
Tutorial baseado na atividade de mesmo nome facilitado por Anicely Santos na
Conferência Brasileira de Jornalismo de Dados e Métodos Digitais (Coda.Br 2023).
Quando pensamos em projetos orientados por dados, é comum inicialmente considerarmos os famosos passos de Extraction, Transformation e Load (Extração, Transformação e Carregamento), conhecidos pela sigla ETL. Esta é uma etapa crucial, afinal, não é possível trabalhar com dados desorganizados. Contudo, tão importante quanto essa fase é a maneira como uma pessoa que talvez não tenha conhecimento algum em dados irá compreender o que eles significam. É nessa fase que podemos introduzir o Streamlit.
Streamlit é um framework de código aberto, desenvolvido em Python, que se destina à criação de aplicações voltadas para ciência de dados e aprendizado de máquina. Com essa ferramenta, é possível desenvolver uma aplicação em um intervalo de tempo muito curto, desde que se possua conhecimento básico de Python.
Neste tutorial, iremos criar uma aplicação que permite localizar pontos de coleta de material reciclável, utilizando dados do portal de dados abertos da cidade do Recife, em Pernambuco. Ao final, deveremos ter um projeto semelhante ao apresentado abaixo.
Antes de começar, certifique-se que você possui os conhecimentos a seguir:
• Python básico;
• Noções do uso do Terminal;
• Noções do uso do VSCode.
Esses conhecimentos serão utilizados ao longo do tutorial.
Então vamos começar!
Preparando o ambiente
Existem várias maneiras de realizar a instalação do Streamlit. Neste tutorial, optaremos por utilizar um ambiente virtual da distribuição Anaconda. Um ambiente virtual é essencialmente um espaço onde todas as instalações ou alterações efetuadas não afetarão o sistema operacional do computador. As operações ocorrem de forma isolada e, caso não deseje mais utilizar o que foi configurado nesse ambiente, você pode simplesmente excluí-lo ou, ainda, criar múltiplos ambientes para diferentes projetos.
Instalando o Anaconda
Acesse o site da Anaconda e siga a instalação de acordo com o seu sistema operacional. O Anaconda já vem com o Python mais recente instalado, mas você tem a liberdade de instalar a versão com a qual se sinta mais confortável dentro do seu ambiente virtual. Veremos isso melhor a seguir.
Criando um ambiente virtual
Uma vez instalado, abra a aplicação e clique em Environments (ambiente de desenvolvimento).
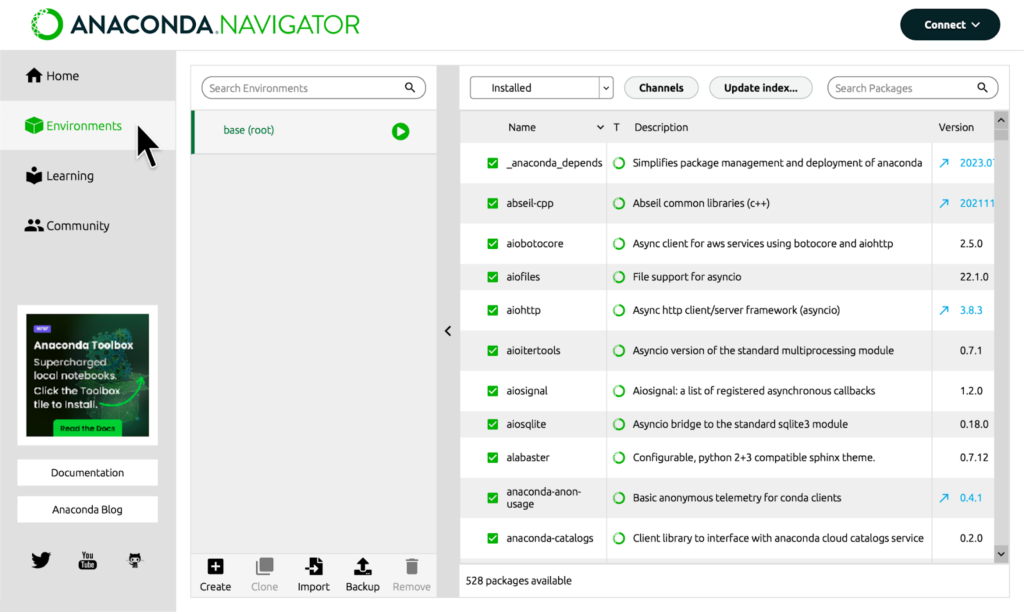
Fonte: documentação do Anaconda
Você verá na coluna do meio um ambiente chamado base(root), este é o ambiente virtual do Anaconda que está ativado no momento. Queremos criar um novo para fazer nossa aplicação. Para isso, clique em Create na parte inferior da página.
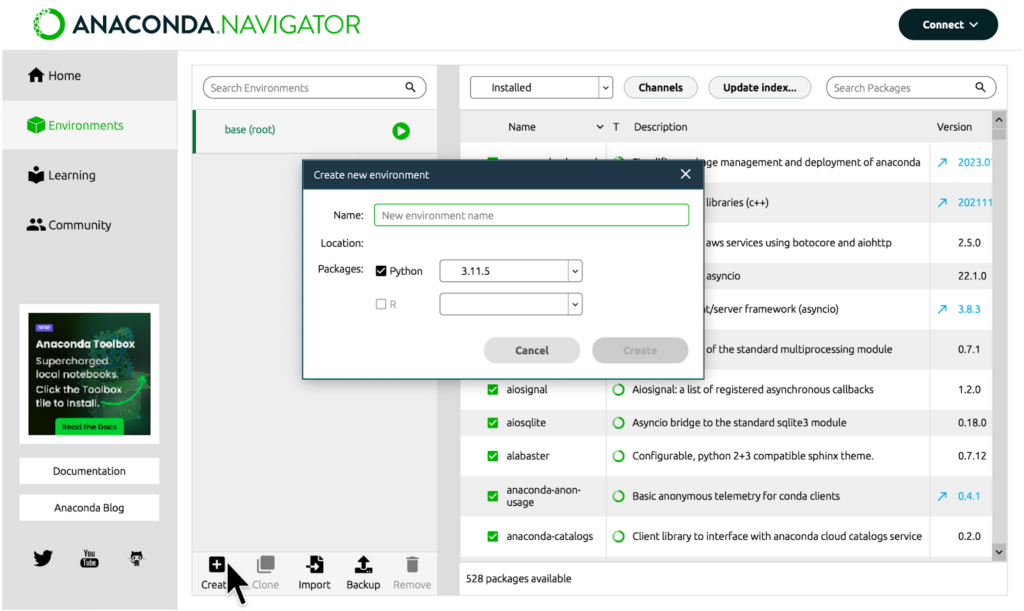
Fonte: documentação do Anaconda
Será solicitado um nome (Name) e a versão Python a ser instalada no ambiente. Coloque o nome que quiser. Quanto a versão, neste tutorial utilizaremos o Python 3.10, mas você pode seguir com a que aparece por padrão ou instalar a que mais se sentir confortável para usar. Em seguida, dentro desta caixa, clique em Create novamente.
