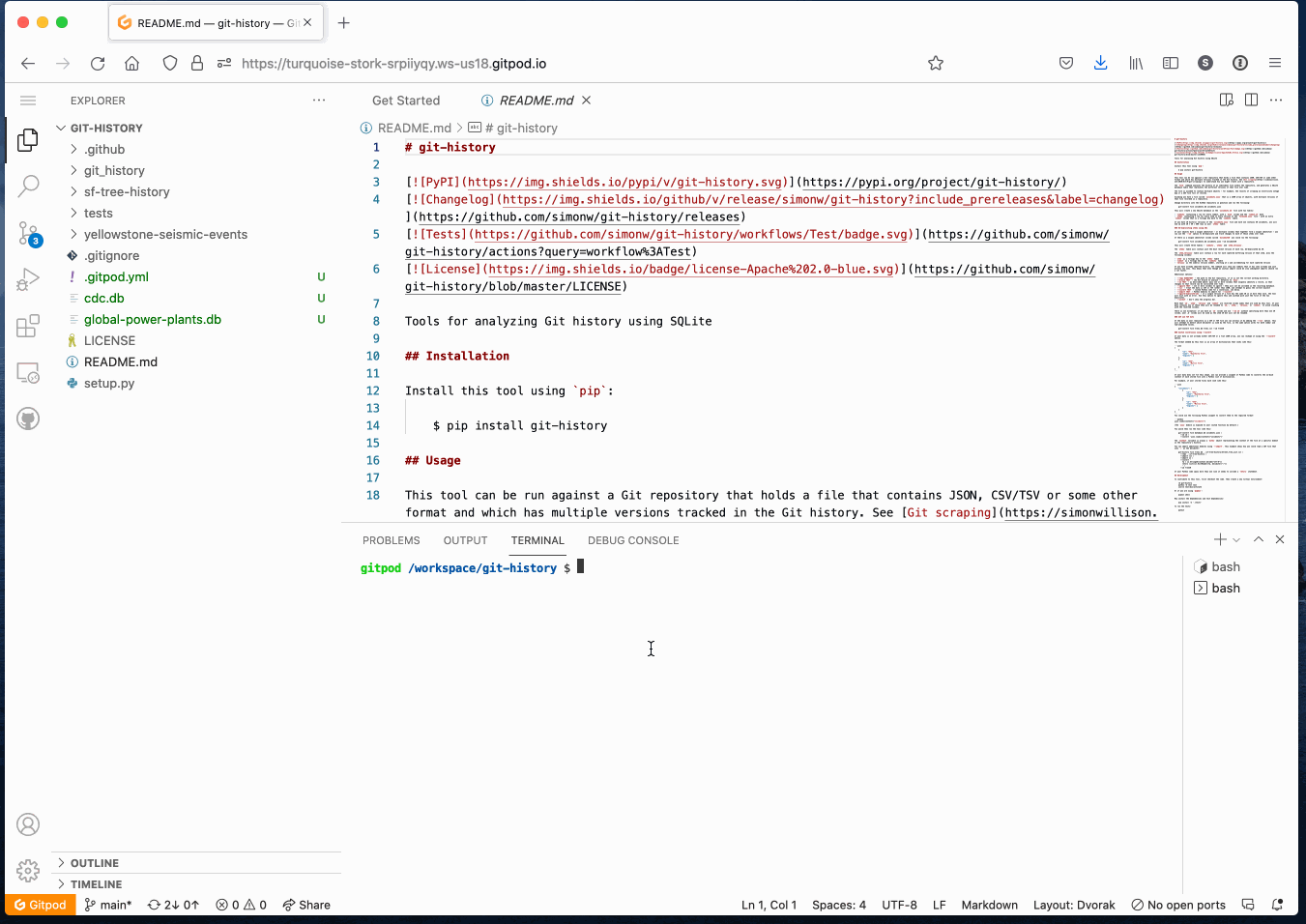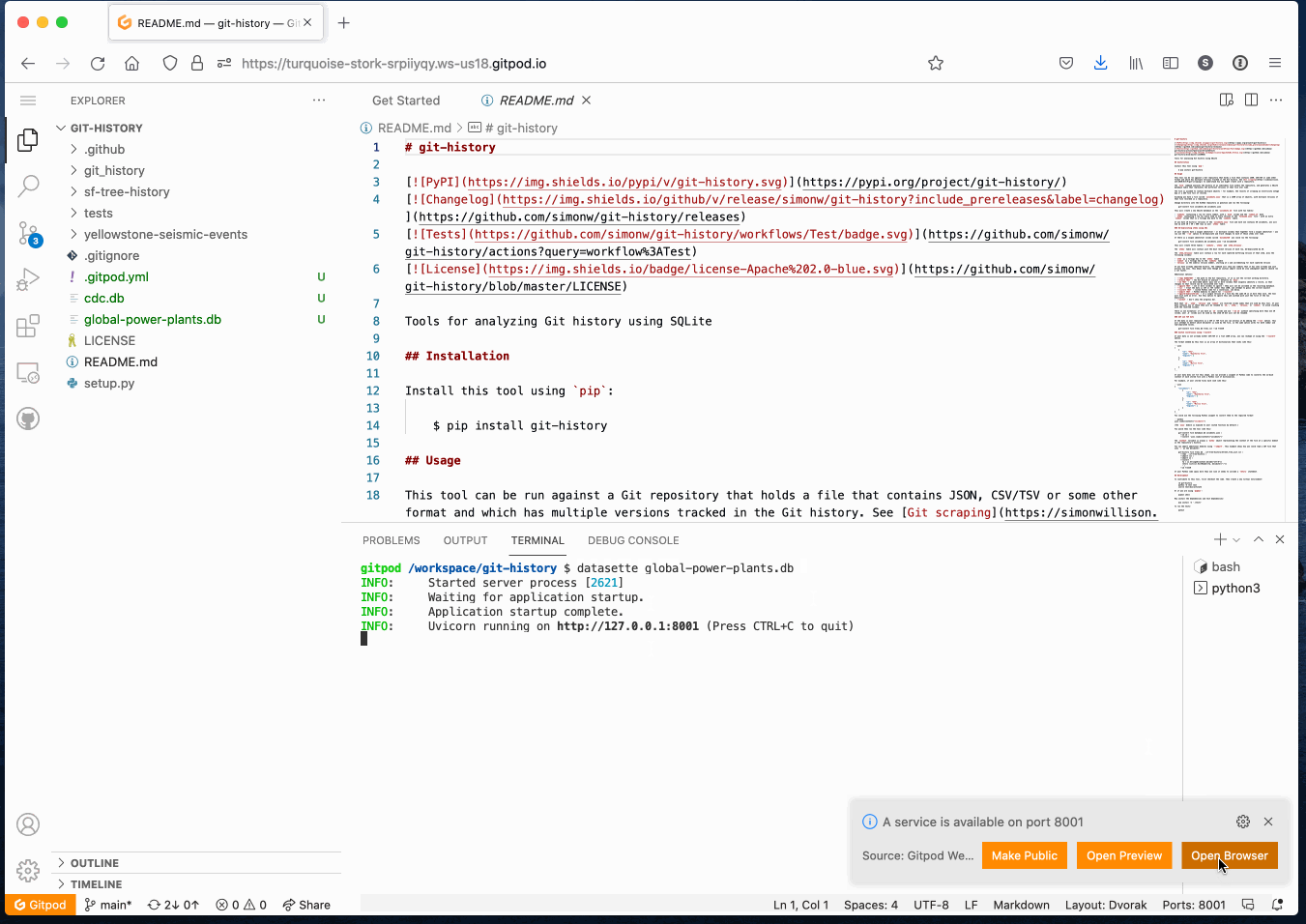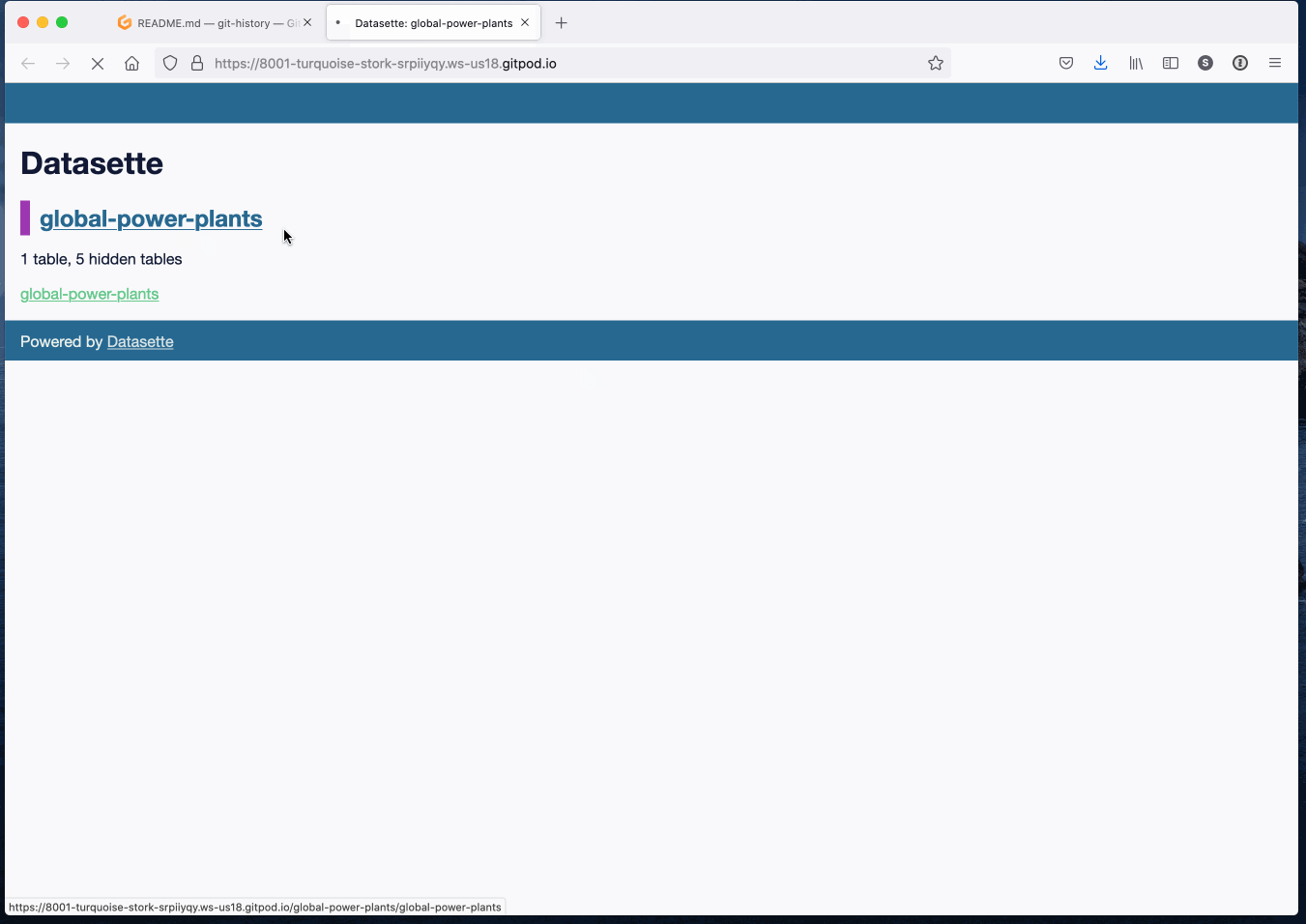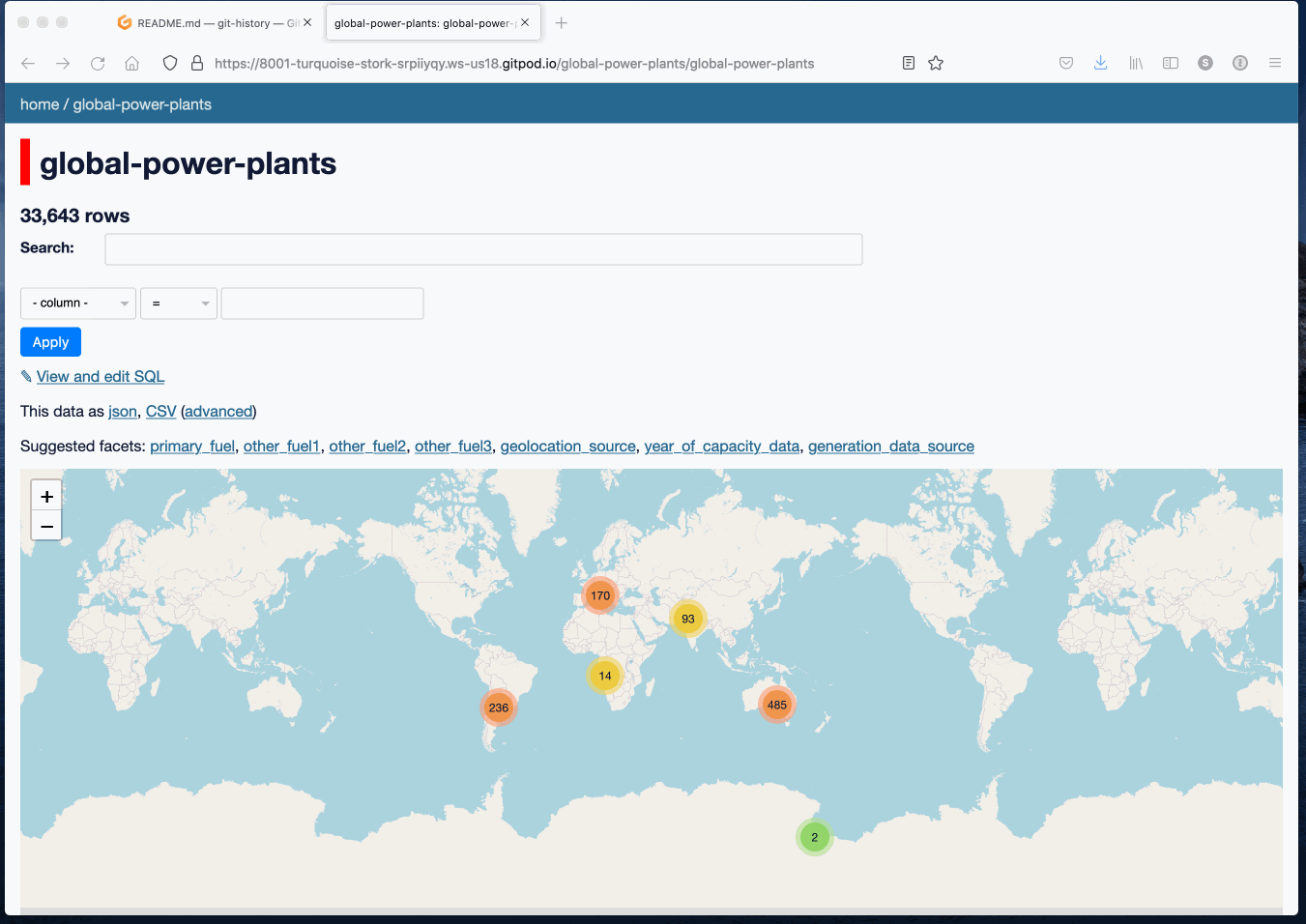
Vou começar com uma demonstração: https://global-power-plants.datasettes.com/global-power-plants/global-power-plants.
Esta é uma instância de Datasette contendo 33.000 usinas de todo o mundo, importadas de um arquivo CSV publicado pelo World Resources Institute.
Os links na parte superior da página são chamados de “facets” – uma ferramenta para agrupar e filtrar os dados.
