
Processamento de linguagem natural (em inglês, conhecido como “natural language processing” ou NLP) é um campo da computação e da inteligência artificial que estuda como máquinas podem entender, analisar, manipular e até mesmo gerar linguagem humana. Você pode não conhecê-lo, mas ele provavelmente está presente no seu cotidiano.
As técnicas de NLP estão lá, seja quando você faz uma busca no Google, na identificação de erros gramaticais em editores de texto, nos filtros de emails para identificar spams, na interação com assistentes virtuais, atendimento via chatbots, entre outras possíveis ocasiões. No jornalismo, não é diferente e a NLP também já é uma realidade há anos.
Exemplos não faltam.
Ainda em 2011, a Forbes já trabalhava com a criação automatizada de informes financeiros. Do mesmo modo, desde 2014, a Associated Press (AP) utiliza técnicas de inteligência artificial para gerar conteúdos sobre economia. Atualmente, a AP usa algoritmos do tipo também para monitorar as conversações em redes sociais, a fim de identificar rapidamente eventos importantes de serem noticiados.
De acordo com Lisa Gibbs, editora da agência, em 2019, a previsão era ter 40 mil matérias geradas automaticamente. O número pode impressionar, mas ainda é pouco, especialmente se considerarmos que à época a AP publicava mais de mil reportagens por dia.
A Reuters por sua vez tem o Calais, que utiliza as técnicas de NLP para estruturar dados e marcações (tags), a partir de textos corridos, não estruturados. Já o Yahoo as aplica na produção de matérias esportivas e resumos automatizados, enquanto o Washington Post utiliza a tecnologia no Modbot, que facilita o trabalho dos moderadores dos comentários no portal do jornal.
No Brasil, também existem exemplos. Em 2020, o G1 publicou reportagens automatizadas com o resultado das eleições em todos municípios do país usando uma tecnologia do tipo. Já o Confere.ai – iniciativa do Jornal do Commercio em parceria com uma startup e uma universidade pernambucana – aplica NLP para verificar potencial de desinformação de conteúdos na Internet.
Como se vê, os usos de NLP no jornalismo são variados. Estas técnicas podem servir para produzir textos ou materiais inéditos de forma automatizada, interagir com os leitores por meio de chats, facilitar tarefas relacionadas à checagem de dados, monitorar conversações em redes sociais, ajudar na classificação automática de documentos ou identificação de tópicos importantes em textos, entre outras possibilidades.
Mas o que podemos esperar destas tecnologias daqui pra frente? Como os jornalistas podem dar os primeiros passos na área? E, por outro lado, como cientistas da computação podem colocar o processamento de linguagem natural a serviço do bom jornalismo?
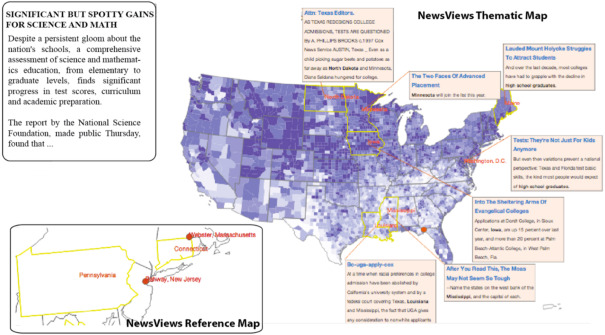
Mapa com visualização de dados e anotações, gerado automaticamente pela aplicação NewsView, criada por pesquisadores acadêmicos em meados da década passada. (Fonte: ‘A survey on automatic infographics and visualization recommendations’).
Os jornalistas e os robôs
Vejamos o primeiro caso, o uso de NLP para produção de textos automatizados.
Atualmente, isso ocorre principalmente em situações nas quais já existe um volume considerável de dados estruturados e a reportagem limita-se a informar números ou resultados em um contexto bem específico. É o caso do mercado financeiro, do universo esportivo ou das eleições brasileiras. Em todos eles, as redações possuem acesso a bancos de dados bem estruturados sobre os temas e os textos sobre o assunto são razoavelmente padronizados.
Mas este é apenas o começo. Em 2020, um novo capítulo se abriu na história da aproximação entre o campo de NLP e da imprensa, com a publicação pelo The Guardian de um artigo de opinião redigido por máquinas. A coluna foi escrita por um robô movido pelo algoritmo GPT-3 da OpenAI, considerado um dos modelos mais avançados da área.
Além de escrever matérias e palpitar em jornais, os robôs também já são empregados na produção de visualizações de dados em grandes grupos de comunicação. Veículos como Associated Press, Der Spiegel e Reuters já empregam algoritmos para criação automatizada de gráficos e mapas, inclusive com textos de legendas explicativas, como aponta Nicholas Diakopoulos, professor da Northwestern University e convidado da V Conferência de Jornalismo de Dados e Métodos Digitais (Coda.Br 2020), em seu livro ‘Automating the News’, que trata da incorporação das práticas de automação computacionais na imprensa.