Ative seu ambiente
Uma vez criado o ambiente, ative o ambiente clicando na caixa com o nome que você colocou anteriormente. Quando ativado, aparecerá um botão com ícone de play (seta para direita). Clique nele e escolha Open Terminal.
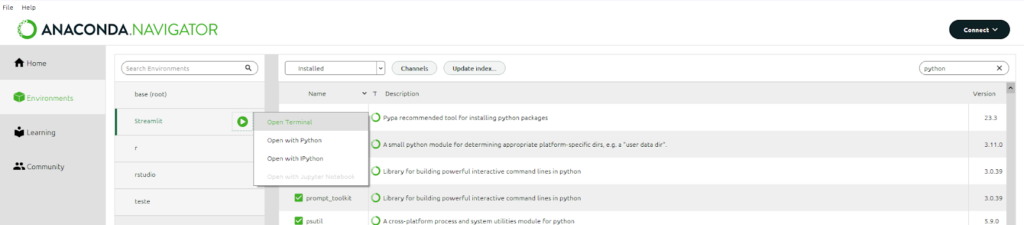
O ambiente do terminal irá abrir com o nome do ambiente que você criou entre parênteses e o caminho de arquivos onde armazenará tudo que você for instalado. Qualquer instalação que aconteça neste ambiente será restrito apenas a ele, ou seja, quando excluir o ambiente, também excluirá o conteúdo dele.
Instalando o Streamlit
No terminal que foi aberto, digite o comando pip install streamlit.
Ao terminar a instalação, para validar que tudo deu certo, digite o comando streamlit hello.Deve aparecer algo semelhante a imagem abaixo.
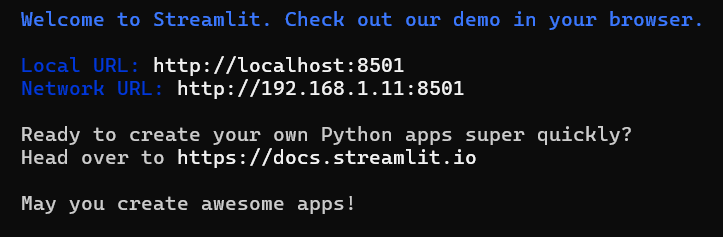
Se o seu navegador não abrir automaticamente, copie e cole o endereço do Local URL no seu navegador. Irá aparecer uma aplicação de demonstração do Streamlit. Explore o quanto quiser e depois volte para continuarmos o tutorial.
Criando nossa aplicação
Vamos utilizar o VSCode como ambiente de desenvolvimento da aplicação. Até terminar, vamos precisar rodar a aplicação algumas vezes para visualizar como ela está ficando. Esta execução será feita no terminal do VSCode.
Feche o terminal.
Clique em Home (acima de Environments) e no painel de aplicações que abrirá, procure por VSCode. A versão utilizada neste tutorial é 1.92.1. Clique em Launch para abrir.
Navegue no terminal do VSCode até a pasta com o nome do ambiente virtual que você criou.
Dentro do ambiente virtual, crie uma pasta chamada Coleta (pode colocar o nome que quiser), este será o nome do nosso projeto e é nela que reuniremos os arquivos relacionados ao mesmo.
Após criar, abra a pasta dentro do VSCode. Vamos organizar a estrutura.
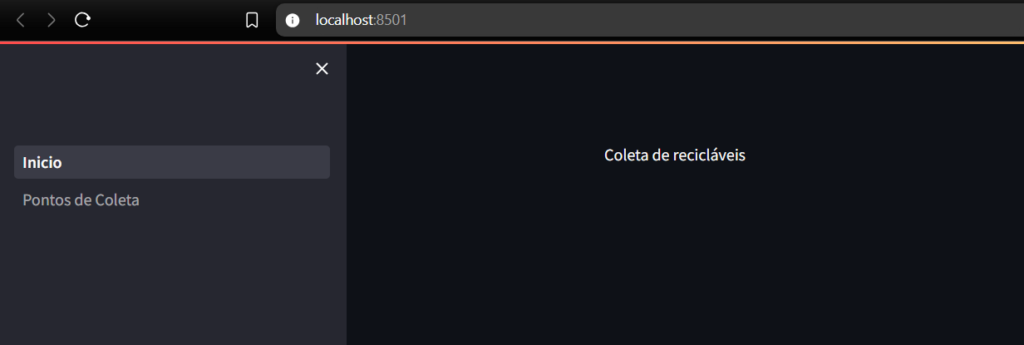
No projeto modelo observamos que do lado esquedo da página inicial tem duas opções: Inicio e Ponto de coleta.
O Inicio funciona como a página de abertura do site. Já o Ponto de coleta funciona as páginas internas do site. Vamos fazer o Streamlit entender esta organização.
Para a página Inicio crie um arquivo com o nome 1_Inicio.py dentro da pasta Coleta.
Para a página Ponto de coletas crie uma pasta dentro da pasta Coleta com o nome pages.
Dentro da pasta pages crie um arquivo com o nome 2_Pontos de coleta.py.
A pasta pages sinaliza para o Streamlit que tudo que houver dentro dela são páginas secundárias dentro do projeto. A pasta precisa ter este nome obrigatoriamente. Assim como os arquivos precisam ter os números no início para que a ferramenta entenda a ordem.
Sua estrutura deve estar semelhante a esta abaixo.
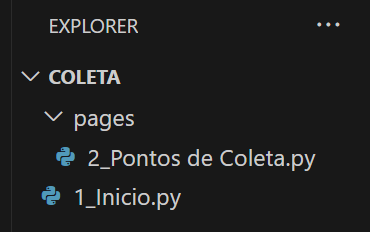
Vamos agora trabalhar na página inicial.
Personalizando a página inicial
Com os arquivos do projeto organizados, vamos trabalhar na página inicial. Clique no arquivo 1_inicio.py e o arquivo irá abrir do lado direito. O script desta página será escrito dentro deste arquivo.