Posso usá-los para ver todas as usinas de energia no Brasil: https://global-power-plants.datasettes.com/global-power-plants/global-power-plants?country_long=Brazil.
Aqui está um mapa de todas as usinas solares no Brasil: https://global-power-plants.datasettes.com/global-power-plants/global-power-plants?country_long=Brazil&primary_fuel=Solar.
Posso exportar esses dados como CSV ou JSON.
Se eu clicar em “View and edit SQL”, também posso compor minhas próprias consultas SQL com os dados.
Vou fazer outra demonstração do meu Datasette pessoal, chamado Dogsheep. Você pode ver mais sobre isso em Personal Data Warehouses: Reclaiming Your Data.
Veja também: https://dogsheep.github.io/
Agora vamos dar uma olhada em um exemplo diferente, criado usando o Git scraping.
Este site sobre vacinação é uma instância de Datasette que criei usando dados coletados por meu raspador. Fiz este trabalho no contexto da produção deste vídeo: https://simonwillison.net/2021/Mar/5/git-scraping/.
Como estou copiando a página todos os dias há 8 meses, tenho MUITOS dados históricos.
Eu escrevi um código Python personalizado para transformá-lo no banco de dados que você vê em https://cdc-vaccination-history.datasette.io/.
O script é esse: https://github.com/simonw/cdc-vaccination-history/blob/main/build_database.py.
Comece por esta página: https://cdc-vaccination-history.datasette.io/cdc/daily_reports_counties
Construa uma consulta StateName = California. Clique em Apply e, depois, clique no pequeno ícone de engrenagem na coluna “County” e selecione “Facet by this”.
