
Ferramenta e guia desenvolvido por Adriano Belisário para a Bellingcat,
tradução e adaptação por Anicely Santos em outubro de 2024.
Observação: todo conteúdo em itálico são adições feitas pela Escola de Dados ao texto original.
Suponha que você coletou milhares de imagens de um grupo do Telegram ou de um site de mídia social, algumas das quais podem ser cruciais para uma investigação de um conflito em andamento. Você está procurando especificamente por fotos e vídeos de armas, mas estes estão misturados com memes, capturas de tela e outros materiais não relacionados. Revisar e categorizar as imagens manualmente levaria mais tempo do que você tem. O que você faz?
Neste guia, mostramos como você pode usar modelos de inteligência artificial (IA) para acelerar tarefas como essa – mesmo que você não saiba programar – com a ajuda do Smart Image Sorter (Classificador Inteligente de Imagens), uma ferramenta de código aberto que criamos.
A classificação de imagens por IA mostrou-se útil em investigações anteriores, como as que envolviam crimes de guerra no Iêmen ou mineração ilegal na floresta amazônica.
Normalmente isso exige algum grau de conhecimento técnico – desde saber como acessar os modelos de IA em primeiro lugar até treiná-los para reconhecer categorias específicas de objetos.
O Smart Image Sorter, no entanto, utiliza uma família específica de modelos – conhecidos como modelos de zero-shot – que podem ser usados sem necessidade de treinamento prévio, tornando fácil para qualquer pessoa começar a classificar imagens com IA.
O que é Classificação de Imagens Zero-Shot?
Modelos tradicionais de classificação de imagens por inteligência artificial requerem treinamento com rótulos específicos vinculados às imagens. Os usuários estão limitados às categorias pré-definidas pelos rótulos, restringindo a capacidade do modelo de identificar qualquer coisa fora dos rótulos estabelecidos.
Por exemplo, um modelo treinado apenas com imagens rotuladas como gatos e cachorros provavelmente vai reconhecer esses animais, mas falhará em identificar um pinguim devido à ausência de imagens rotuladas como pinguins nos dados de treinamento.
Modelos de zero-shot, uma inovação relativamente nova no campo do aprendizado de máquina e inteligência artificial, ajudam a superar essas restrições. Eles são treinados em uma ampla variedade de dados e têm um entendimento abrangente de linguagem e imagens, tornando possível classificar imagens que nunca foram incluídas em seu treinamento. Por exemplo, um modelo de zero-shot pode reconhecer um pinguim associando suas cores preto e branco e sua forma semelhante a um pássaro a imagens semelhantes às que ele já viu, mesmo que nunca tenha sido treinado especificamente para reconhecer imagens de pinguins.
Introduzido em 2021, o modelo CLIP (Contrastive Language–Image Pre-training) da OpenAI tem sido influente na popularização deste método de classificação de imagens devido à sua flexibilidade e ao desempenho robusto.
O CLIP e os modelos de IA semelhantes aprendem a combinar imagens com descrições ao converter tanto texto quanto imagens em representações numéricas, conhecidas como embeddings, que um computador pode entender. Quando você fornece uma nova imagem ou texto para eles, eles verificam o quão próximo isso corresponde às coisas que eles aprenderam antes ao comparar esses números no que é conhecido como um espaço de embedding compartilhado.
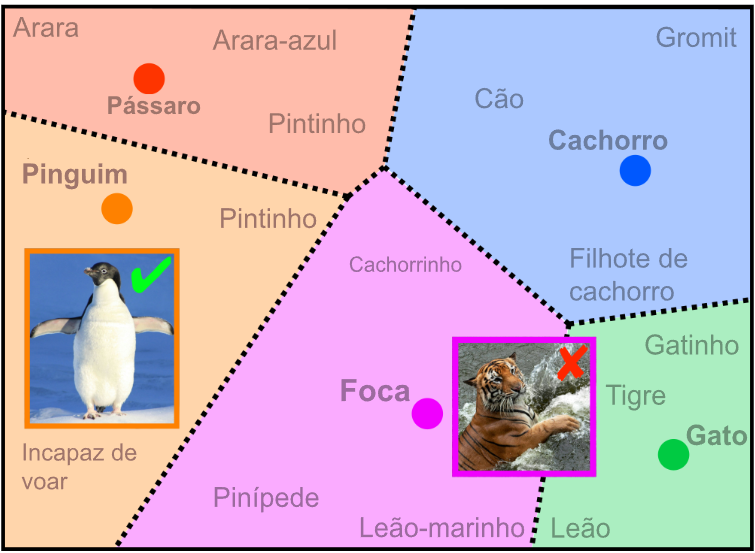
Palavras e imagens semelhantes são agrupadas juntas em um espaço de embedding compartilhado. À esquerda, uma imagem de entrada de um pinguim é corretamente associada ao rótulo “pinguim”. À direita, uma imagem de um tigre no mar é incorretamente associada ao rótulo “foca” devido à sua proximidade com rótulos relacionados a criaturas marinhas. Gráfico: Galen Reich. Imagem traduzida pela Escola de Dados, 2024.
Usando o Smart Image Sorter com Google Colab
A maneira mais fácil de executar o Smart Image Sorter é rodando nosso programa no Google Colab diretamente no seu navegador e carregando quaisquer imagens que você gostaria de usar no Google Drive.
Google Colab é uma ferramenta gratuita e baseada na nuvem que permite aos usuários escrever e executar código Python em navegadores da web usando um ambiente interativo conhecido como “notebook”.
A Bellingcat já publicou anteriormente um guia detalhado e um vídeo explicativo sobre como notebooks que podem ser úteis para pesquisas de fontes abertas. Aqui na Escola de Dados temos um tutorial rápido em vídeo sobre o assunto.
