
Tutorial elaborado por Fernando Barbalho em setembro de 2023.
Então você é aquele tipo de cientista de dados e escritor amador no Medium que sempre gostou de mapas e Geografia desde a infância. Você está procurando um bom tema para o seu próximo trabalho com gráficos e, muito provavelmente, mapas, quando percebe que o IBGE divulgou os dados mais recentes do censo. Por que não? Que tal uma visão do Brasil em comparação com seus vizinhos na América do Sul? Parece uma tarefa simples usando R e todos os seus ótimos pacotes. Vamos fazer isso.
Minutos após essa decisão, surge a percepção de que a tarefa simples é, na verdade, uma jornada de herói com elementos como a descoberta do conjunto de dados mais adequado com shapefiles, falta de informação, interoperabilidade de shapefiles, matemática de latitude e longitude, diferenças culturais em conceitos geográficos e até questões geopolíticas, como entender como colocar o mapa e dados dos territórios ultramarinos da França corretamente na América do Sul.
Os próximos parágrafos explicam um dos caminhos possíveis para pintar informações demográficas em uma parte delimitada de um mapa-múndi. O passo a passo descrito abaixo pode ser útil para todos os interessados em comparações internacionais com uma abordagem de visualização geográfica, mesmo que o objetivo seja comparar o acesso à água entre os países africanos ou as taxas de obesidade na América do Norte.
Pachamama
Vamos começar com o panorama geral: uma versão em R do mapa-mundi. Veja a imagem e o código abaixo.
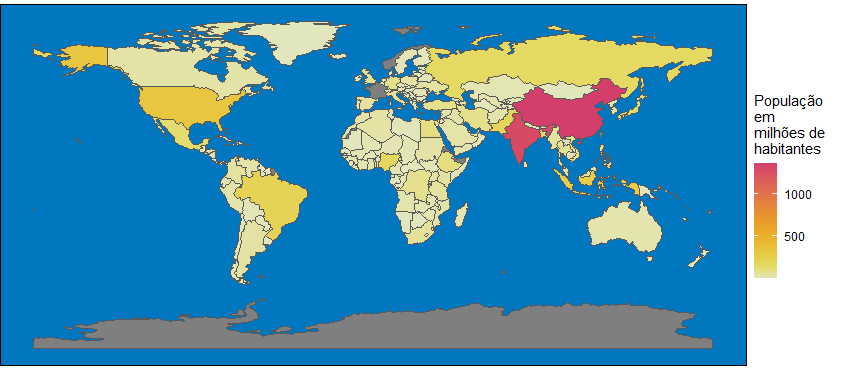

Eu uso o pacote {spData} como referência para um dataframe com informações de geometria para shapefiles de territórios ao redor do planeta. A função aes usa informações da população para preencher as formas.
Como sabemos, China e Índia são os países mais populosos do mundo, com mais de 1 bilhão de pessoas cada. As cores quentes mostram o contraste com todos os outros países. A maioria das cores sequenciais é fraca. Mal podemos entender o gradiente de cores na imagem. O logaritmo é a melhor alternativa se você quer uma visão melhor da distribuição de cores. Veja abaixo a alternativa.
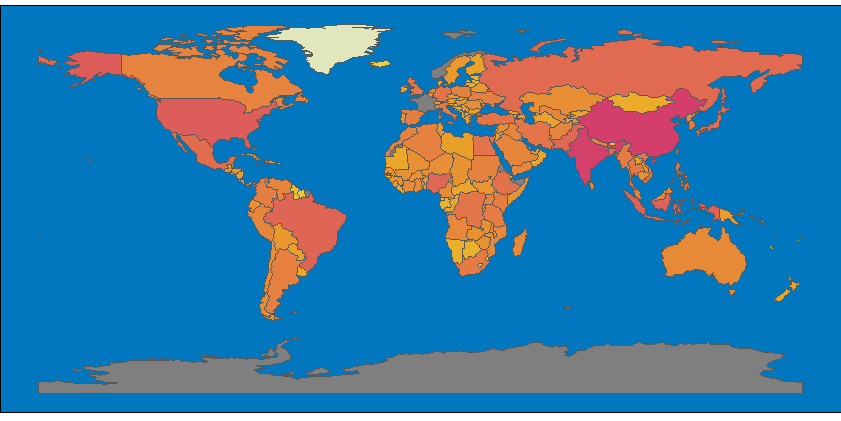
No código, você pode ver a transformação logarítmica na função scale_fill_continuous_sequential.

