
Trecho do artigo “Effective Visualization of Multi-Dimensional Data — A Hands-on Approach” de Dipanjan Sarkar, publicado originalmente no canal The Startup.
Tradução de Cássia Sampaio.
| O texto original foi separado em três seções: I – Introdução à gramática dos gráficos; II – Análise multivariada e visualização de dados multidimensionais (publicada neste notebook); III – Visualizando dados não estruturados e conclusão; |
A seção anterior [parte I e parte II] apresentou algumas técnicas úteis para a visualização eficaz de dados estruturados. Mas como lidamos com dados não estruturados como texto, imagem e áudio? Cada um deles é bem diferente entre si e também variam significantemente considerando cada um deles de modo separado! Aqui, examinaremos brevemente algumas formas de visualizar essas três fontes de dados não estruturados. Lembre-se de que o objetivo final de visualizar essas fontes de dados não é apenas pela visualização em si, mas para obter insights e gerar atributos úteis que possam ser usados nos processos de aplicações de machine learning (aprendizagem de máquina) ou de deep learning (aprendizagem profunda de máquina).
Visualizando texto
Considerando que você tem um corpus de texto, uma das melhores maneiras de começar é fazer uma análise exploratória dos dados (EDA ou Exploratory Data Analysis) básica. Isso pode ser algo como tentar encontrar a distribuição de comprimentos de sentenças típicos ou números de palavras. Mostramos um exemplo abaixo de um dos meus workshops recentes sobre NLP (Natural Language Processing ou processamento de linguagem natural).

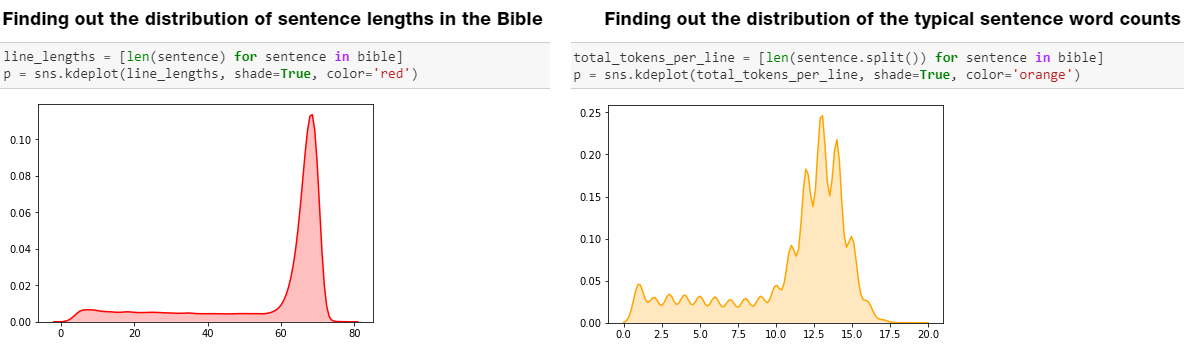
EDA básica em texto
Além disso, também podemos nos concentrar em entender e visualizar a estrutura da linguagem, aproveitando técnicas como shallow parsing (análise sintática superficial), dependency parsing (análise sintática de dependência), e constituency parsing (análise sintática de constituintes). Exemplos de códigos detalhados estão presentes em um dos meus artigos de “Natural Language Processing” (Processamento de Linguagem Natural, em inglês), caso você se interesse por mais detalhes.
A Practitioner’s Guide to Natural Language Processing (Part I) – Processing & Understanding Text
A imagem abaixo mostra um exemplo do meu artigo demonstrando a análise sintática de constituintes e dependência.
