
Esse tutorial foi desenvolvido por Anicely Santos, com edição de Adriano Belisario, em abril de 2022.
Construir robôs para automatizar a coleta de dados pode soar como ficção científica para pessoas leigas. Mas engana-se quem pensa que são necessários complexos conhecimentos de programação para começar a raspar dados na web, especialmente se você precisa apenas resolver problemas pontuais.
Diversas ferramentas já permitem realizar este processo por meio de interfaces gráficas. Na Escola de Dados, somos fãs de longa data do Web Scraper, uma extensão que roda diretamente no seu navegador.
Neste tutorial, mostraremos como usar esta ferramenta para extrair dados de atletas do Comitê Olímpico Brasileiro, que estão dispersos em várias páginas. No final, o processo deve resultar em um arquivo CSV semelhante ao que está disponível no seguinte repositório (você pode baixar o arquivo e importar no seu editor de planilhas): https://github.com/escola-de-dados/cob-webscraper
Se você tem noções básicas de HTML e sabe como usar a ferramenta de inspeção dos navegadores, provavelmente terá mais facilidade para seguir nosso passo a passo. Porém, se não é o seu caso, não se preocupe. A ferramenta é bastante simples e, com o nosso tutorial, você irá entender como pode começar a usá-la.
Em caso de dúvidas, use o nosso Fórum para compartilhar seu problema. Só não se esqueça de fazer uma boa pergunta.
Inspetor Web, as ferramentas do desenvolvedor
Existe uma funcionalidade no seu navegador que expande em muito sua capacidade de interagir com as páginas web. Basta apertar F12 ou clicar do lado direito e buscar a opção ‘Inspecionar’. Ou ainda procurar pela opção de “Ferramentas do desenvolvedor” no menu.
É aqui que vamos trabalhar para examinar os sites e montar nosso robô no WebScraper.
Inspecionando uma página utilizando o inspetor de elementos
Como vemos na imagem, enquanto o mouse vai passando pelas tags HTML, é mostrado no site qual área você está inspecionando no código. E vice-versa. É mais ou menos assim que vamos encontrar onde estão os dados que precisamos.
Para praticar, abre o site a seguir, ative as ferramentas dos desenvolvedores e explore o código e as tags livremente: https://www.cob.org.br/pt/cob/time-brasil/atletas
Atenção Para utilizar o Web Scraper, é importante que a ferramenta do desenvolvedor esteja na parte inferior da tela, ao invés do lado direto, como na imagem acima. Se para você estes menus aparecem do lado direito, mude o posicionamento clicando no botão com três pontos, que fica no final das opções do menu da ferramenta dos desenvolvedores. Ao clicar, você verá as opções abaixo:
Perceba que a opção selecionada (em azul) é a opção da ferramenta do lado direito. Para colocar na parte inferior da tela, é só clicar no terceiro ícone.
|
Reconhecendo o terreno
O primeiro passo de qualquer raspagem de dados é um exame atento da forma como as informações estão organizadas no site. Antes de construir uma solução, precisamos entender o problema.
Durante esta navegação inicial, a ideia é tentar identificar quais são as etapas necessárias para se obter as informações e quais são os padrões (na URL ou na forma como o conteúdo está organizado, por exemplo) que estão envolvidos.
Neste tutorial, vamos raspar dados de atletas do Comitê Olímpico do Brasil. Para começar, então, faça um tour na seção do site indicada acima e pergunte-se coisas como:
- Quais são as informações de cada atleta podem ser extraídas?
- Quais são as formas de navegar entre os atletas?
- Como a URL do site muda em cada uma delas?
Na página, logo após o título (“Atletas”), há opções de filtro (Modalidade, competições ou medalhas). Como nosso objetivo é obter dados de todos os atletas, podemos ignorar os filtros. Mas repare que, abaixo, há uma galeria de atletas em ordem alfabética e duas formas de navegar por ela: uma paginação por ordem alfabética acima e embaixo uma paginação por números.