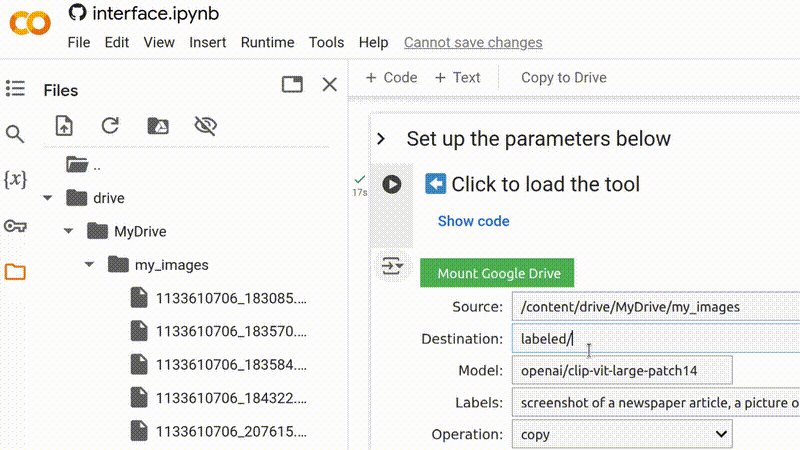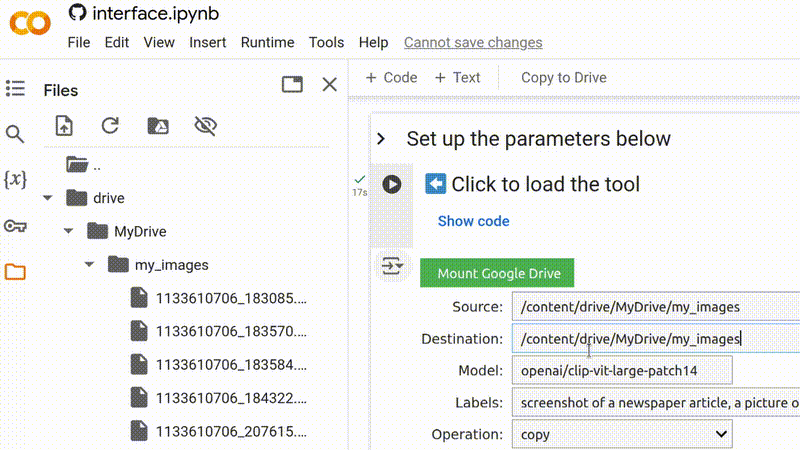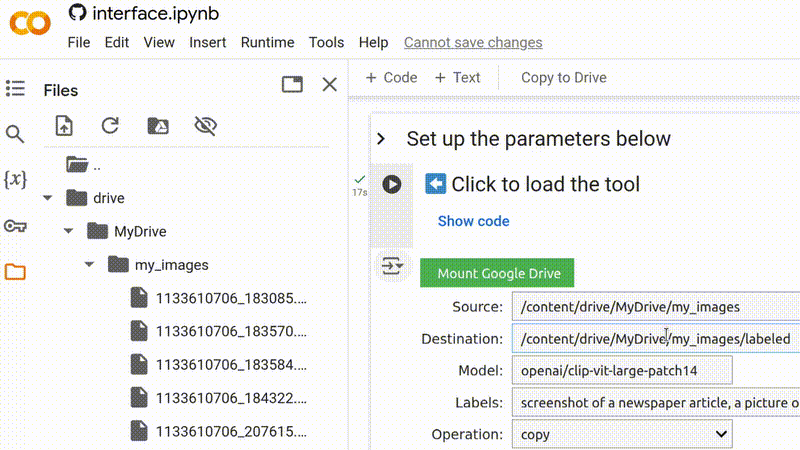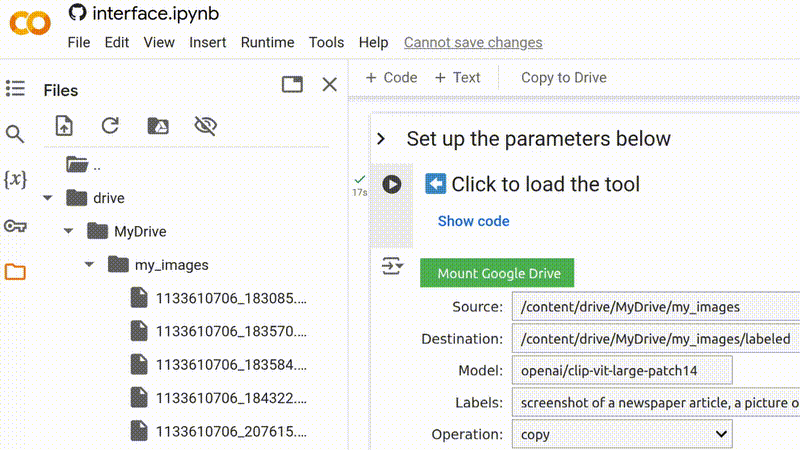
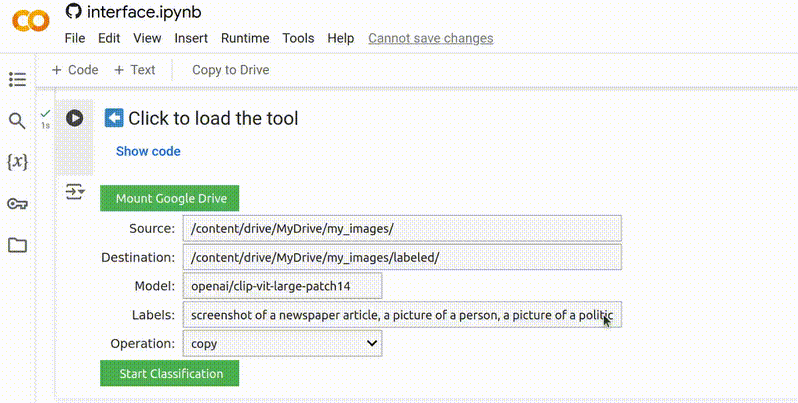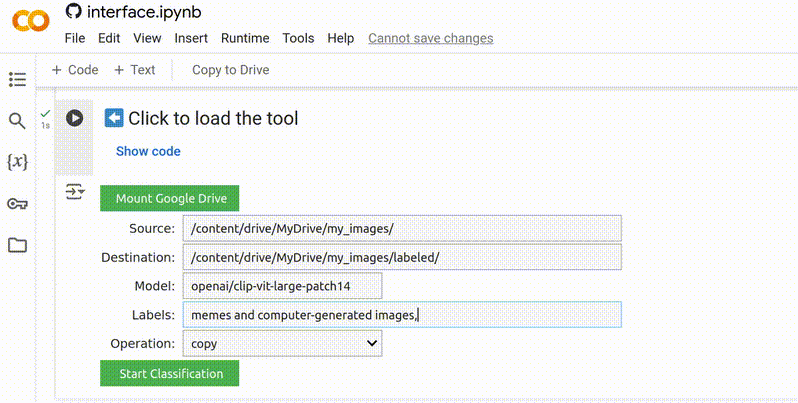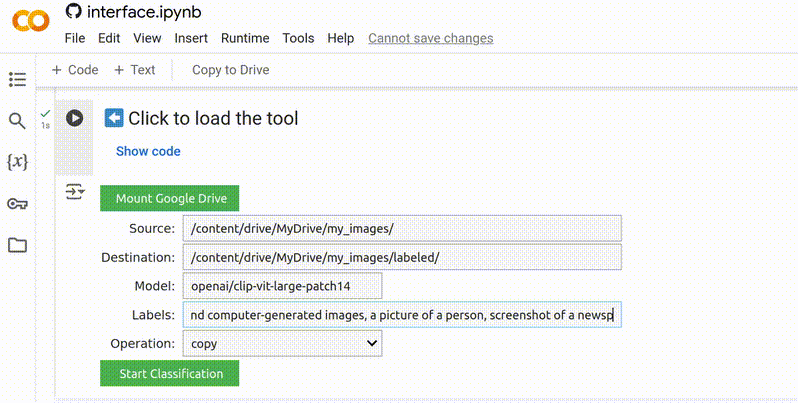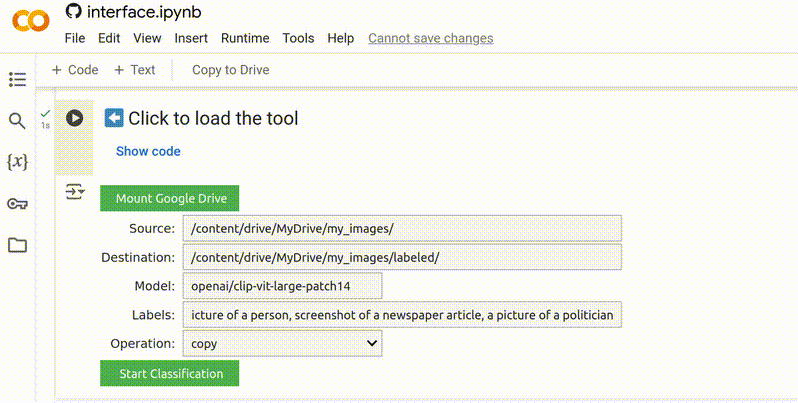
1. Carregue a ferramenta
Para começar, certifique-se de que você está logado em sua conta do Google. Abra a ferramenta no seu navegador e clique em ▶ para carregá-la.