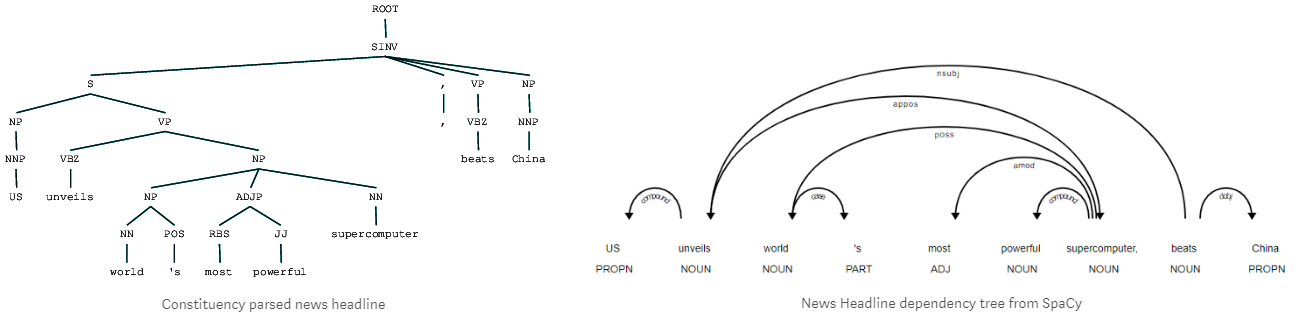
Análise sintática de constituintes e dependência – entendendo a estrutura do texto
Também podemos observar os embeddings (vetores de palavras) baseados em modelos recentes de aprendizado profundo, como Word2Vec, GloVe e FastText, para entender a semântica de texto além da estrutura. Eu também escrevi sobre isso em detalhes no meu artigo sobre “Feature Engineering Methods for Text Data” (Métodos de Engenharia de Atributos para Texto, em inglês) que você pode referenciar se tiver interesse nos detalhes sangrentos!
Normalmente, a visualização de embeddings de palavras pode ajudar você a entender o contexto e a semântica entre as palavras do seu corpus e até aproveitar esses recursos para criar modelos de machine learning ou deep learning!

Um exemplo de visualização de embeddings de palavras da Bíblia com word2vec
Visualizando dados de imagens
As imagens são basicamente tensores multidimensionais que podem ser representados como matrizes de valores de pixels. Isso realmente aumenta a dimensionalidade de uma simples imagem pequena e dificulta o trabalho com elas. Um exemplo simples é mostrado na figura a seguir.

Uma das melhores formas de começar é carregar qualquer imagem de interesse específico e ver as suas contribuições de canal com base nos seus valores de pixel da seguinte forma.
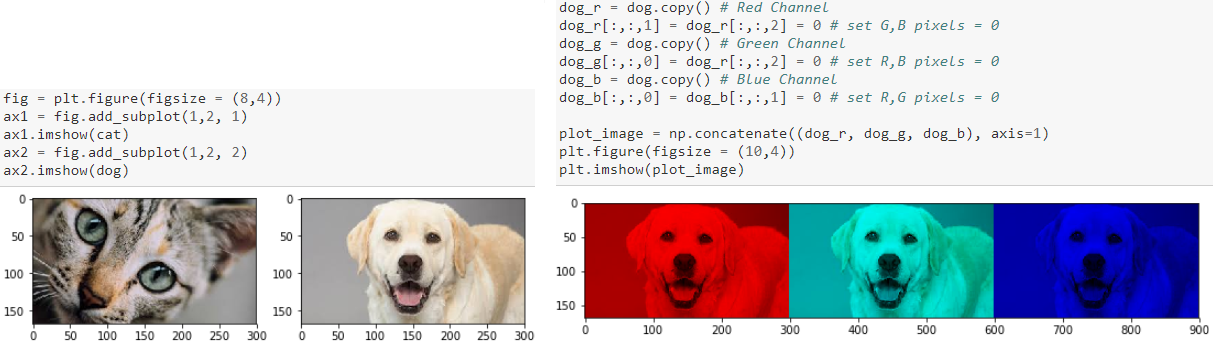
Visualizando canais de imagens
Outro aspecto interessante para dar uma olhada seria observar a distribuição da intensidade da imagem verificando os valores dos pixels e plotando uma distribuição, como mostramos na figura a seguir.
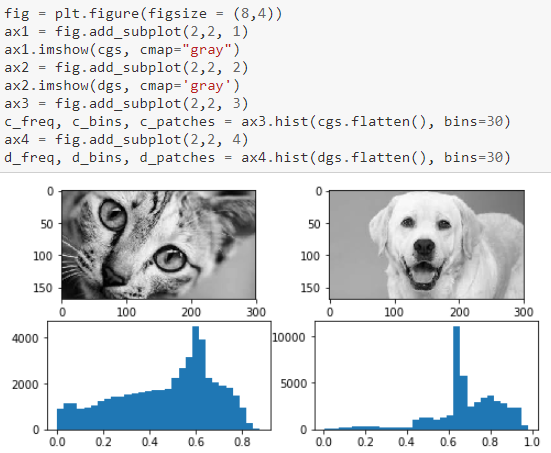
Visualizando distribuições de intensidade de imagem
Considerando visualizações que podem ser úteis para machine learning ou deep learning, podemos observar a detecção de bordas que pode ajudar a identificar as bordas da imagem e até mesmo usar isso como potenciais atributos!

