
O tabula-java é a ferramenta de linha de comando do Tabula para extrair as tabelas dos PDFs. Enquanto o Tabula tradicional oferece uma interface gráfica (confira nosso tutorial sobre o assunto), com o tabula-java você tem as mesmas funcionalidades, mas na linha de comando.
A vantagem é que o tabula-java funciona mais rapidamente e facilita processos de automatização. Ou seja, você pode customizar as extrações e fazer a raspagem em diversos arquivos ao mesmo tempo.
Vamos ver o passo a passo:
1) Para usar o tabula-java, faça o download o arquivo com extensão “JAR” na página do Github do projeto. Depois de fazer o download, vamos renomear o arquivo para “tabula-java.jar”, apenas para simplificar os comandos futuros.
Você pode usar o tabula-java de muitas maneiras. Dá pra dizer pra ele qual é a parte da página que você quer analisar. Dá também pra processar todos os PDFs num determinado diretório. Dá pra pedir pra ele tentar adivinhar qual parte da página ele deve extrair. E também escolher de que forma você quer salvar as informações.
Todos esses comandos devem ser usados junto com o tabula-java na hora da sua execução.
2) Coloque um arquivo PDF com dados em formato de texto (não como imagem) na mesma pasta onde o arquivo tabula-java se encontra. Um exemplo de arquivo PDF assim é esta tabela disponibilizada pelo Governo Federal com um calendário de pagamentos para 2019. Vamos baixar este arquivo na mesma pasta do tabula-java e renomeá-lo para “pagamentos.pdf”.
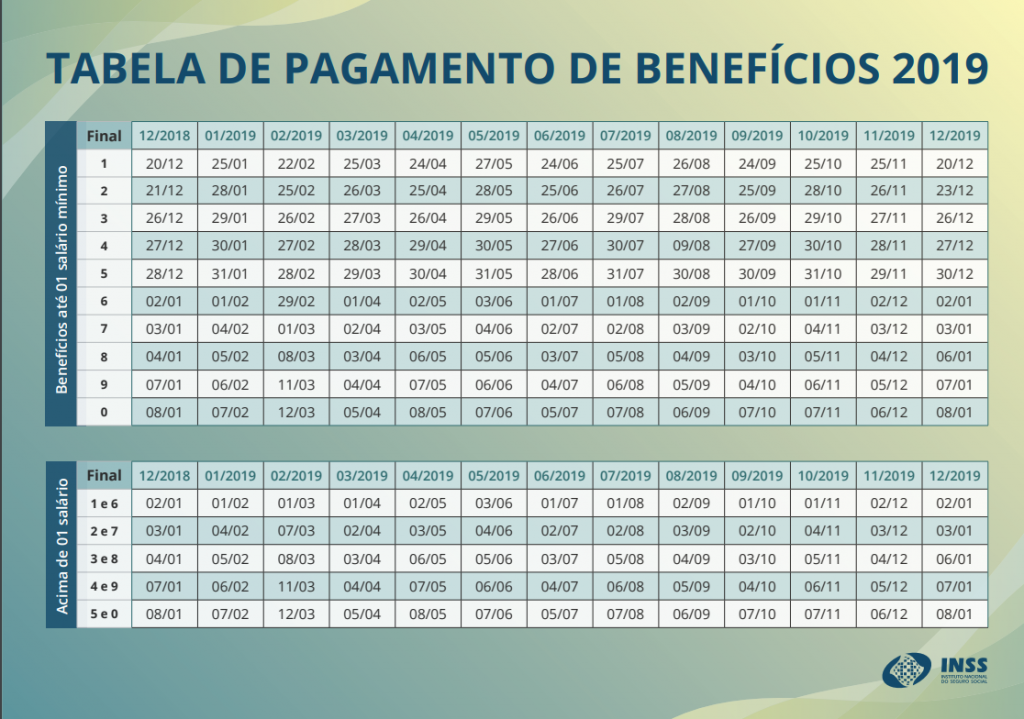
Nossa tabela está assim, no formato PDF
3) Para executar o tabula-java, você precisa abrir a linha de comando no diretório onde ele se encontra e digitar um comando.
Este comando começa com “java”, que é pré-requisito para o Tabula-java funcionar. Depois escreveremos “-jar”. O sinal de – indica uma opção que você vai rodar junto com o programa. Nesse caso, estamos sinalizando pro Java que precisamos abrir um arquivo do tipo .jar.
Em seguida, eu digito o tabula-java.jar – ou seja, me referencio ao arquivo que renomeamos no passo anterior. E, agora, vamos às opções que iremos passar para o Tabula-Java em si.
Na página do Github você pode ver todas as opções possíveis, mas aqui vamos usar três.
Vamos começar com o “-g” de “guess”. Assim, o Tabula-Java vai tentar “adivinhar” a porção da página onde está a tabela a ser extraída.
Depois, vamos usar o “-p all”, para indicar que queremos todas as páginas.
Vamos usar o -o, de output – ou saída – para indicar o nome do arquivo de saída, a ser exportado: tabela.csv.
Essa opção completa fica “-o tabela.csv”.
E por último colocamos o nome do arquivo “pagamentos.pdf”.
Ou seja, nosso comando completo fica assim:
java -jar tabula-java.jar -g -p all -o tabela.csv pagamentos.pdf
Aperte enter e você verá o arquivo convertido salvo na sua pasta, pronto para passar por técnicas de limpeza, se for o caso, e ser analisado.
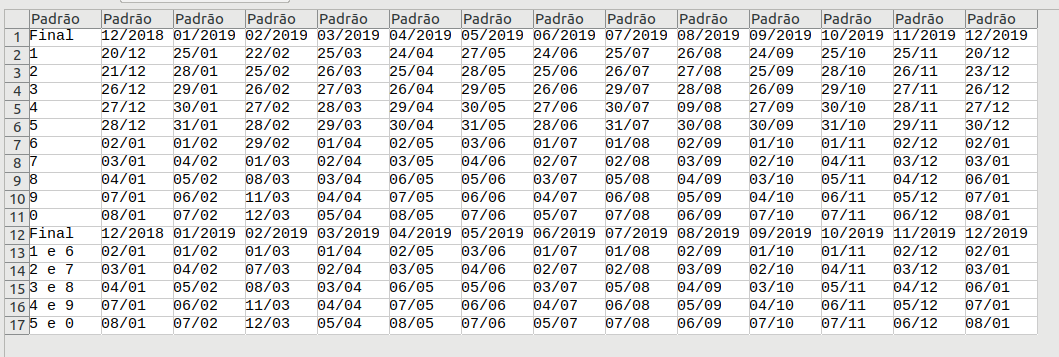
Depois de convertido, eis a mesma tabela, em formato CSV, sendo importada em um editor de planilhas
E você?
Você pode compartilhar sua experiência com o Tabula ou outras ferramentas no nosso fórum da Escola de Dados.









Já tentei várias vezes executar mas não consegui. É uma pena que a versão anterior do Tabula não esteja mais funcionando (http://127.0.0.1:8080). Era bem mais fácil trabalhar por lá. Nas minhas tentativas de executar o código aprece unable to acess jarfile tabula-java.jar
Oi, Lázaro! Você pode tentar uma solução para isso no https://forum.jornalismodedados.org. As pessoas da nossa rede que também trabalham com Tabula podem ter passado pelo mesmo problema, e de repente sabem como solucioná-lo 🙂