Você verá um aviso de que o notebook não foi criado pelo Google. Este é um aviso padrão para qualquer notebook carregado de uma fonte externa. Não se preocupe: nenhum código usado nesta ferramenta é malicioso, e ele não concede acesso da Bellingcat ou de outros usuários aos seus dados. Para prosseguir, clique em Run anyway (Executar mesmo assim).
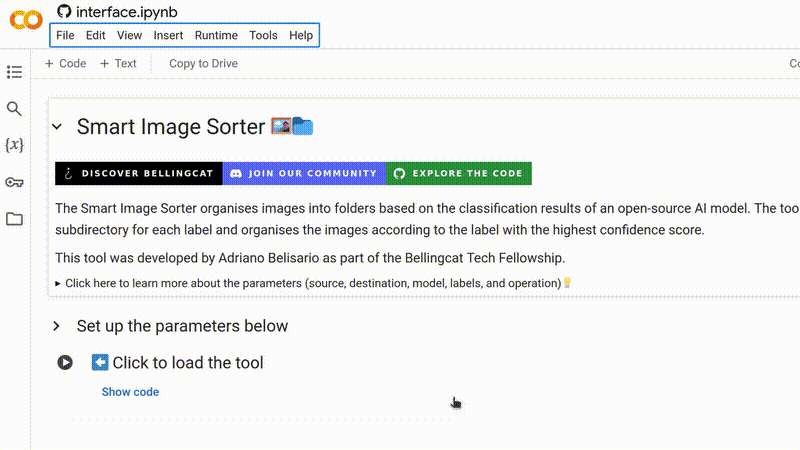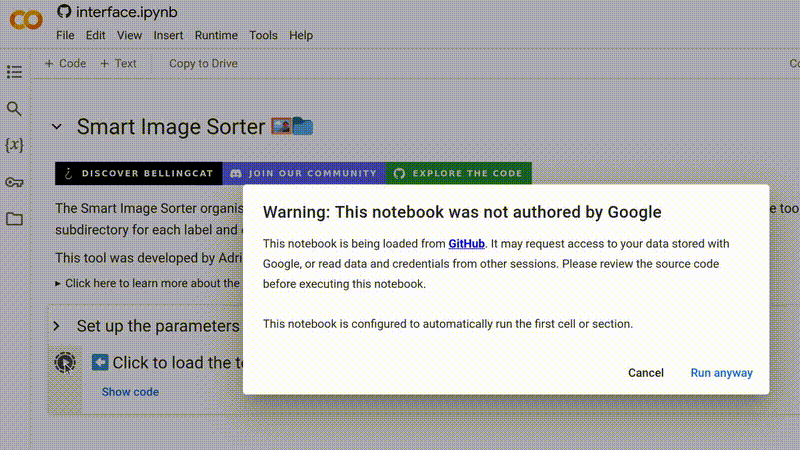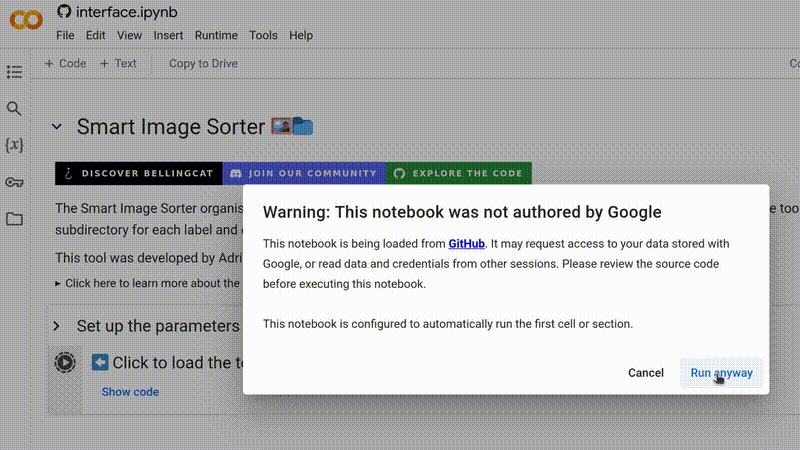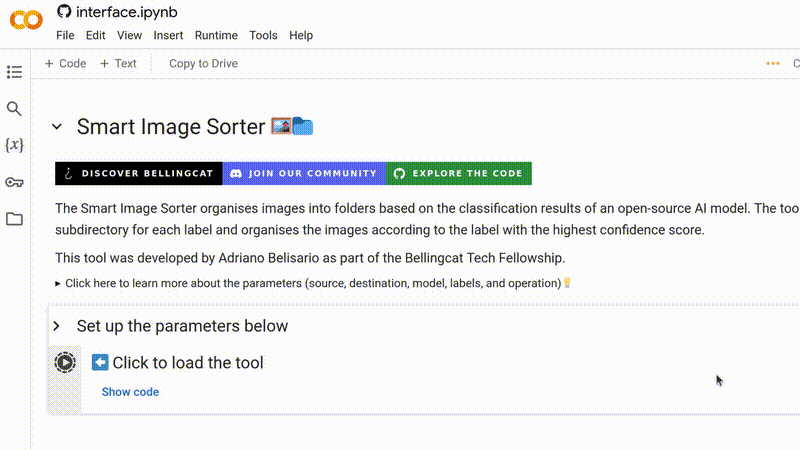
Para começar a executar o Smart Image Sorter, clique simplesmente em ▶ e depois em Run anyway.