Visualizando bordas da imagem
Também podemos visualizar atributos obtidos do HOG, que significa histograma de gradientes orientados (Histogram of Oriented Gradients). Em termos simples, isso ajuda na contagem de ocorrências de orientação do gradiente em partes localizadas. Um exemplo simples é mostrado abaixo.
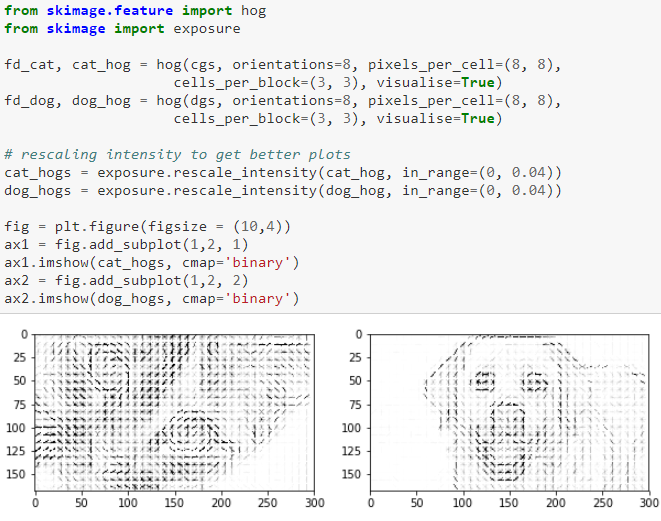
Visualizando atributos HOG
Você pode até usar os atributos descritivos obtidos a partir da técnica anterior para criar classificadores de imagens, detecção de objetos e assim por diante.
CNNs mudaram o mundo
Convolutional Neural Networks (Redes neurais de convolução), popularmente conhecidas como CNNs, realmente revolucionaram a maneira de visualizar e modelar dados visuais usando a engenharia de atributos e a representação de atributos automatizadas. Cada camada, normalmente conhecida como uma camada de convolução (geralmente seguida por uma camada de pooling), pode extrair atributos específicos e genéricos das imagens de entrada. Um exemplo é mostrado na imagem a seguir, onde a CNN visualiza e aprende representações de atributos para cada face em cada camada da rede.
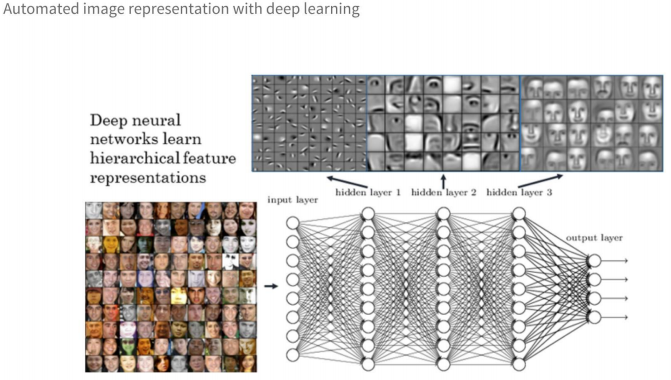
CNNs revolucionaram a representação de imagens e engenharia de atributos
Visualizar camadas intermediárias das CNNs sempre ajuda a entender quais partes das imagens estão sendo extraídas como atributos e ajuda a ativar as unidades ocultas (hidden units) nessas camadas!
Visualizando áudio
A maior questão aqui seria: “você pode realmente ver algo que você pode ouvir?”. A intenção aqui é poder visualizar qualquer som ou áudio criado a partir de uma fonte específica. O processamento de sinal realmente ajuda nesses aspectos! Eu trabalhei recentemente em um interessante método de classificar diferentes categorias de arquivos de áudio do UrbanSound8K usando deep transfer learning (transferência de aprendizado profundo), onde usamos modelos pré-treinados que eram especialistas em classificar imagens, o que surpreendentemente funcionou, com 90% de acurácia! Você pode conferir mais detalhes em meu livro, “Hands-on Transfer Learning with Python” (Aprendizado de transferência prática com o Python, em inglês), se tiver interesse, e eu abri o código para todas as pessoas no GitHub.