“Seja para aumentar a escala, velocidade, eficiência e amplitude ou para criar novas possibilidades por meio da adaptação, otimização e personalização de conteúdo, existem coisas interessantes e aparentemente mágicas que os algoritmos tornam possíveis. Mas atrás da cortina estão designers, editores, repórteres, cientistas de dados e engenheiros, todos contribuindo de forma direta ou indireta” (Nicholas Diakopoulos).
Pode parecer assustador. Mas não se trata de trocar o trabalho jornalístico humano pelo das máquinas. Ao contrário, quando bem executada, a automação dos processos pode absorver tarefas repetitivas e liberar tempo para as pessoas realizarem trabalhos que só humanos seriam capazes de fazer.
Algoritmos e automação não substituirão o trabalho de jornalistas: irão complementá-lo. Ou seja, os robôs não irão roubar seus empregos, mas podem redefinir suas práticas profissionais.
NLP, por onde começar?
Ainda que desenvolvedores, cientistas da computação ou de dados possam ser escalados para trabalhar em projetos robustos envolvendo NLP nas redações, os próprios jornalistas podem começar a ver textos como dados e trabalhar com técnicas de processamento de linguagem natural por conta própria, seja construindo seus próprios scripts ou programas, seja por meio de aplicações já prontas que empregam esta tecnologia.
É possível usar NLP, por exemplo, durante o processo de apuração de reportagens. Softwares do tipo facilitam a leitura automatizada de textos, reconhecendo e marcando no texto de forma automática entidades, como pessoas, empresas ou datas. Isso é muito útil para explorar grandes volumes de documentos e atualmente sequer requer conhecimentos de programação. Vejamos abaixo algumas dicas de softwares, para quem quer dar os primeiros passos.
- DocumentCloud: plataforma de código aberto que serve como um catálogo de fontes primárias para jornalistas, permitindo anotações colaborativas. A plataforma roda em um servidor web e faz uso do OpenCalais da Reuters para identificação automatizada de entidades. O DocumentCloud também já processa textos em imagens (como documentos digitalizados) usando técnicas de reconhecimento óptico de caracteres (OCR).
- Overview: outra ferramenta de código aberto, mas voltada especificamente para jornalistas investigativos. Oferece diversas possibilidades de visualização da informação a partir de textos de coleções de documentos. Também oferece OCR e modelagem de tópicos dos documentos nativamente.
- Google Pinpoint: o software é gratuito e além das vantagens dos anteriores, destaca-se por conseguir também fazer transcrições de áudio e incorporar este tipo de arquivo nas coleções de documentos analisáveis. Para utilizá-lo, basta ter uma conta Google.
- Voyant Tools: ferramenta de código aberto que também roda direto do navegador. Permite explorar resumos quantitativos de textos direto do navegador, com facilidade. Destaca-se por não exigir nem cadastro, nem nenhum tipo de instalação. Basta acessar o site e aproveitar funcionalidades como análise de relações entre palavras, termos mais frequentes, nuvens de palavras, etc.
- Natural Language Toolkit (NLTK): é a principal biblioteca de softwares para trabalhar com processamento de linguagem natural em Python. Seu estudo é indicado para quem quiser se aprofundar no tema e desenvolver suas próprias aplicações.
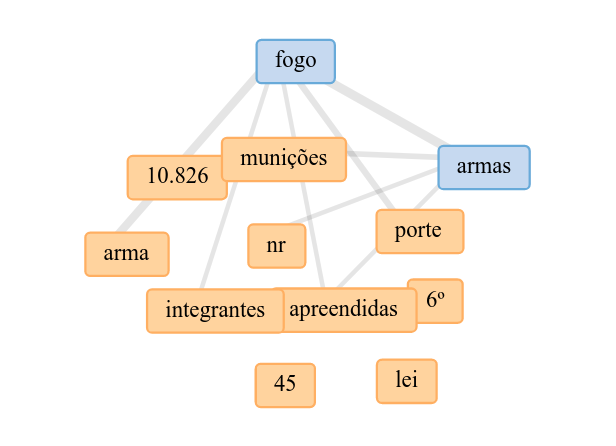
Além das famigeradas nuvens de palavras, o Voyant Tools também permite criar outros tipos de visualizações com poucos cliques. Na imagem acima, uma rede de palavras gerada na plataforma, com o texto do decreto n.10.630 de 12 de fevereiro de 2021, um dos mais recentes “decretos das armas” do presidente em exercício Jair Bolsonaro.
O Coda.Br 2019 contou com um workshop sobre processamento de linguagem natural, que tem materiais com acesso aberto. Nele, Victor Longo apresentou conceitos de NLP e ferramentas em Python para jornalistas presentes no evento. Proveniente de um treinamento dado no LinkedIn Learning, o material utilizado está disponível no repositório GitHub do palestrante. Quem quiser ir mais a fundo, pode conferir também o curso introdutório gratuito da Fast.AI sobre NLP com muitos códigos prontos e exemplos práticos. A playlist com os vídeos está no YouTube e os códigos utilizados ficam no GitHub.