Na estrutura do dataframe world, há uma coluna Continent (Continente). Portanto, filtrar os dados usando essa coluna para obter um mapa da América do Sul é óbvio. Veja o código e, logo em seguida, o mapa.

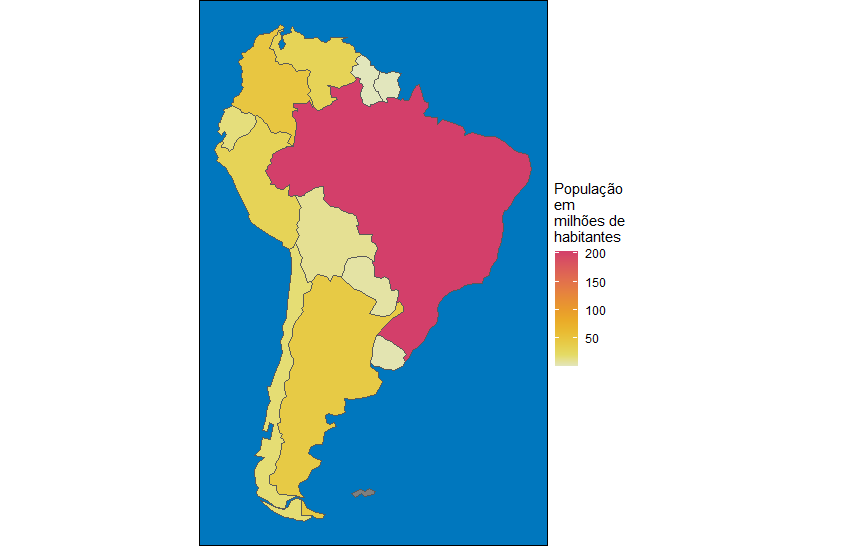
Como você pode ver, a função de filtro do dplyr funcionou bem; esse é exatamente o mapa que queríamos ver. Mas será que ele está realmente correto?
A mudança climática é um problema enorme, mas os níveis do mar ainda não subiram tanto a ponto de afogar uma área relativamente grande que costumava aparecer no norte da América do Sul. O que aconteceu aqui? Vamos desenhar outro mapa agora com a ajuda de coordenadas e nomeando os polígonos.
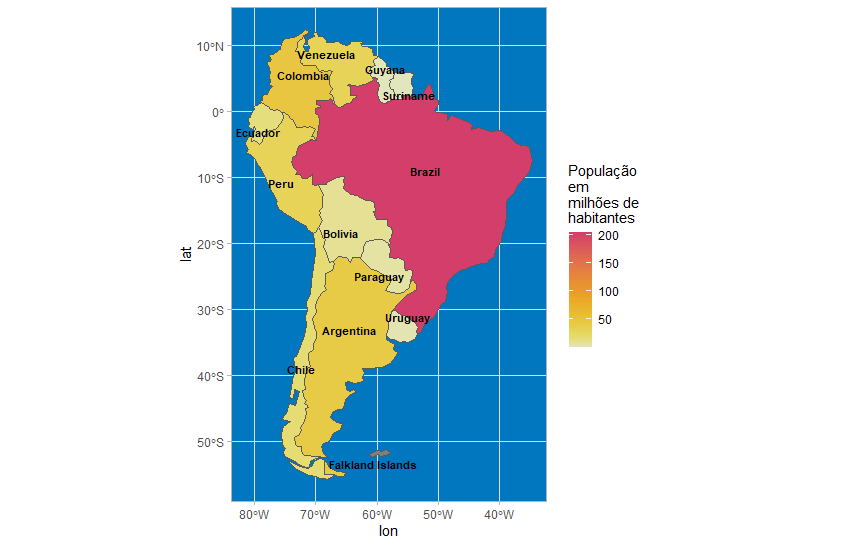