Carregando dados e bibliotecas
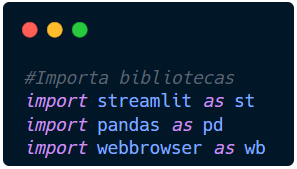
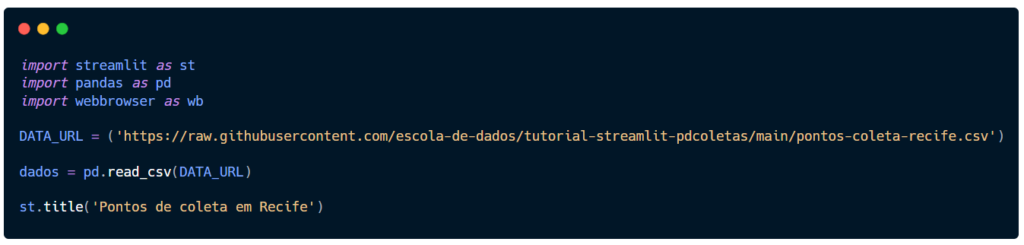
Logo no início do arquivo vamos importar todas as biblioteca que utilizaremos. Ao longo do tutorial, você verá a utilidade de cada uma delas. Também chamaremos pelos nomes simplificados (st, pd e wb) para facilitar a leitura no código.
Seu código deve ser semelhante a este abaixo.
Se não fez antes, pare um minuto agora e dê uma olhada na documentação. Você vai perceber que os recursos do Streamlit são muito simples, geralmente tudo que precisa ser utilizado levam o próprio nome.
Vamos testar escrever na tela.
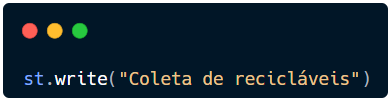
Vejamos um exemplo: para escrever na tela utilizamos st.write(“Coleta de recicláveis”). Viu?! O nome significa exatamente o tipo de ação.
Seu código deve ser semelhante a este abaixo.
No terminal dentro do VSCode, escreva streamlit run nomedoarquivo.py, que no nosso caso o nome do arquivo será 1_Inicio.py . Lembre-se de estar no caminho correto do arquivo que deseja executar.
Se tudo deu certo, a mensagem abaixo deve aparecer no terminal e você será redirecionado para uma página que abrirá no seu navegador.
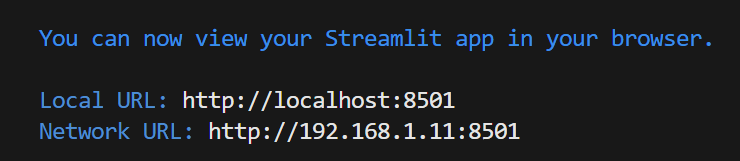
No navegador deve aparecer o seu projeto com a organização de páginas que indicado e a mensagem escrita dentro dos parênteses.
Super fácil, não é? Vamos adiante!
Agora vamos subir os dados em que trabalharemos.
Os dados utilizados neste tutorial já estão prontos para uso. Lembre-se que o Streamlit só é usado na etapa final do projeto, os dados já precisam estar prontos para uso.
A base pronta pode ser baixada neste repositório do GitHub.
Neste tutorial não iremos baixar, mas utilizar os dados diretamente do GitHub.
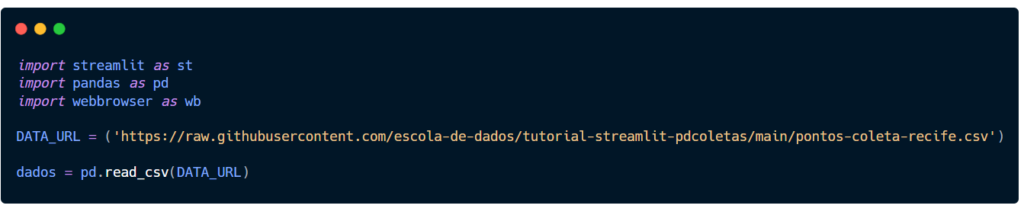
Crie a variável DATA_URL para armazenar o endereço dos dados. Lembre de colocar o link entre parênteses e entre aspas.

Utilizando o pandas, carregue sua base de dados, assim conseguiremos usá-los usando também esta biblioteca.
Crie a variável dados e leia os arquivos de DATA_URL utilizando pd.read_csv().
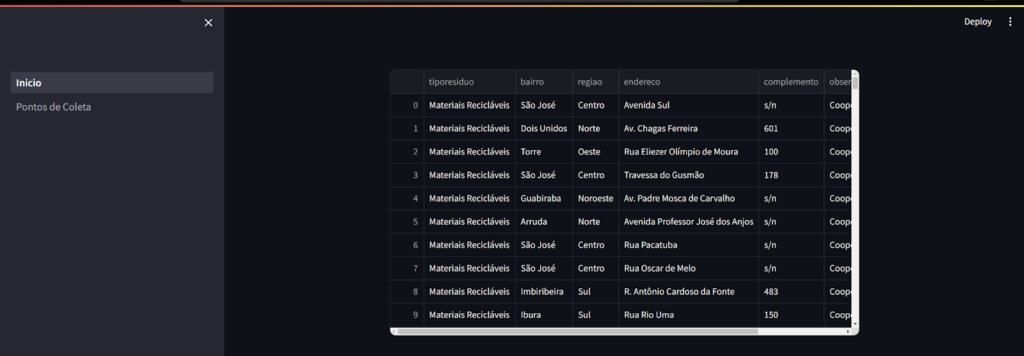
Se você quiser ter certeza que o carregamento deu certo, escreva na linha abaixo o nome dados e execute o arquivo no terminal.
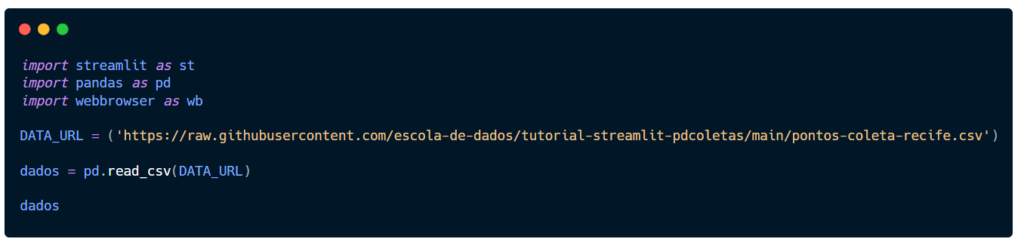
Na página do projeto no navegador, deve aparecer os dados carregados.
Agora que temos nossos dados carregados, seguimos com o nosso trabalho.
No projeto modelo a página inicial estruturalmente contém texto, gráfico e botões. Vamos iniciar com os textos.
Textos e formatações
Escrever no Streamlit é muito simples. Ali em cima você já experimentou utilizando o st.write. Existem outras maneiras de fazer isso.