Workshop de Victor Longo sobre processamento de linguagem natural, no Coda.Br 2019.
PARA SAIR DO ZEROPara esquentar, veja abaixo quatro conceitos importantes da área de processamento de linguagem natural, que foram abordados no workshop sobre o tema no Coda.Br 2019*. N-gramas São sequências contínuas de algum item, como palavras ou letras. Em geral, trabalha-se com uni-gramas de palavras. Ou seja, durante o processamento de um texto, cada palavra é separada e considerada um token. Já se escolhermos bigramas de palavras, elas serão agrupadas em pares, por exemplo, na frase “um pássaro que voa”, teríamos 3 bi-gramas: “um pássaro”; “pássaro que” e “que voa”. Stopwords Palavras “vazias” ou “palavras de parada” seriam algumas das traduções possíveis, mas em geral utilizamos mesmo é a versão anglófona: as “stop words” são palavras consideradas irrelevantes para a análise de um texto e portanto são removidas durante o processamento do mesmo. Em geral, tratam-se de palavras muito frequentes (como preposições ou conjunções) que são ignoradas. Já existem diversas listas prontas com “stop words”, mas o ajuste fino de quais palavras devem ser incluídas ou não sempre depende da finalidade de cada projeto e alguns modelos de NLP mais recentes não mais ignoram as stop words. Ao invés disso, passam a interpretá-las como um importante elemento de conexão no texto. É o caso do BERT do Google, que utiliza técnicas de aprendizado profundo (deep learning) para ajudar a interpretar as consultas feitas no buscador da empresa. Se você já tem algum conhecimento na área, pode experimentar o DistilBERT, que permite rodar um modelo semelhante sem o poder computacional do Google. Stemização Toda palavra tem uma raiz. Então, dentro das bibliotecas de processamento de linguagem natural existe uma função específica para extrair a raiz (‘stem’) delas. Esta função pode classificar e agrupar (ou reduzir) todas as palavras de acordo com suas raízes. Exemplo: “editor” e “editora” podem ser reduzidas à raiz comum “editor”, assim como “garoto” e “garota” compartilham a raiz “garot”. Lematização A lematização por sua vez transforma as palavras na sua forma de dicionário. Para verbos, por exemplo, esta forma é com a conjugação no infinitivo: “escreveu”, “escrevia” e “escreverá” possuem como lema “escrever”. Assim como na stemização, o objetivo é descartar as diferentes inflexões ou derivações que a mesma palavra pode ter. |
Como CIENTISTAS DA COMPUTAÇÃO podem ajudar jornalistas?
Por outro lado, cientistas da computação também podem ajudar os jornalistas a tirarem melhor proveito das tecnologias de NLP. Professor da Columbia University e convidado do Coda.Br 2017, Jonathan Stray é um dos pesquisadores que tenta entender os desafios de aplicar as tecnologias de inteligência artificial no jornalismo. No texto ‘What do Journalists do with Documents? Field Notes for Natural Language Processing Researchers’, Stray revisou 15 reportagens produzidas com o Overview e listou 6 temas considerados prioritários, para cientistas da computação interessadas em ajudar jornalistas com o poder das técnicas de NLP.
- Importações robustas: muitas vezes, jornalistas precisam lidar com textos em formatos pouco adequados à máquina, como por exemplo documentos em papel que foram digitalizados;
- Análises robustas: os programas precisam conseguir lidar com “textos sujos”. Stray sugere a criação de dicionários de jargões e abreviações, por exemplo;
- Busca, não exploração: repórteres em geral estão buscando por algo, mas nem sempre isto é facilmente explicável em uma busca por palavras-chaves. O exemplo paradigmático mencionado por Stray é “corrupção”.
- Resumos quantitativos: como as técnicas de NLP podem transformar a produção de reportagens baseadas em resumos quantitativos mais fácil, flexível ou acurada?
- Métodos interativos: como melhorar a interação com a máquina na supervisão humana dos processos envolvendo NLP?
- Transparência e acurácia: jornalistas precisam prestar contas ao público sobre as informações. É preciso explicar como se chegou a uma resposta e como sabemos que ela é verdadeira. Nem sempre os resultados de algoritmos de NLP, como análises de sentimentos ou modelagem de tópicos, são de fácil compreensão para profissionais não especializados.
E você?
Conhece algum exemplo de NLP no jornalismo? Tem alguma dica ou dúvida envolvendo o tema? Compartilhe conosco na caixa de comentários abaixo.
* A cobertura colaborativa do workshop ‘Processamento de Linguagem Natural: oportunidades para jornalistas’ no Coda.Br 2019 foi realizada por Mikael Peric e Luis Nascimento. As anotações serviram de insumo para trechos deste artigo.
Autoria

Adriano Belisario