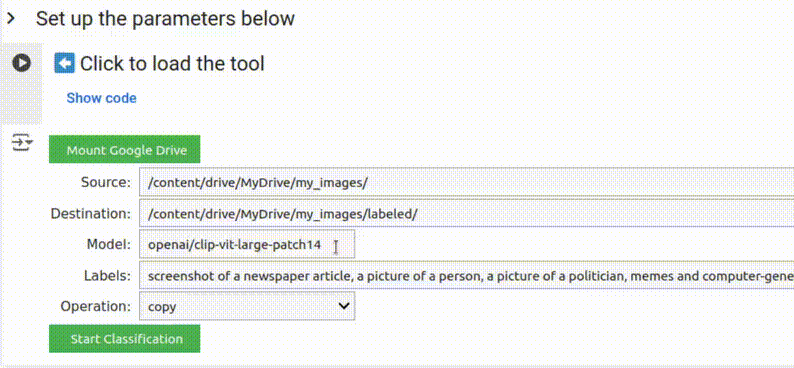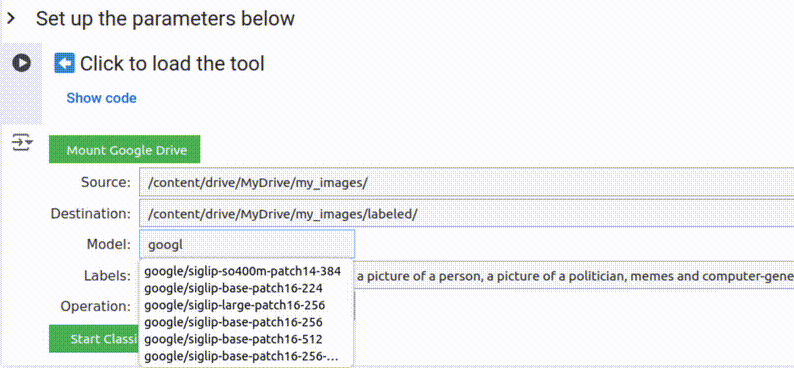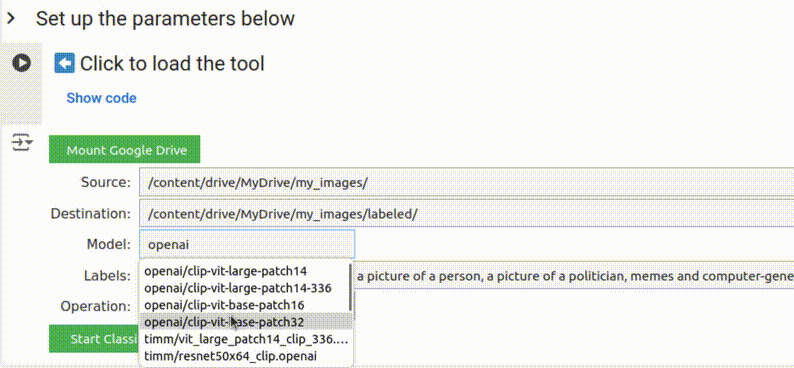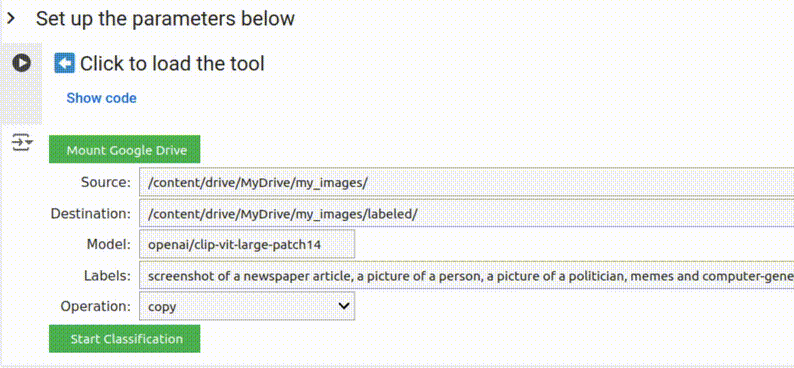
Você deve ver cinco campos de formulário que já foram preenchidos com valores padrão. Se você apenas quer uma ideia rápida do resultado gerado por esta ferramenta, você pode pular para o Passo 7 e executá-la imediatamente. Caso contrário, continue lendo.
2. Adicione suas próprias imagens (ou use as nossas)
O primeiro campo que você precisa preencher é o diretório de origem, que é onde as imagens que você deseja classificar estão armazenadas.
Para os propósitos deste tutorial, fornecemos um conjunto de amostra com 32 imagens, de uma investigação anterior da Bellingcat sobre grupos QAnon no Telegram, como diretório de origem padrão.
No entanto, se você deseja usar sua própria coleção de imagens, faça o upload das imagens para uma pasta no seu próprio Google Drive e clique no botão Mount Google Drive (Montar Google Drive) para dar acesso do Google Colab ao seu Google Drive. (Isso não concederá acesso à Bellingcat ou a qualquer outro usuário aos seus arquivos ou dados.)
Obtenha o caminho da pasta de imagens clicando com o botão direito do mouse na pasta relevante no gerenciador de arquivos e selecionando Copy path (Copiar caminho), depois cole-o no campo Source (Fonte).