Utilizamos o framework librosa para extração de atributos e ele também fornece excelentes APIs de visualização. Uma das maneiras mais fáceis de visualizar o som é fazendo um gráfico das amplitudes de onda, conforme ilustrado na figura a seguir.
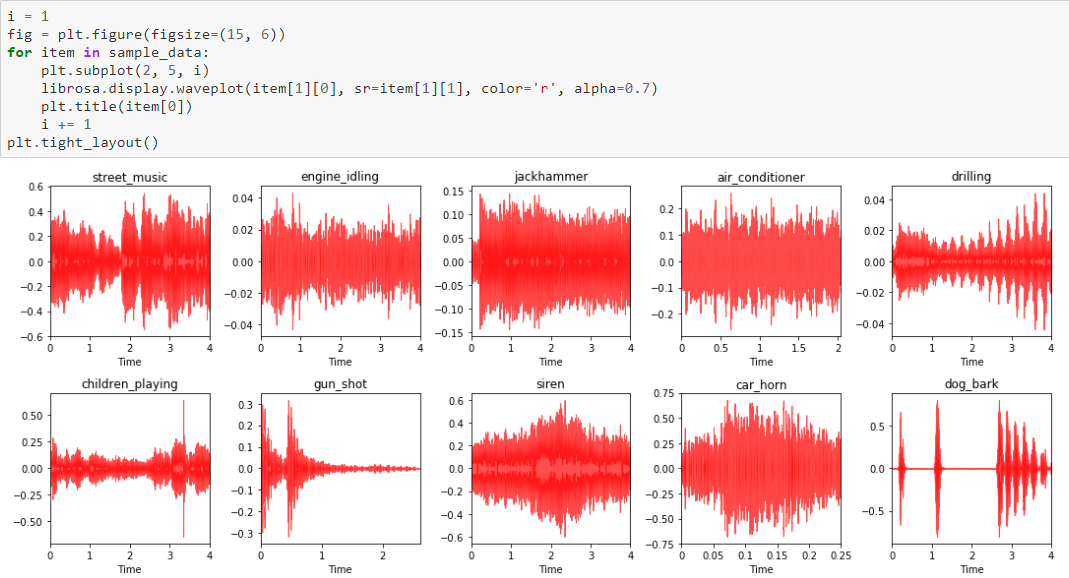
Visualizando Amplitudes de Onda do Áudio
No entanto, visualizações mais úteis são os mel-spectograms (espectrogramas-mel), que são literalmente uma representação visual do espectro de freqüências de nossos sinais de áudio enquanto variam com o tempo. A próxima imagem mostra os mel-spectograms dos nossos áudios.

Visualizando Mel-spectograms do áudio
Essas visualizações nos dão uma ideia de como diferentes fontes de áudio podem ser e são atributos muito úteis que podem ser usados por modelos de deep learning como CNNs.
Conclusão
A visualização de dados é uma arte e também uma ciência. Se você ainda está lendo, eu realmente elogio seus esforços por continuar a ler este artigo extenso. A intenção não é memorizar algo nem fornecer um conjunto fixo de regras para visualizar dados. O principal objetivo aqui é entender e aprender algumas estratégias eficazes para visualizar dados estruturados e não estruturados, especialmente quando o número de dimensões começa a aumentar. Mantenha as coisas simples e não exagere na tentativa de criar visualizações extremamente complexas.
Eu encorajo você a usar esses pedaços de código para visualizar seus próprios datasets no futuro. Sinta-se à vontade para me dar feedback e compartilhar suas próprias estratégias de visualização de dados efetiva “especialmente se você puder ir mais além!”
A maior parte desses artigos foi abordada em uma das minhas recentes palestras na conferência em ODSC, 2018. Você pode conferir a agenda completa de palestras e os slides aqui. A palestra da conferência do YouTube está disponível aqui.
Tem feedback para mim? Ou interessado em trabalhar comigo em pesquisa, ciência de dados, inteligência artificial? Você pode entrar em contato comigo no LinkedIn.
Dipanjan Srkar – Data Scientist – Intel Corporation | LinkedIn