Para textos longos usaremos Markdown por ter uma formatação fácil, mas você pode utilizar o que achar melhor.
Para o título vamos usar o st.title. Escreva o título que quiser.
Para utilizar recursos do Markdown a partir do Streamlit, basta chamar st.markdown e passar o conteúdo entre aspas dentro do parênteses, com as marcações que o Markdown indica.
Vamos incluir um subtítulo.
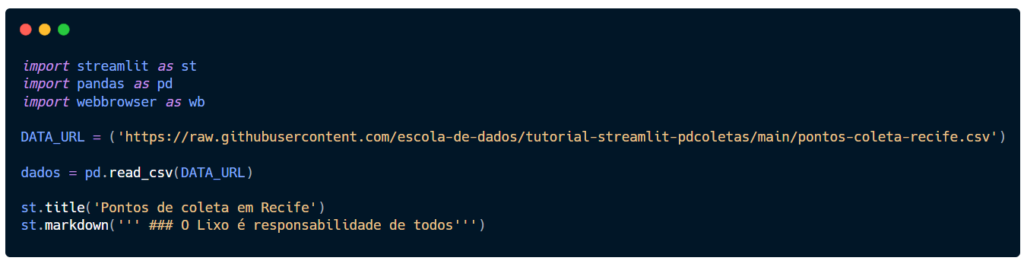
Tem mais texto, a lógica é a mesma. Tente você mesmo.
Execute o código e veja como está ficando.

Gráfico
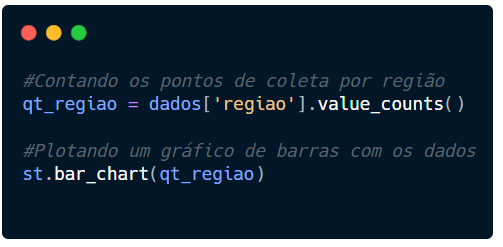
Os tipos de gráficos no Streamlit vão desde os mais simples, como gráficos de barras, até os mais avançados utilizando outras bibliotecas como Matplotlib. Vamos criar um gráfico de barras que sumarize os pontos de coleta por regiões no Recife.
Utilizando o Pandas, vamos organizar os dados para contar as regiões e salvar em uma variável que chamaremos qt_regiao.
Para contar, usaremos o value_counts().
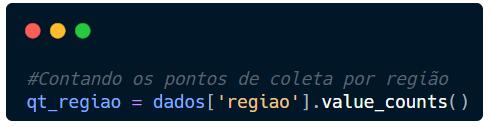
Agora com estes dados organizados, vamos colocar em um gráfico.
Você deve ter visto na documentação várias opções de gráfico. Aqui usaremos o bart_chart.
Chame o gráfico e passe os dados que deseja entre parênteses. Dá para personalizar bastante, fique a vontade para fazê-lo
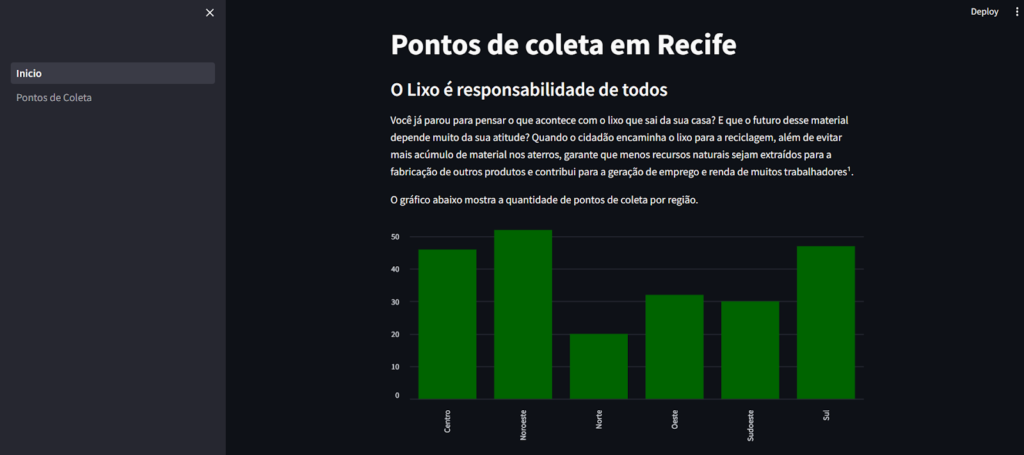
Quando executar o código aparecerá um gráfico simples, indicando as regiões em cada barra. Passando o mouse por cima, você verá a quantidade de pontos de coleta que existe em cada uma delas.
Para personalizar, vamos colocar a cor verde para combinar com a temática de reciclagem, incluindo color depois dos dados e passando o código da cor desejada. Para escolher uma cor você pode digitar “cor hex” ou “cor RGB” no Google, que ele retorna uma paleta de cores com os códigos.

Até aqui seu projeto deve estar com essa carinha.
Mapas
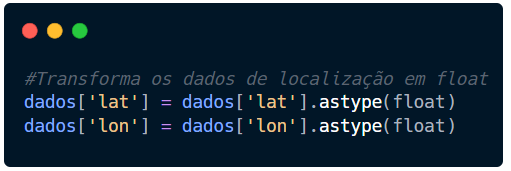
Não muito diferente do que já fizemos até aqui, é bem fácil utilizar este recurso. Temos várias bibliotecas que plotam mapas, como Folium.
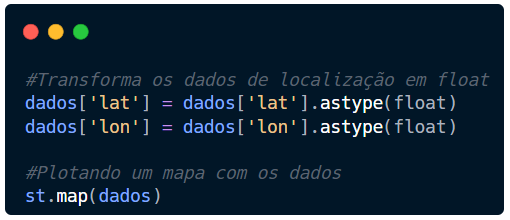
Nossa base possui as colunas lat (latitude) e lon (longitude), mas não estão no formato decimal (float). Vamos utilizar o astype do Pandas para esta transformação.
Com estes dados prontos, tudo que o st.map precisa é que passe os dados. “Automagicamente” ele identifica as colunas que possuem os dados necessários para esta plotagem.
Botões
Uma boa prática para botões que redirecionam para conteúdo externo é que o usuário acesse o conteúdo, mas não saia do site principal. Chegou a hora de usar o módulo webbrowser que já importamos anteriormente.
Vamos criar os botões dentro de uma estrutura de tabela. Isso ajudará a organizar a disposição deles na tela.
Precisamos de dois botões: um que redirecione para os dados no site de dados abertos do Recife e outro para os dados limpos no GitHub.