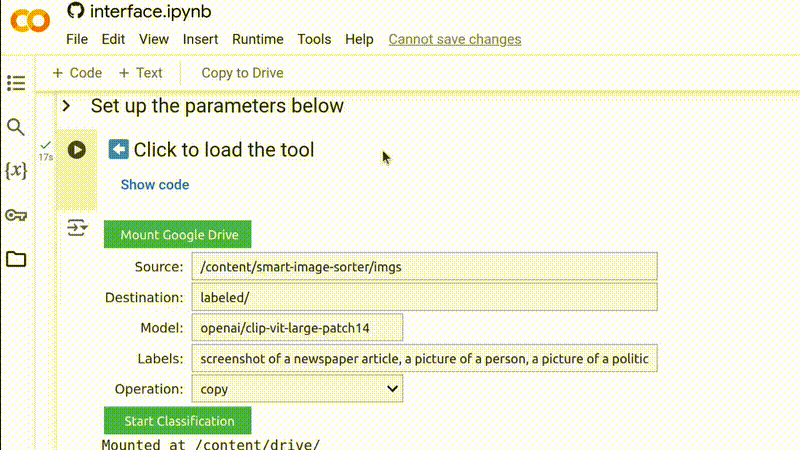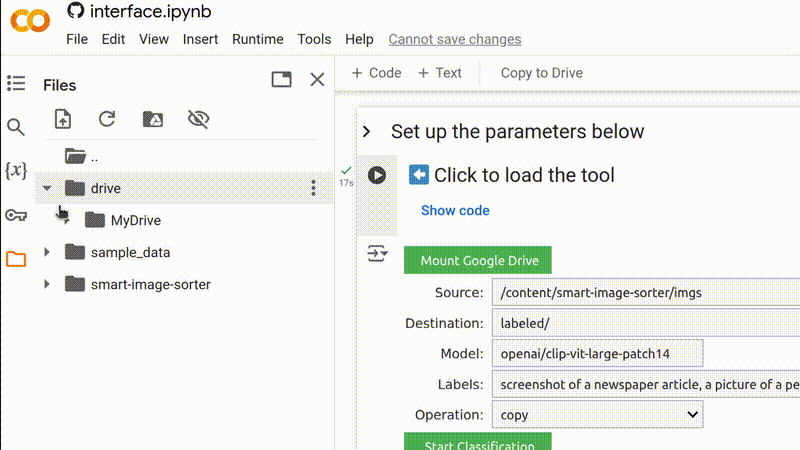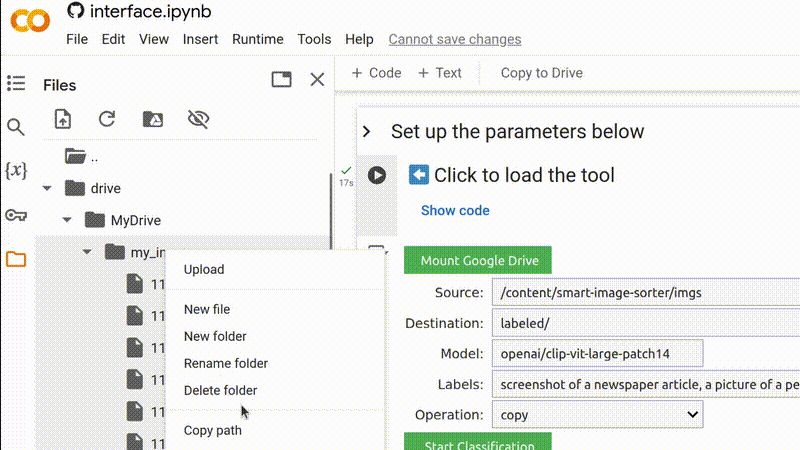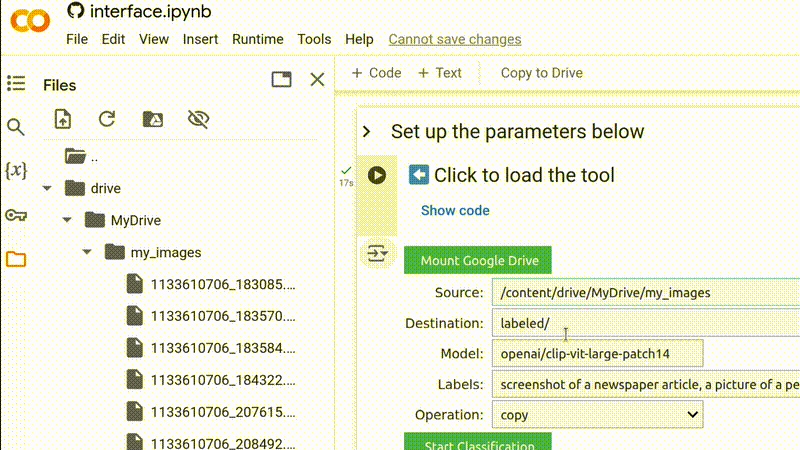
Copie o caminho para a pasta relevante no seu Google Drive e cole-o no campo para o diretório de origem.
Observação: Conectar seu Google Drive não funcionará se sua conta do Google fizer parte do Programa de Proteção Avançada, pois isso bloqueia a maioria dos aplicativos e serviços não-Google de acessar dados como seu Google Drive. Se você não conseguir conectar o seu Drive, mas deseja salvar os resultados além da sua sessão do Google Colab, você pode executar a ferramenta localmente.
3. Diga à ferramenta onde salvar as imagens classificadas
Agora que você informou ao programa onde encontrar as imagens, você também precisa dizer a ele onde copiar ou mover as imagens depois que ele as tiver classificado.
Se você deseja salvar as imagens classificadas, é importante que você conecte seu Google Drive conforme explicado no passo anterior. Caso contrário, você ainda pode executar o programa e ver como o modelo classifica as imagens, mas a saída desaparecerá ao final da sua sessão no Google Colab.
Uma vez que você tenha conectado seu Google Drive, você pode copiar e colar o caminho de uma pasta existente do gerenciador de arquivos, ou criar uma nova pasta digitando seu nome no final de um caminho existente.
Certifique-se de usar um local do Google Drive (começando com /content/drive/) como a
pasta de destino se você deseja que os resultados sejam acessíveis além da sua
sessão atual do Google Colab.
4. Escolha um modelo
O Smart Image Sorter utiliza o modelo de classificação de imagens sem supervisão mais baixado na Hugging Face como modelo padrão. No momento em que este tutorial foi escrito, era o “clip-vit-large-patch14“, um modelo baseado em CLIP da OpenAI. Você pode alterar isso para qualquer outro modelo disponível na Hugging Face.
Até a tradução deste tutorial, a Hugging Face possuía mais de 590 modelos de classificação sem supervisão disponíveis.
Embora o CLIP seja suficiente na maior parte das vezes, você pode querer experimentar um modelo diferente se não estiver obtendo os resultados desejados ou para casos de uso mais específicos. Por exemplo, se você deseja geolocalizar imagens, sugerimos experimentar o StreetCLIP definindo o campo do modelo como geolocal/StreetCLIP e utilizando países, regiões ou cidades como rótulos candidatos. Você encontrará mais dicas sobre como escolher um modelo mais adiante.