Selecione “Alameda County” para ver apenas os dados coletados para esse condado na Califórnia.
Agora, clique em “Show charting options”, selecione “line”, defina a coluna X para “Date” do tipo “Date/Time” e a coluna Y para “Series_Complete_Pop_Pct” do tipo “Numeric”. Você verá um gráfico de linha!
Exercício 3: Use sqlite-utils e Datasette para construir sua própria instância
SQLite: https://www.sqlite.org/index.html.
Em seguida, vamos construir nossa própria instância do Datasette.
Para isso, vamos precisar de um ambiente de desenvolvimento Python.
Se você tem um desses em seu laptop e sabe como usá-lo (instalando ferramentas com pip install etc), você pode fazer isso.
Se você não tem um ambiente em seu laptop – ou se deseja tentar algo novo – recomendo que me acompanhe, pois utilizarei o GitPod como um ambiente de desenvolvimento baseado em nuvem para a próxima etapa.
Reutilizaremos o repositório GitHub que você criou anteriormente.
- Visita https://gitpod.io e faça login com sua conta do GitHub
- Clique em “New Project” ou visite https://gitpod.io/new e selecione aquele repositório GitHub anterior (qualquer repositório servirá aqui, na verdade)
- Crie e insira um espaço de trabalho para esse repositório.
Seu espaço de trabalho oferece um editor de texto completo (baseado no código do VisualStudio) rodando em seu navegador. Ele também executa um ambiente Linux dedicado para você, no qual você pode executar comandos.
Abra a guia Terminal na parte inferior da página. É onde executaremos os comandos para instalar e começar a executar o Datasette.
Execute estes comandos:
pip install datasette
Isso instala o Datasette. Mas também precisamos instalar alguns plugins.
datasette install datasette-x-forwarded-host
Isso instala um plugin que é necessário para garantir que o GitPod sirva os links corretos dentro do Datasette.
datasette install datasette-cluster-map datasette-vega
Isso instala mais dois plug-ins: um para a visualização do mapa e outro para a ferramenta que permite criar gráficos.
Vamos pegar uma cópia do banco de dados de usinas de energia para testar em nosso próprio Datasette:
datasette install datasette-cluster-map datasette-vega
Agora podemos iniciar o Datasette rodando assim:
datasette global-power-plants.db
Em seguida, clique no botão “Open Browser”:
Em seguida, vamos criar nosso próprio arquivo de banco de dados SQLite. Usaremos o banco de dados de árvores em San Francisco – aquele que venho criando com um raspador Git há vários anos.
Podemos obter isso neste repositório: https://github.com/simonw/sf-tree-history.
O link completo que queremos para o arquivo CSV bruto é:
https://github.com/simonw/sf-tree-history/blob/main/Str;eet_Tree_List.csv?raw=true
Então, no GitPod, pressione Ctrl + C para interromper o Datasette e execute o seguinte:
wget “https://github.com/simonw/sf-tree-history/blob/main/Street_Tree_List.csv?raw=true”
mv Street_Tree_List.csv\?raw\=true Street_Tree_List.csv
Esse segundo comando renomeia o arquivo para algo mais agradável – se você digitar mv Stree e clicar em Tab, o nome do arquivo horrível será completado para você, te salvando de ter que digitar isso.
Agora que temos um arquivo CSV, podemos convertê-lo em um banco de dados SQLite. Como é um arquivo muito grande, vamos usar um truque que carrega dados MUITO rápido no SQLite:
sqlite3 trees.db <<EOS
.mode csv
.import Street_Tree_List.csv trees
EOS
Agora podemos rodar o datasette trees.db para ver um mapa interativo de 195.000 árvores em San Francisco!
Outros serviços como o GitPod são os Codespaces GitHub (disponível apenas para testadores beta) e o Replit https://replit.com/.
Lembrando que também é possível realizar cruzamentos de dados utilizando a função join. Neste link, há uma demo do cruzamento dos dados no New York Times sobre COVID-19 divididos por condado, com dados do censo populacional americano a partir do código FIPS.
Para lidar com CSV com ponto e vírgulas em vez de vírgulas, use o seguinte comando:
sqlite-utils insert man.db mananciais mananciais.csv –csv –sniff
As mensagens de commit em https://github.com/simonw/sf-tree-history/blob/main/.github/workflows/update.yml funcionam a partir da ferramenta csv-diff de https://github.com/simonw/csv-diff.