Vamos criar as variáveis col1 e col2 para representá-los dentro da tabela.
Atribuímos a eles o elemento tabela, passando st.columns(2). O 2 representa a quantidade de colunas que queremos nesta tabela, o equivalente a mesma quantidade de variáveis.
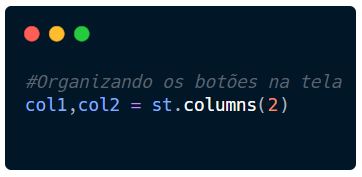
Agora estas duas variáveis podem “chamar” os atributos que st.columns possui.
Vamos usar o bottom e passar para ele toda informação que queremos que o botão tenha, ou seja, nome e link.
Criaremos as variáveis btn1 e btn2 e passaremos para elas o nome do botão e como o botão deve se dispor na tela. É a partir destas variáveis que também indicaremos qual ação ele deve fazer ao ser clicado.
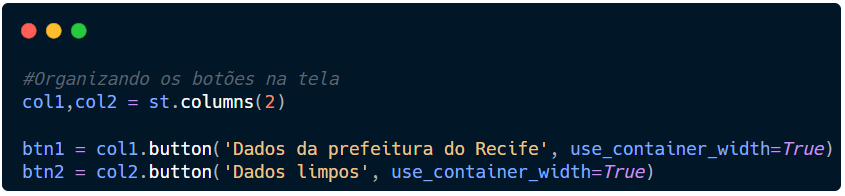
O use_container_with indica que o botão utilize todo o espaço disponível para aquela coluna. Por padrão, esse elemento vem False.
Agora, precisamos que os botões entendam duas coisas quando clicado: para onde devem ir e como isso deve acontecer.
O para onde tem a ver com o link que vai redirecionar o usuário para as páginas indicadas.
É no como deve acontecer que entra o webbrowser. Ele quem vai dizer que quando clicado, o link deve abrir em uma nova aba no navegador.
Essas coisas só devem acontecer SE alguém clicar no botão.
Vamos começar então utilizando um If para o btn1 e um if para o btn2.
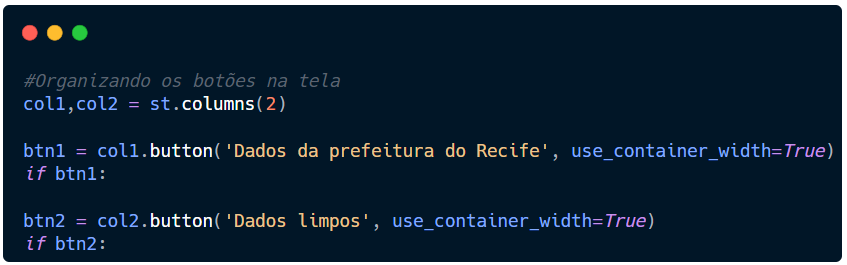
Agora, dentro do if vamos dizer que SE alguém clicar neste botão, abra uma nova aba com o link indicado. Para que abra uma nova aba, usaremos o open_new_tab()e dentro do parênteses, entre aspas, passaremos o link. Este recurso faz parte do Webbrowser.
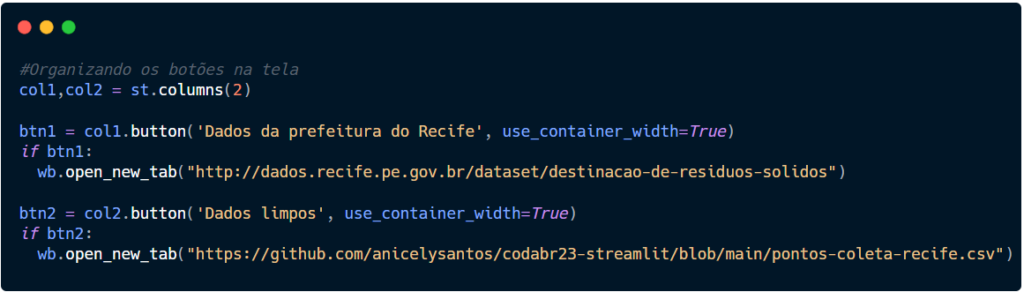
Execute e veja como está tudo até agora, levando em consideração que você incluiu mais texto.
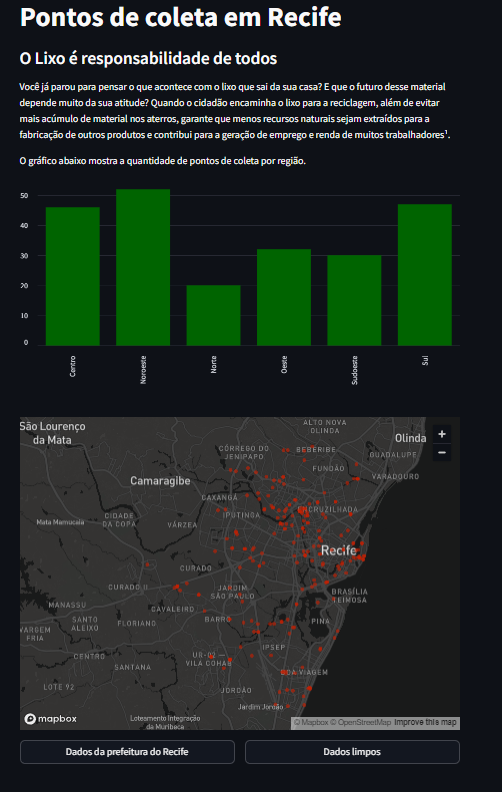
Aqui os scripts organizados de tudo que fizemos até o momento.
Terminamos a página inicial. Vamos para a segunda parte: a página de coletas.
Personalizando a página Pontos de Coleta
Todo código que faremos a partir daqui deve ser escrito no arquivo 2_Pontos de Coleta.py, que se encontra dentro da pasta pages. No entanto, continue executando no terminal apenas o arquivo principal (1_inicio.py).
Precisamos importar novamente as bibliotecas pandas e streamlit, não precisaremos da webbrowser.