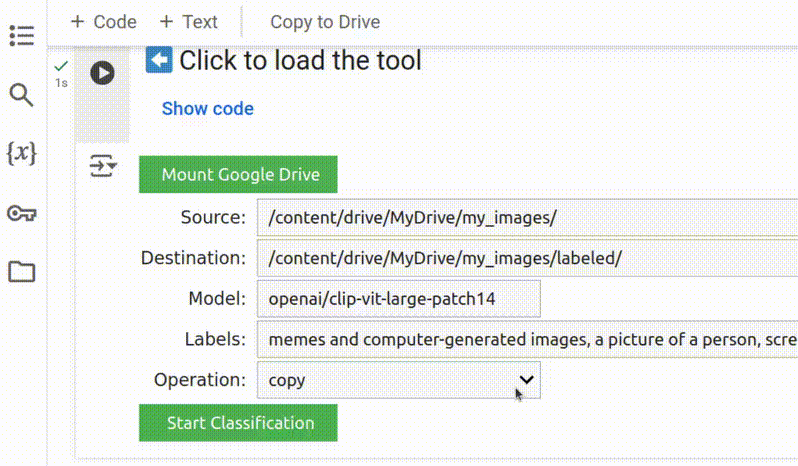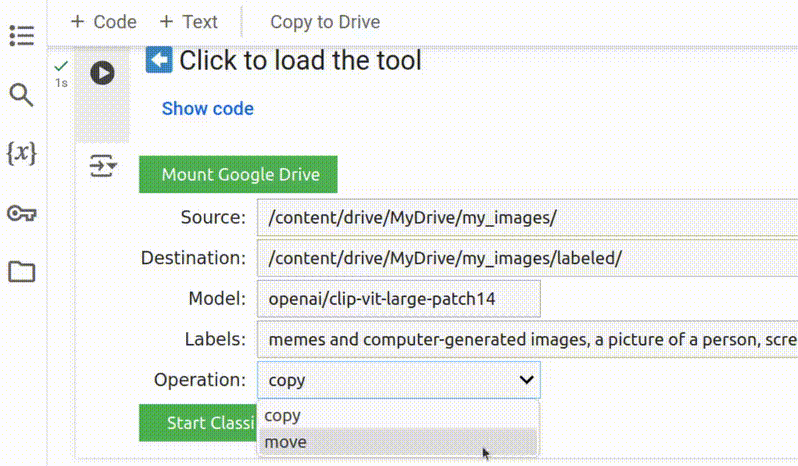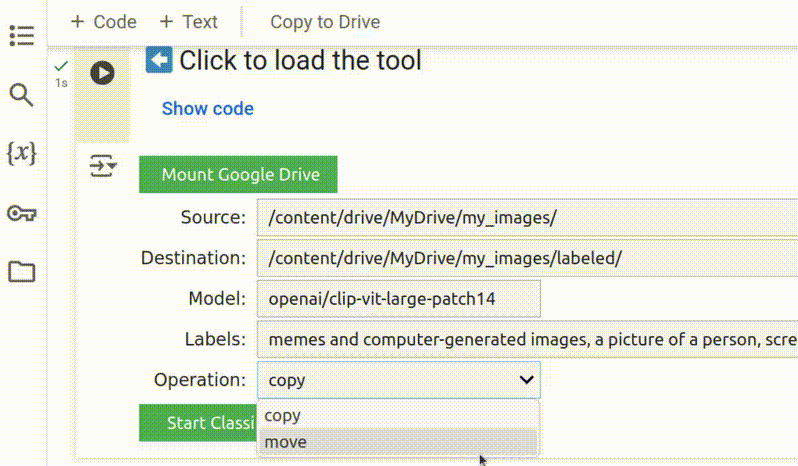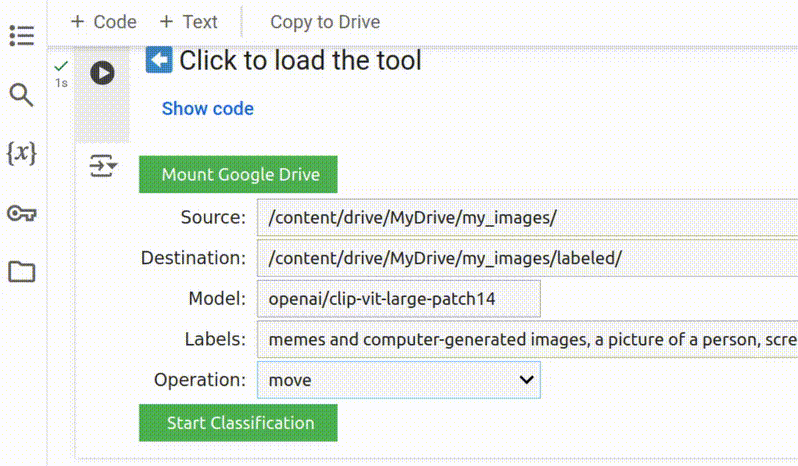
5. Adicionar Rótulos
Rótulos são as categorias que o modelo utilizará para classificação. Esta é uma etapa muito importante, pois o modelo sempre atribuirá um rótulo a cada imagem no seu conjunto de dados. Por exemplo, se você incluir apenas rótulos para “pessoas” e “animais”, mas der a ele uma imagem de uma casa, ele categorizará essa imagem sob o rótulo que ele considera que corresponde melhor. Portanto, os rótulos devem ser abrangentes, cobrindo praticamente todas as imagens possíveis no conjunto de dados, e não devem se sobrepor. Você encontrará mais dicas sobre como escrever rótulos eficazes mais adiante.
Os rótulos devem ser curtos, descritivos e separados por vírgulas.
6. Decida se vai copiar ou mover as imagens
Por padrão, a ferramenta copia os arquivos para a pasta de destino. Recomendamos esta configuração para que você possa verificar os resultados em relação às imagens originais. No entanto, você também pode alterar a configuração de Operation (Operação) para mover as imagens da fonte para a pasta de destino, o que pode economizar algum espaço de armazenamento.
Escolher copy (copiar) como operação garante que você não perca suas imagens originais,
mas move (mover) pode economizar algum espaço de armazenamento.
7. Consiga suas imagens organizadas!
Quando você tiver preenchido todos os campos, clique no botão verde Start Classification (Iniciar Classificação) para executar o programa.
A ferramenta exibirá algumas mensagens do sistema enquanto carrega o modelo e faz previsões. No final, ela deve exibir a mensagem: Classification finished (Classificação concluída).
Uma vez que isso seja feito, você poderá encontrar suas imagens organizadas na pasta de destino que você especificou.