O theme_light em vez do theme_void foi suficiente para exibir as coordenadas. A nomeação do polígono exigiu mais trabalho. Tivemos de calcular o centroide de cada polígono e, em seguida, usar essas informações como coordenadas x e y em uma função geom_text_repel.
Com essa nova versão do mapa e algum conhecimento prévio, descobrimos que o território que faltava era a Guiana Francesa, entre 0º e 10º de latitude norte e 53º e 55º de longitude oeste. Nossa próxima missão é entender como obter as informações da Guiana Francesa: polígono, população e algumas coordenadas para preencher nosso mapa.
La Mer
Tive de isolar a França do resto do mundo para entender como o pacote {spData} lidava com os dados do mapa desse país. Veja o resultado abaixo.
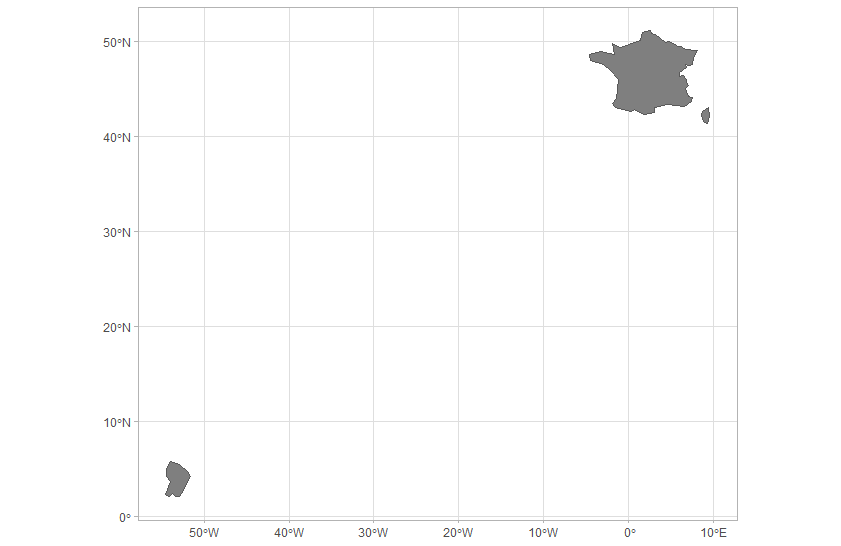

A França tem muitos dos chamados territórios ultra-marinhos. A abordagem do pacote {spData} foi representar apenas o território principal, mais a Córsega, uma ilha no Mar Mediterrâneo, e a Guiana Francesa, localizada precisamente no intervalo de coordenadas que caracteriza a lacuna em nosso último mapa da América do Sul.
Minha próxima tentativa foi adicionar uma condição ao meu filtro, mas eu sabia que precisaria de mais. Veja abaixo:
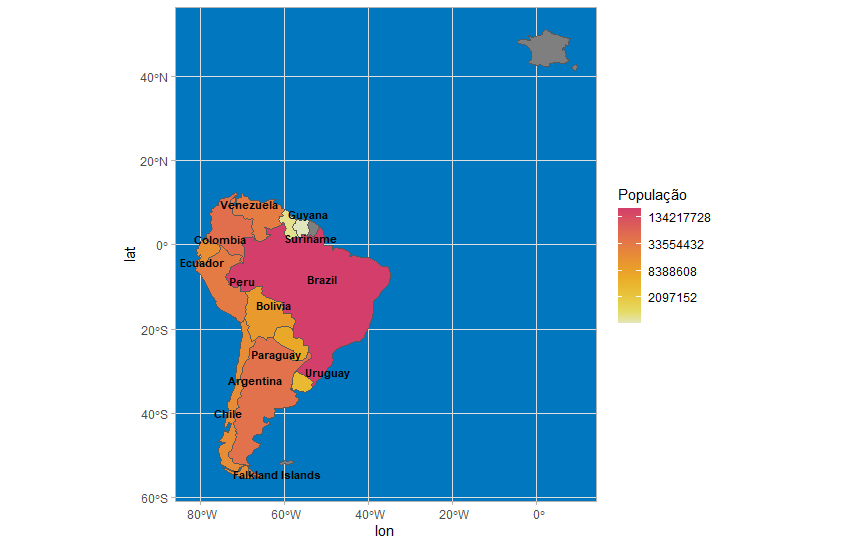