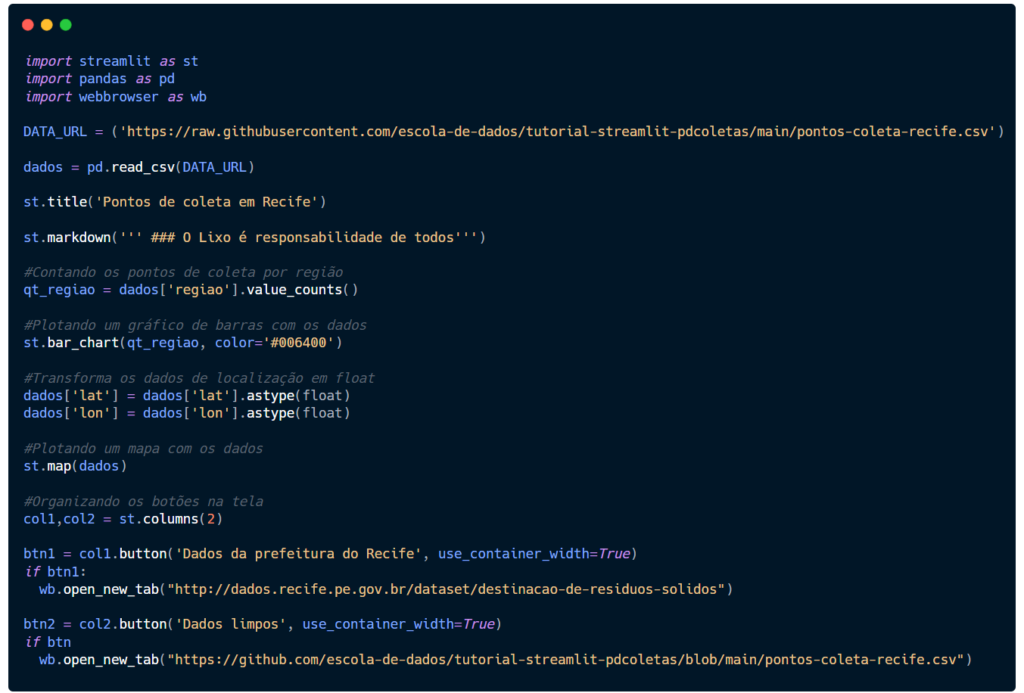
Vamos continuar utilizando a mesma base de dados. No Streamlit não precisa fazer a importação e leitura como na primeira página. É possível fazer uma espécie de “cache” onde ele recupera os dados carregados em outra parte da página. Vamos fazer isso!
No arquivo 1_inicio.py usaremos o session_states[]. Ele funciona como uma espécie de dicionário, onde você indica uma chave, no nosso caso chamaremos de dados e atribuímos um valor, que no caso é a variável dados onde a base está armazenada.
Seu código deve ser semelhante a este abaixo.
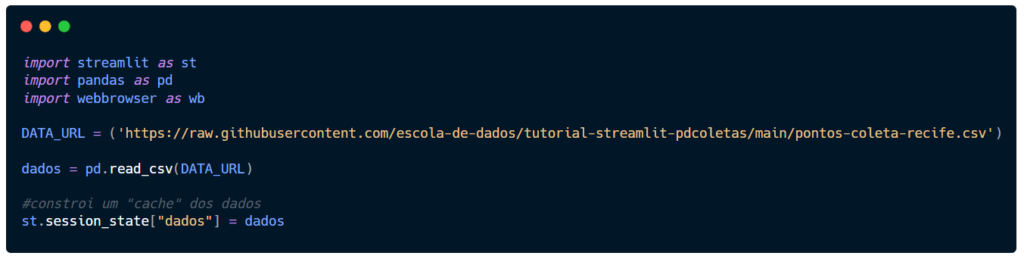
Pronto. No arquivo 2_Pontos de Coleta.py basta atribuir este pequeno script a uma variável, pois precisaremos fazer novas manipulações nos dados.
Seu script deve ser semelhante a este abaixo.
Para testar, escreva novamente o nome da variável embaixo (df_dados) e execute o arquivo.
Ao executar o arquivo, quando abrir no navegador sempre clique primeiro em Inicio e só depois clique na outra página que está recuperando os dados. Eles precisam carregar primeiro na página inicial, caso contrário dará erro.
Antes de reproduzir o que tem nesta página vamos entender.
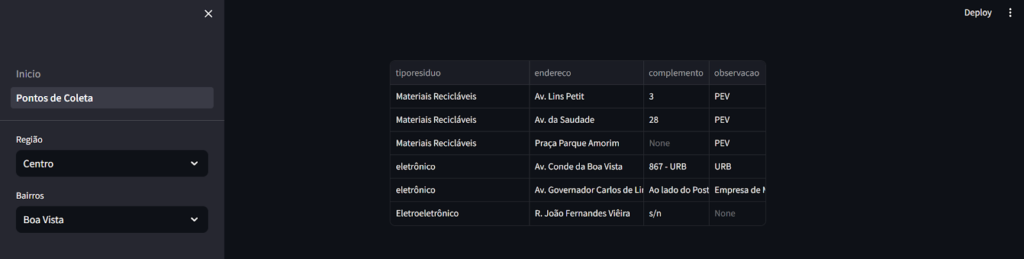
No centro da página temos uma tabela.
Do lado esquerdo, na área que chamamos de sidebar, temos dois filtros, Região e Bairros.
O filtro Região influencia o filtro Bairros, ou seja, à medida que você seleciona uma região, ele mostra no filtro de baixo todos os bairros relacionados aquela região e, quando selecionado um bairro, a tabela mostra todos os pontos de coletas que existem naquele bairro.
Pode parecer complicado, mas fazendo por etapas se torna bem simples. Vamos lá!
Filtro de Regiões
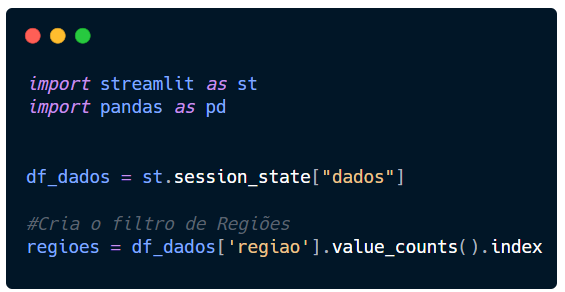
Primeiro vamos criar um filtro com o Pandas que nos traga apenas as regiões sem se repetir.
Criaremos a variável regioes que receberá o filtro da tabela selecionando apenas a coluna regiao (df_dados[‘regiao’]).
Para agrupar e saber a quantidade de pontos de coleta por região, usaremos novamente o value_counts().
No momento só precisamos dos nomes das regiões, então incluiremos o .index depois do value_counts().
Seu script deve ser semelhante a este abaixo.
Agora que temos as regiões, vamos colocá-las dentro do filtro.