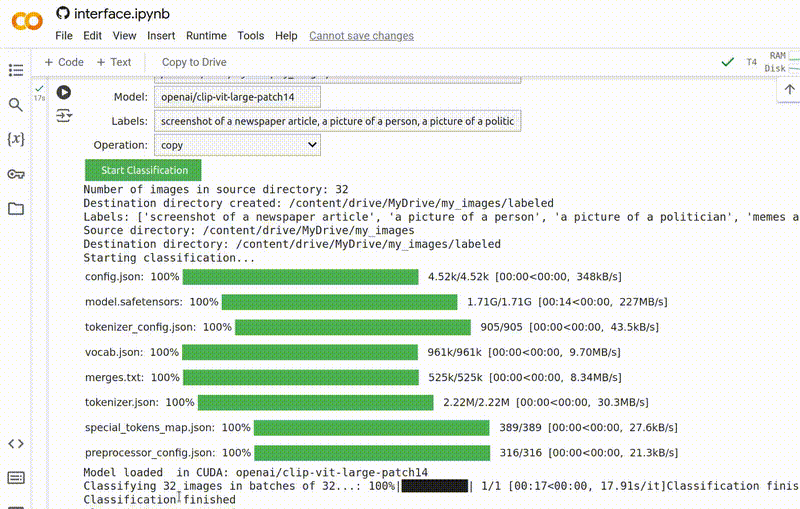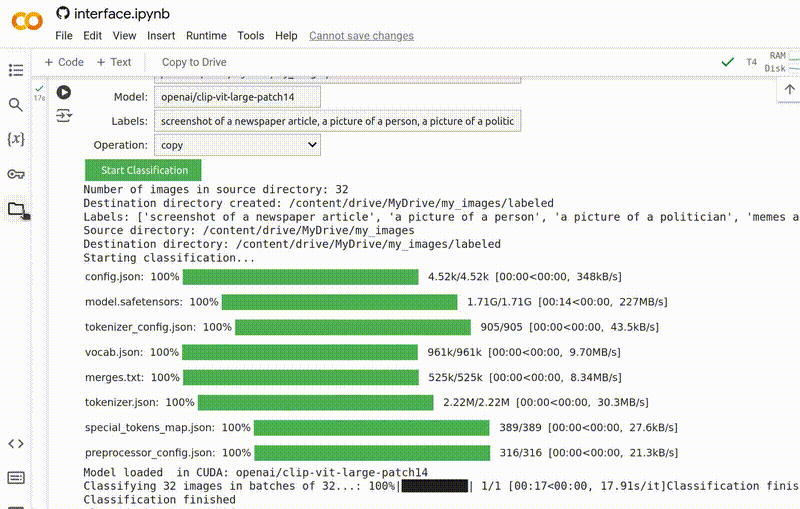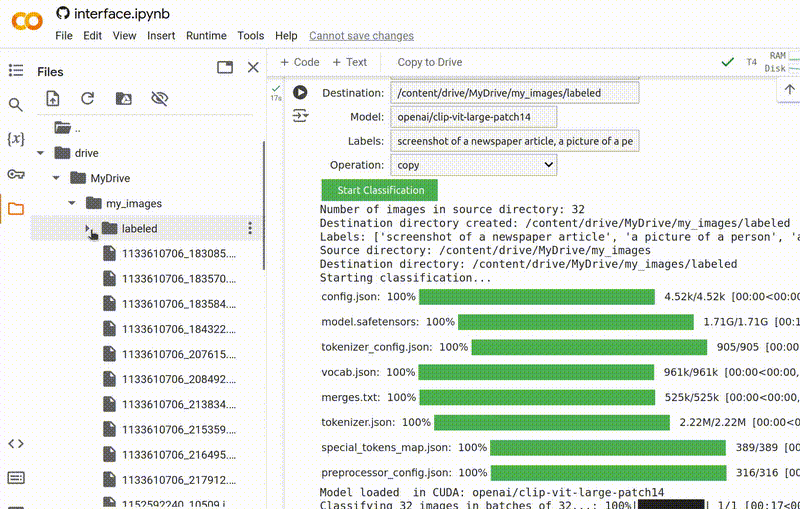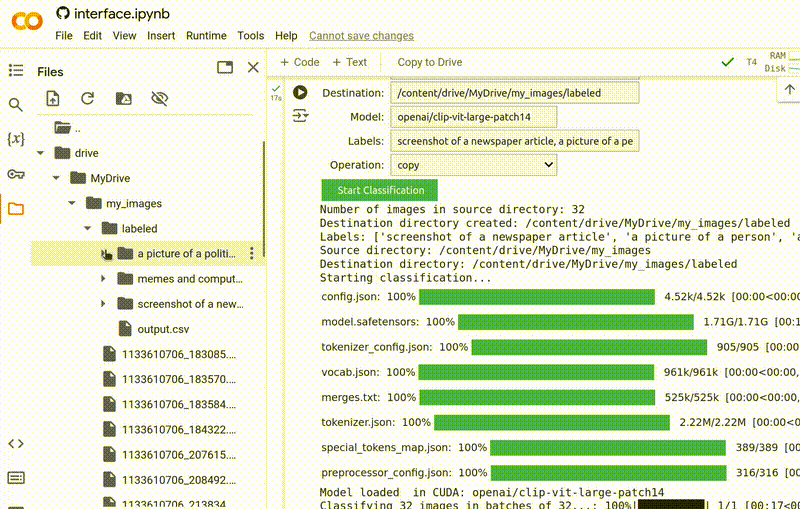
Quando a ferramenta terminar de executar, você deve encontrar as imagens organizadas dentro da pasta de destino especificada.
Executando a ferramenta localmente
Em alguns casos, você pode querer executar o Smart Image Sorter localmente em vez de no seu navegador – como por exemplo se você estiver lidando com imagens sensíveis ou confidenciais que não deseja fazer upload online, ou se você não conseguir montar o seu Google Drive.
Para fazer isso, você pode baixar o notebook do repositório no GitHub e executá-lo na sua máquina, usando seus diretórios locais como pastas de origem e destino. Você pode encontrar instruções sobre como usar a ferramenta diretamente pela linha de comando ou usando o Jupyter Notebook – uma ferramenta de código aberto que permite executar notebooks localmente – no arquivo README do repositório.
Avaliando os Resultados
Agora que você tem suas imagens organizadas, você vai querer avaliar os resultados.
Para coleções pequenas de imagens, deve ser fácil o suficiente inspecionar os resultados verificando as imagens em cada subdiretório. Para um conjunto de dados maior, você pode escolher uma amostra aleatória de imagens e categorizá-las manualmente, e depois executar o Smart Image Sorter para ver o desempenho geral e a precisão do modelo para cada classe.
Espera-se que a ferramenta classifique seus arquivos de imagem da maneira correta. No entanto, se isso não acontecer, você pode experimentar diferentes rótulos e modelos.
A biblioteca Hugging Face é um bom ponto de partida para começar a explorar outros modelos de IA de código aberto. Até a data de tradução deste tutorial, ela apresentava mais de 590 modelos para classificação de imagens zero-shot, com mais sendo adicionados continuamente. Você pode filtrar esses modelos para ver os mais recentes ou os que estão em alta.
Os nomes dos modelos geralmente nos dão pistas sobre suas características específicas. Por exemplo, o ViT-Base-Patch16-224 refere-se à versão “base” de um modelo de Vision Transformer (ViT). Isso sugere que ele tem menos parâmetros e é mais eficiente computacionalmente, mas menos complexo do que uma versão “grande” do mesmo modelo. Este modelo processa imagens com uma resolução de 224×224 pixels, que são divididas em segmentos menores ou “patches” de 16×16 pixels. Geralmente, quanto menor o “tamanho do patch”, mais detalhada é a análise que o modelo pode realizar, pois ele captura detalhes mais finos dentro da imagem
Você também pode querer explorar modelos específicos para determinadas tarefas. Como observado anteriormente, investigações visuais envolvendo geolocalização de imagens podem fazer uso do StreetCLIP, que foi treinado para prever países, regiões e cidades. Outros modelos são úteis para investigações em determinadas línguas: o AViLaMa se concentra em línguas africanas, e há várias opções para texto chinês que podem ser facilmente encontradas na Hugging Face.