Exercício 4: Os dados dos buracos, com git-history, no GitPod
Vimos como criar um banco de dados a partir da versão mais recente de um arquivo com os dados das árvores de São Francisco.
Mas o objetivo do git scraping é capturar informações históricas. Como podemos transformar isso em algo que possamos usar?
Navegar no histórico no GitHub não é uma maneira eficiente de entender os dados!
Tenho resolvido isso em meus próprios projetos com um código Python personalizado, mas desenvolvi uma ferramenta que pode ajudar a resolver esse problema de forma mais geral para outros projetos.
É o git-history: https://datasette.io/tools/git-history.
Vamos testá-lo em alguns dados coletados usando o git scraping.
Tenho encorajado as pessoas que estão usando a técnica de git scraping a aplicar uma tag chamada “git-scraping” a seus repositórios no GitHub. Existem agora 199 desses repositórios, em https://github.com/topics/git-scraping.
Se você classificá-los por “Recently updated”, algo mágico acontece: você pode ver os scrapers Git que capturaram os dados mais recentes, às vezes apenas alguns minutos atrás! https://github.com/topics/git-scraping?o=desc&s=updated.
Ao navegar por essas tag, me deparei com este: https://github.com/patricktrainer/open-potholes.
Patrick Trainer tem coletado dados sobre buracos de panela na estrada em Nova Orleans, raspando dados dos registros de serviço 311 de Nova Orleans: https://data.nola.gov/City-Administration/311-OPCD-Calls-2012-Present-/2jgv-pqrq/data.
No GitPod, começaremos instalando a ferramenta git-history:
pip install git-history
A seguir, clonaremos uma cópia de seu repositório, com todos os dados históricos do buraco:
git clone https://github.com/patricktrainer/open-potholes
cd open-potholes
Agora podemos executar um comando para construir um banco de dados que nos mostra todas essas mudanças:
git-history file potholes.db potholes.json –id service_request
O comando file cria um banco de dados que reflete as mudanças feitas em um único arquivo no repositório. Nesse caso, esse é o arquivo potholes.json e queremos criar um banco de dados chamado potholes.db.
Ao olhar para o histórico de algo, é importante ter um ID que pode ser usado para dizer quais itens são novos e quais são atualizações de um item anterior. Neste caso, olhar o arquivo nos mostra que service_request é o ID correto para isso.
Podemos executar datasette potholes.db para começar a explorar nosso banco de dados.
A tabela itens contém apenas a versão mais recente de cada buraco.
A tabela item_versions contém várias linhas para buracos que foram atualizados várias vezes.
Dê facet por item para ver os buracos com mais entradas. Clique em um deles e você verá uma linha do tempo cronológica das alterações feitas neste registro.
Mais uma demonstração: incidentes de Houston
Usando o repositório de https://github.com/adolph/getIncidentsGit:
git-history file incidents.db /tmp/getIncidentsGit/incidents.json –repo /tmp/getIncidentsGit \
–id CallTimeOpened –id Address –id CrossStreet \
–convert ‘json.loads(content)[“ActiveIncidentDataTable”]’ \
–ignore-duplicate-ids
Este comando levou HORAS para ser executado.
datasette incidents.db –setting facet_time_limit_ms 10000
Outros links e comandos úteis abaixo:
https://sqlite-utils.datasette.io/en/stable/cli.html#extracting-columns-into-a-separate-table
https://sqlite-utils.datasette.io/en/stable/cli.html#converting-data-in-columns
https://sqlite-utils.datasette.io/en/stable/cli.html#transforming-tables
sqlite-utils convert incidents.db items XCoord YCoord \
‘float(value) / 1000000.0 if value else None’
sqlite-utils transform incidents.db items \
–rename XCoord longitude \
–rename YCoord latitude
sqlite-utils convert incidents.db items CallTimeOpened \
‘r.parsedatetime(value)’
sqlite-utils convert incidents.db items Units \
‘r.jsonsplit(value, delimiter=”;”)’
sqlite-utils extract incidents.db items IncidentType
https: // simonwillison. net / terá mais sobre git-history.
https://datasette.io/
Básico.
1:30h

Simon Willison
Criador do Datasette, JSK Fellow de Stanford em 2020 e co-criador do Django.
REALIZAÇÃO
![]()
![]()
DESENVOLVIDO COM

APOIO

![]()
![]()

![]()
![]()

![]()
APOIO DE MÍDIA
![]()
![]()

![]()