Como você pode ver no código, a condição adicionada foi um operador OR que combinava os territórios da América do Sul com o país cujo código ISO é FR. Portanto, tínhamos agora a Guiana Francesa bem posicionada. Por outro lado, não há informações sobre a população no mapa, e a França faz parte da América do Sul no reverso da história do colonialismo.
Em outras palavras, o que eu na verdade, é esse mapa.
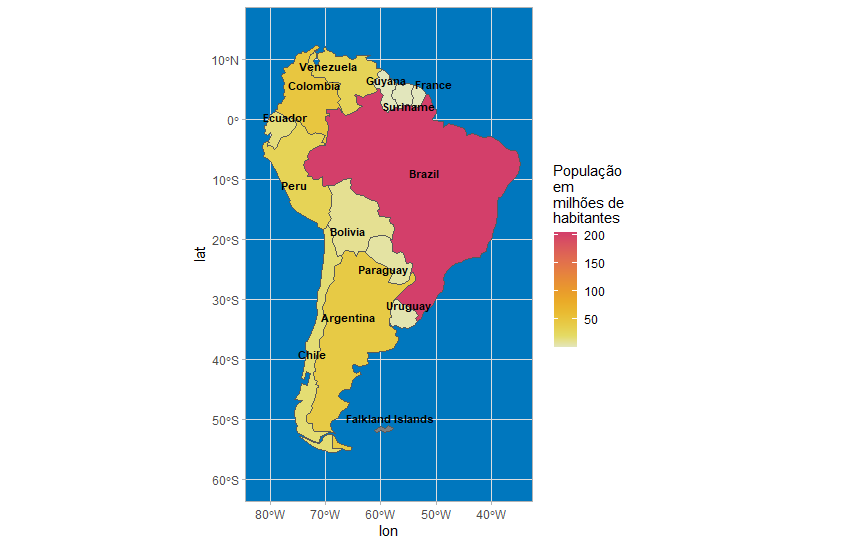

Como você pode ler, usei um pacote R produzido pelo escritório oficial de estatísticas da França para obter a população da Guiana. Além disso, limitei o mapa às coordenadas apropriadas para ver a América do Sul.
Emolduram e aquarelam o meu Brasil
Agora que o herói do mapa finalmente resolveu as questões sul-americanas e fez as pazes com a França, é hora de voltar aos dados e mapas brasileiros. Lembre-se: quero comparar os detalhes do censo brasileiro com outros países e territórios ao sul do Panamá.
Os dados do censo estão disponíveis em um pacote R ou em um endereço de API. Fiz a opção mais desafiadora usando a API. Usar a outra opção em outro momento pode ser uma boa ideia. Veja o código e o mapa abaixo, onde mostro a população dos estados brasileiros em contraste com os outros territórios sul-americanos.
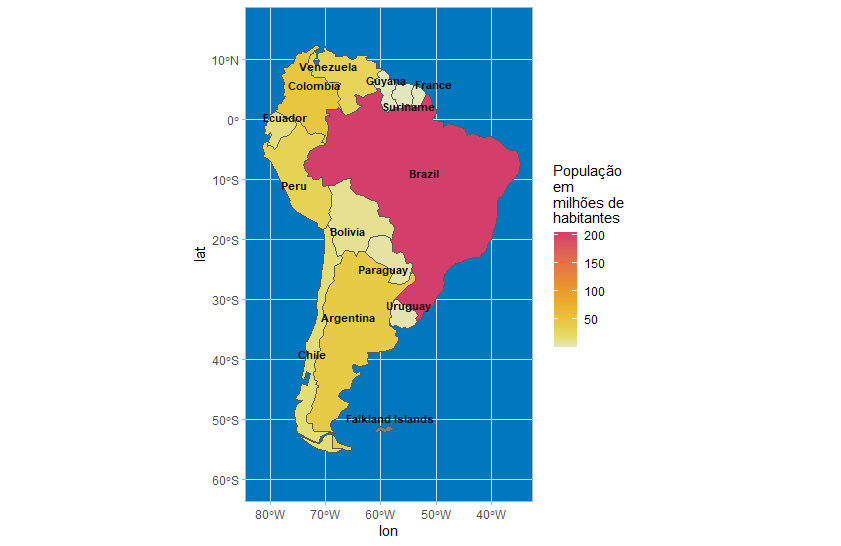