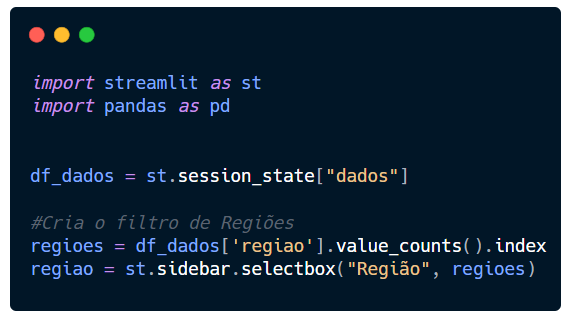
Observe que o filtro está na sidebar, então tudo que a gente quiser colocar lá primeiro chamamos sidebar e então a funcionalidade que queremos implementar, que no nosso caso é uma selectbox (caixa de seleção).
Como o outro filtro dependerá desse, precisamos criar uma variável que iremos chamar lá na frente. Vamos nomeá-lo de regiao e atribuir ao sidebar (que é onde queremos colocar) e em seguida a selectbox()(que é o recurso que queremos utilizar).
Entre parênteses na selectbox, vamos passar primeiro o nome da caixa entre aspas (Região) e em seguida a variável que tem esses dados (regioes).
Seu script deve ser semelhante a este.
Maravilha! Vamos para o próximo filtro.
Filtro de Bairros
Este filtro depende obrigatoriamente do filtro anterior. Logo, a variável regiao vai ser muito importante, pois é através dela que vamos conseguir que apareçam os bairros relacionados aquela região e consequentemente os pontos de coleta que estão naquele bairro. Vamos começar!
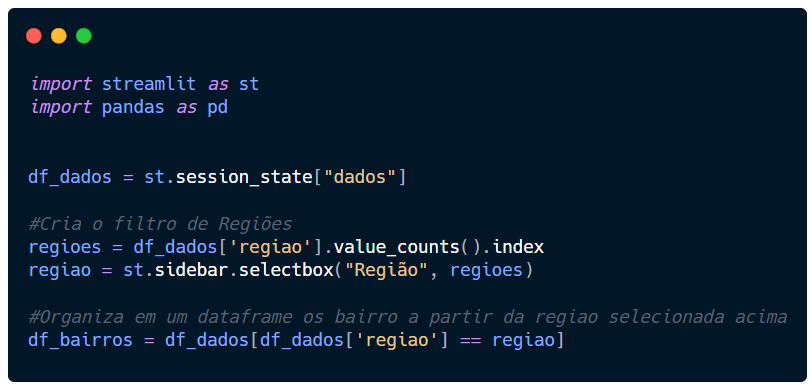
Primeiro, vamos criar a variável df_bairros que vai filtrar a base de dados (df_dados) e vai trazer apenas o bairro selecionado na selectbox, que está armazenado na variável regiao.
Seu script deve ser semelhante a este abaixo.
Pronto, agora é só repetir a lógica de script do filtro regiões para criar a selectbox de bairros. Esta parte você já sabe. Tente você mesmo! 🙂
Exibindo o resultado na tela
Agora a última etapa é mostrar a tabela com os pontos de coleta, de acordo com as informações que foram selecionadas nas selectbox Bairros.
Para fazer isso, vamos criar uma base de dados que filtre só estas informações. A ideia é muito semelhante à que usamos para as selectbox.
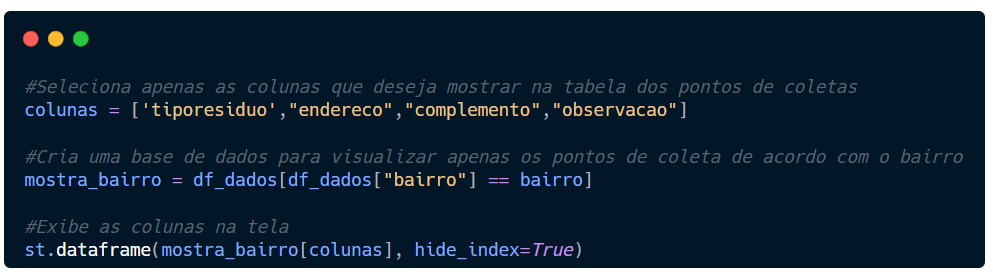
Vamos criar uma variável (mostra_bairros) e então filtrar os dados de df_bairros trazendo só o que foi selecionado.
Seu script deve ser semelhante a este.

Se você visualizar a base agora, vai mostrar todas as colunas.Nós não queremos que todas elas apareçam. Só algumas colunas nos interessam.
Vamos criar uma variável com o nome de colunas e, dentro dos colchetes, colocar só o nome das colunas que queremos que apareça.

Utilizando o recurso dataframe do Streamlit, passaremos entre parênteses a base de dados, filtrando apenas as colunas que queremos (mostra_bairro[colunas]) e usaremos o hide_index=True para inibir o índice dos dados.
Seu script deve ser semelhante a este.
Se você executar, deve ver uma tela semelhante a esta.
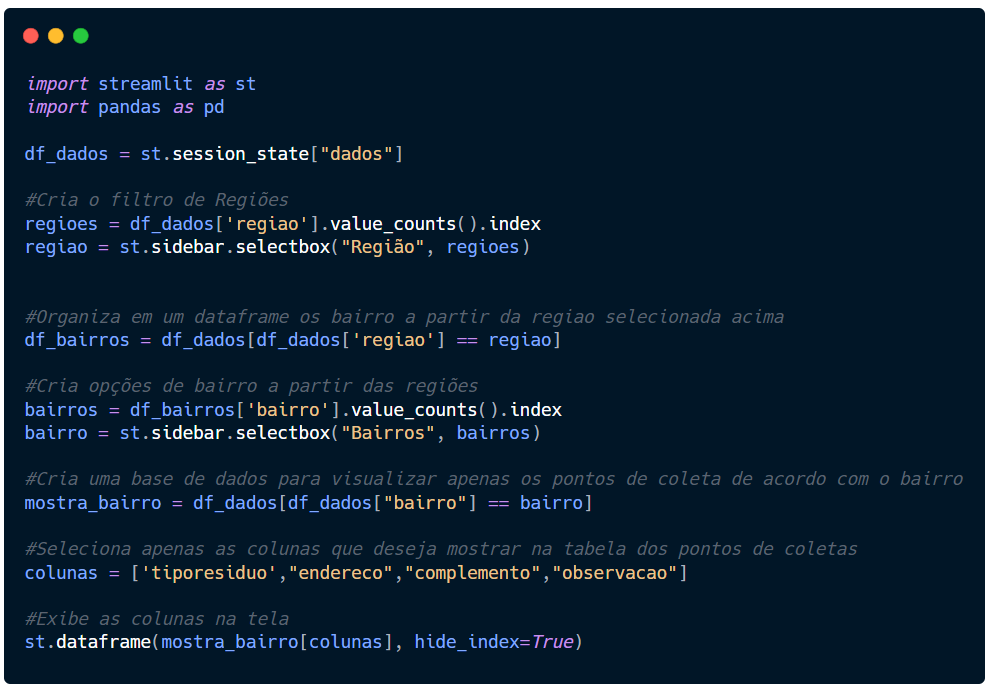
Agora, seu script completo da segunda página deve ser algo semelhante a este aqui.