A qualidade dos seus rótulos é outro fator importante. Um artigo publicado em 2021 indica que pequenas mudanças na formulação podem resultar em grandes diferenças no desempenho. Em um dos experimentos, os pesquisadores conseguiram um aumento de 5% na precisão apenas adicionando o artigo indefinido “um” antes do nome da classe.
Dicas para escrever rótulos eficazes
• Conheça seus dados: Comece obtendo uma ideia aproximada dos temas mais recorrentes na sua coleção de imagens, inspecionando-as aleatoriamente, se possível. Lembre-se de que o modelo sempre atribuirá um dos rótulos candidatos a uma imagem. Se seus rótulos candidatos forem “edifícios” ou “veículos” e você apresentar uma foto de frutas como a imagem de entrada, o modelo ainda escolherá uma das opções disponíveis, mesmo que nenhum dos rótulos seja apropriado. Assim, você deve escolher um conjunto de rótulos que possa descrever todas as imagens potenciais na sua coleção;
• Escolha rótulos distintos: Como esses modelos medem a distância semântica entre a imagem de entrada e cada rótulo fornecido, queremos evitar rótulos sobrepostos. Garanta que seus rótulos não sejam muito semelhantes uns aos outros, como “exército” e “soldado”;
• Adicione contexto: Modelos de classificação sem supervisão se beneficiam de rótulos com contexto adicional relevante para a tarefa. Por exemplo, se você deseja classificar imagens de armamento, em vez de usar apenas “AK-47” como um rótulo, você poderia tentar inserir texto como “AK-47, um tipo de arma de fogo” ou “Uma foto de uma AK-47”. Da mesma forma, tente “uma foto de uma pessoa” em vez de “pessoas”. Bons rótulos para classificação de imagens sem supervisão são mais semelhantes a descrições curtas do que categorias de uma única palavra;
• Mantenha-os curtos: Embora você deva adicionar contexto, muito dele pode confundir o modelo. Sugerimos manter seus rótulos com menos de 80 caracteres, mas uma descrição de menos de dez palavras deve ser suficiente na maioria dos casos;
• Evite palavras com múltiplos significados: Use termos precisos para definir claramente as categorias candidatas e evite palavras vagas ou ambíguas. Lembre-se de adicionar contexto para lidar com casos em que a mesma palavra pode ter múltiplos significados;
• Use terminologia comum: Palavras amplamente utilizadas e termos comuns são preferidos. Jargões, gírias ou termos específicos de uma região podem ser mais difíceis para o modelo entender, pois tais palavras podem não aparecer tanto nos dados de treinamento dele;
• Comece de forma ampla e reduza conforme necessário: Para tarefas de categorização complexas, uma boa estratégia seria escolher categorias amplas e depois repetir a classificação para restringir as imagens em subcategorias, se necessário. Por exemplo, após classificar arquivos de imagem com categorias como fotos ou capturas de tela, você pode repetir o processo para fotos, classificando-as como imagens de interiores ou exteriores. Se você estiver usando nosso notebook, basta substituir a pasta de origem da segunda execução pelo diretório de destino usado na primeira execução.
Limitações e Alternativas
Como qualquer aplicativo, o Smart Image Sorter não é perfeito nem necessariamente a melhor ferramenta para todos os casos de uso.
Embora a classificação automática de imagens possa acelerar investigações visuais, ela não substitui a inteligência humana. Na maioria dos casos, você ainda precisará de alguém para inspecionar manualmente os resultados para corrigir quaisquer classificações incorretas e obter insights a partir dos resultados.
Além disso, todos os modelos de IA refletem os vieses e limitações de seus dados de treinamento. A tecnologia de reconhecimento facial apresenta menor precisão na identificação de mulheres de pele mais escura, por exemplo, porque seus conjuntos de dados de treinamento são desproporcionalmente brancos e masculinos. Da mesma forma, a precisão dos modelos de classificação sem supervisão tende a diminuir com rótulos em línguas diferentes do inglês devido à falta de dados de treinamento suficientes.
Como os modelos de classificação zero-shot são modelos gerais, eles tendem a ter dificuldades em domínios especializados que exigem conhecimento contextual detalhado. Por exemplo, eles não têm sido muito eficazes em identificar memes com mensagens de ódio que visam indivíduos ou comunidades vulneráveis.
Texto escrito nas imagens também pode interferir nos rótulos previstos. Experimentos realizados por pesquisadores da OpenAI em 2021 indicam que, em alguns casos, os modelos baseados em CLIP podem ser enganados simplesmente colocando tags manuscritas sobre os objetos.
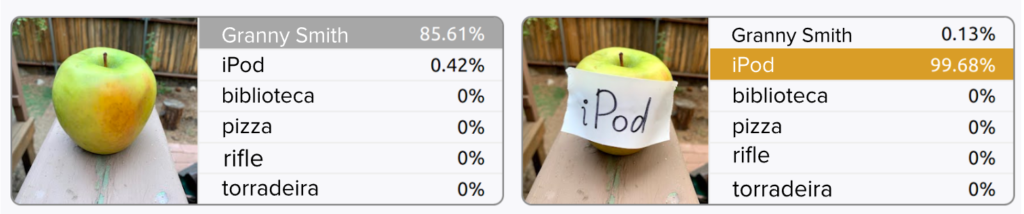
Experimentos mostram como o texto na imagem de entrada pode afetar as previsões
do modelo. de Goh et al., ‘Multimodal Neurons in Artificial Neural Networks‘,
Distill, 2021, sob a licença CC-BY 4.0, traduzida pela Escola de Dados.
Se você não conseguir os resultados desejados com a classificação de imagens zero-shot, talvez queira explorar alternativas. Por exemplo, você pode rotular manualmente algumas imagens e tentar a classificação de imagens com poucos exemplos – um método onde você fornece ao modelo um pequeno número de exemplos para aprender – ou até mesmo treinar um modelo “tradicional” de classificação de imagens, caso tenha dados rotulados suficientes. No entanto, essas alternativas estão fora do escopo deste guia, pois exigem mais recursos e expertise, enquanto a abordagem que delineamos aqui visa tornar a classificação de imagens por IA acessível a todas as pessoas.
Para ir além…
Se você tem um conhecimento mais avançado, pode contribuir com a ferramenta sugerindo melhorias, tradução de recursos ou até mesmo inclusão de novas funcionalidades. Acesse o repositório da ferramenta e divirta-se!
Este tutorial te ajudou em alguma tarefa? Conta pra gente! É importante para nós saber como nossos tutoriais tem sido úteis no seu dia a dia. Em caso de dúvidas, utilize o Fórum de Jornalismo de Dados.