Escrevi a função get_municipalites_data usando a API citada anteriormente. Observe também duas funções que fornecem os shapefiles usados para desenhar os limites do Brasil e de suas sub-regiões: read_country e read_states. Essas funções estão presentes no pacote {geobr}.
Usei outro filtro do dataframe world. Nesse caso, o objetivo é mostrar o início do subcontinente da América Central e pintar seu mapa com um tom de cinza. Aqui, nos deparamos com uma divergência cultural, pois aprendemos no Brasil que as Américas têm três subcontinentes: América do Norte, América Central e América do Sul. Para os autores do conjunto de dados, a América Central é uma sub-região da América do Norte.
Agora é hora de terminar meu trabalho. Quero mostrar os nomes dos oito territórios mais populosos no mapa. Mesmo nesse sprint final, havia alguns truques de código.
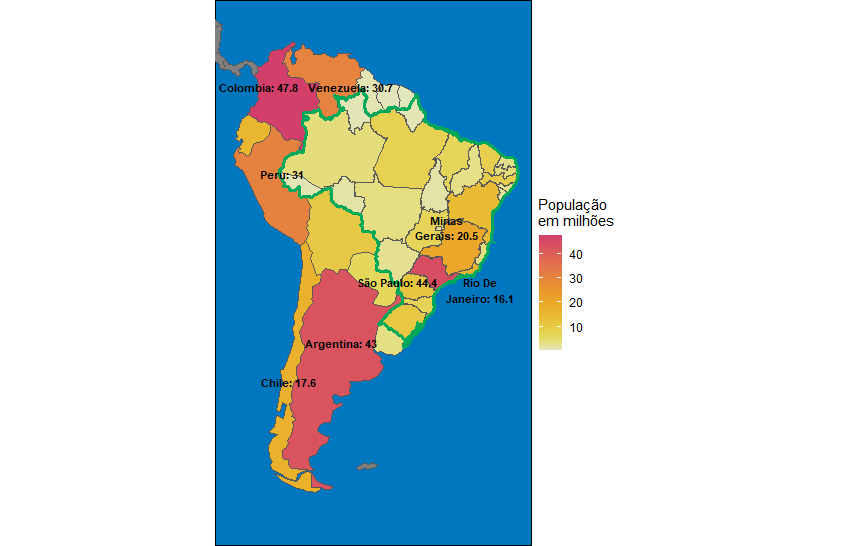

Três estados brasileiros estão entre os oito territórios mais populosos da América do Sul. De fato, São Paulo é o segundo espaço mais habitado no mapa, superando todos os países, exceto a Colômbia.
Agora, concentrando-se no código, você pode ver que criei um novo dataframe para construir essa classificação combinando dois objetos sf diferentes. Selecionei um subconjunto de colunas e alterei o tipo de sf para tibble para habilitar a vinculação de linhas.
Então é isso. O herói completou um caminho possível e deixou as pegadas para a próxima jornada. Agora é a sua vez. Lembre-se de todos os seus projetos que poderiam ter uma melhoria significativa usando uma representação de mapa. Usando o passo a passo acima e reunindo todos os dados disponíveis sobre população, questões socioeconômicas e assim por diante, é só uma questão de escolher a variável para preencher os polígonos.
Código e dados
O código completo está disponível no gist.
Todos os conjuntos de dados brasileiros são caracterizados como de domínio público, pois são dados produzidos por instituições do governo federal, disponibilizados na Internet como transparência ativa e estão sujeitos à Lei de Acesso à Informação brasileira.
IBGE: Dados do censo brasileiro
IPEA: shapefiles brasileiros
Os dados franceses estão disponíveis no portal de dados abertos daquele país e estão listados como Open License, o que permite explorar as informações para fins comerciais.
Esse texto é uma tradução e adaptação do que foi previamente publicado no Towards Data Science.