Perfeito!
Você construiu uma aplicação usando o Streamlit. Parabéns!
Bônus
Emojis
Você deve ter percebido no projeto modelo que tem emojis tanto no título da aba no navegador, quanto do lado do nome de cada página na sidebar. Isso é super simples de fazer.
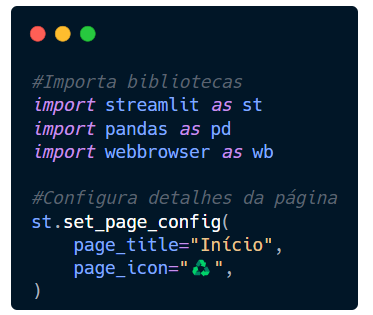
Para o título da aba no navegador, você pode usar o set_page_config, passando para ele o page_title e page_icon. No page_title indique o nome para aba entre aspas. No page_icon passe o emoji entre aspas.
Deploy
Durante todo o tutorial, o projeto era executado localmente. Mas é possível disponibilizar para todas as pessoas usarem.
Você precisa:
1. Subir seu projeto em um repositório do GitHub
2. Criar uma conta no Streamlit, que pode ser criada usando o próprio GitHub.
Pronto. Ao fazer login, no canto superior direito da tela inicial vai aparecer Create app.
Ao clicar aparecerá as seguintes opções. Escolha a primeira.
Na página seguinte, escolha Paste GitHub URL.
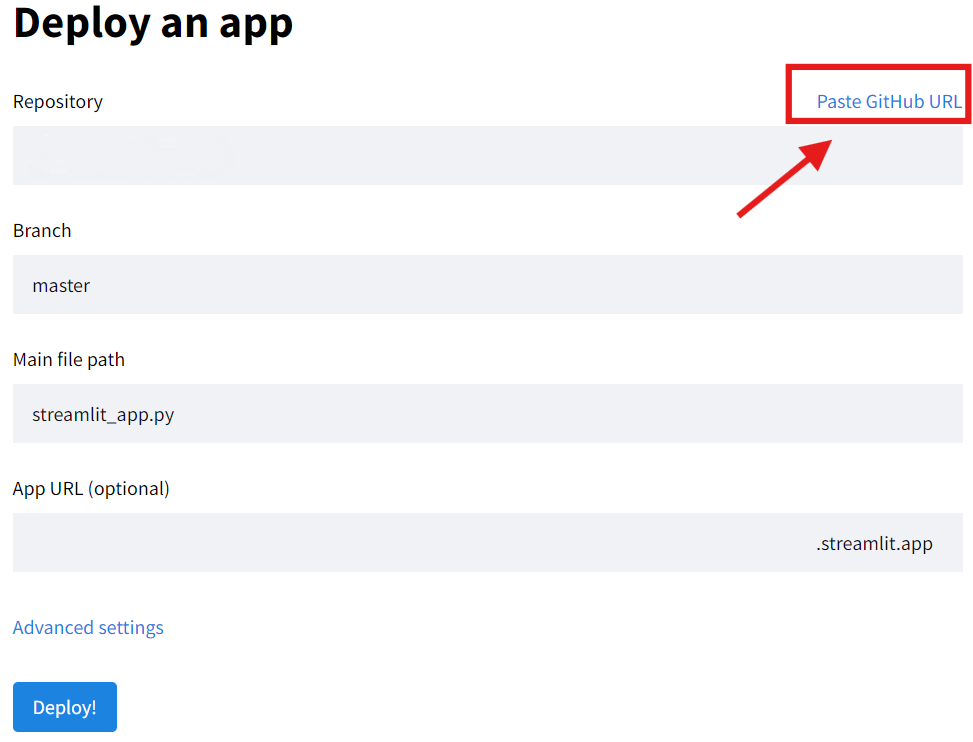
Caminhe até o arquivo que você executava localmente (1_inicio.py), clique no arquivo.
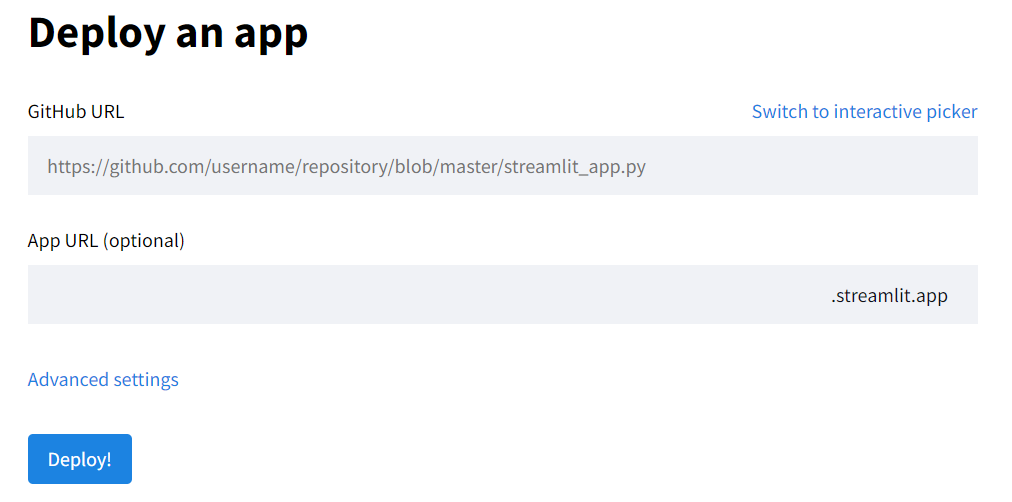
Quando abrir, copie o link do navegador e cole na página que você abriu do site do Streamlit, no campo GitHub URL.
No campo de baixo (App URL) crie um nome para seu app.
Configurado estas duas coisas, clique em Deploy! e pronto.
Para ir além…
São muitas as possibilidades de personalização do Streamlit. Como você pode ver, com apenas poucos recursos conseguimos criar um app legal e funcional. Encorajo você a explorar a documentação da biblioteca, é super fácil e possui vários exemplos.
Também existem outros exemplos de aplicações que podem ser criadas utilizando a ferramenta. Dê uma olhada na galeria para se inspirar.
Esperamos que tenha gostado. Em caso de dúvidas, peça ajuda da comunidade no fórum Jornalismo de Dados.