Navegue pela paginação por números. Se você clicar a cada número para trocar de página, você vai observar que a URL do site muda seguindo um padrão.
https://www.cob.org.br/pt/cob/time-brasil/atletas?&page=1
https://www.cob.org.br/pt/cob/time-brasil/atletas?&page=2
O que é possível observar nessas URLs? O número que indica a página (page=2, por exemplo)muda à medida que escolhemos uma nova página. Para seguir neste tutorial, navegue pelo site até identificar qual é o número da última página disponível. Anote-o. Você irá precisar deste número em breve.
A galeria traz informações dos atletas como foto e tipo de esporte. Porém, se você clicar em cada um deles, verá uma página com mais informações, como a ficha técnica, local, data de nascimento e nome completo do atleta, bem como uma mini biografia profissional.
Aqui, vamos definir que nosso objetivo é obter uma planilha final com o nome, esporte, mini bio e ficha técnica de cada atleta.
Para chegar a esse resultado nosso robô vai precisar:
- Identificar as URLs de todas as páginas;
- Identificar cada um dos atletas;
- Identificar informações para cada atleta na página inicial;
- Identificar informações das páginas internas;
- Coletar (raspar) os dados do site;
Agora, vamos instalar o Web Scraper e implementar cada passo deste roteiro acima.
Instalando o Web Scraper
O Web Scraper funciona no modelo freemium. Na versão gratuita, atualmente, é possível programar no seu próprio computador. Já os planos pagos – a partir de $50 – envolvem execuções na nuvem, suporte por email, entre outras vantagens.
Para extrações de dados pontuais, que não precisam ser executadas periodicamente, a ferramenta gratuita é uma ótima solução. A extensão consegue lidar com sites dinâmicos e, no final, exporta os dados nos formatos .CSV ou .XLSX.
No site oficial, há o link apenas para a extensão na Chrome Web Store, mas há também um plugin no Firefox Add-ons. Assim que instalada, a extensão vai aparecer como uma aba a mais na ferramenta do desenvolvedor.
Cada raspador de dados que vamos construir será um sitemap, ou seja, um mapa do site, que vai guiar o robô coletor de informações.
Para implementar o roteiro acima, vamos começar criando nosso primeiro mapa do site (Create New Sitemap > Create Sitemap).
ETAPA 1: Identificar as URLs de todas as páginas
Cada novo sitemap traz uma ou mais páginas iniciais, a partir das quais nosso robô vai começar seu trabalho. Veja abaixo os campos disponíveis.
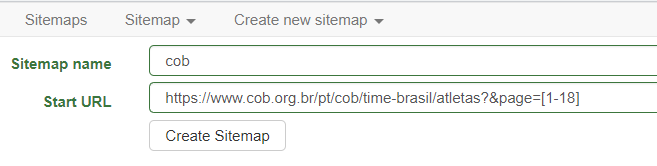
Primeiro, você pode escolher o nome que quiser para seu sitemap (Sitemap name). Depois, precisamos definir uma URL. E é aqui que temos o primeiro pulo do gato.
https://giphy.com/gifs/cat-8u9PS5l5znIbe
Vamos usar a URL com as páginas numeradas que vimos, mas com um pequeno ajuste. Ao invés de especificar apenas uma página, iremos indicar que queremos acessar um intervalo de páginas. Por isso, é preciso saber qual é o número da última página.
Na prática isso significa que, na parte final da URL, criaremos uma expressão colocando a primeira e última página entre colchetes e separadas por hífen. Ou seja, no nosso exemplo, a transformação que faríamos na URL seria esta:
URL ORIGINAL
https://www.cob.org.br/pt/cob/time-brasil/atletas?&page=1
‘START URL’ NO WEBSCRAPER
https://www.cob.org.br/pt/cob/time-brasil/atletas?&page=[1-18]
Vamos usar esta segunda URL para seguir com o tutorial. Clique no botão logo abaixo: Create Sitemap.
Atenção Se a estrutura ou layout do site do Comitê mudar, você pode ainda seguir o tutorial, usando uma versão arquivada no Web Archive. Para fins pedagógicos, você pode fazer a raspagem em algumas páginas usando o seguinte endereço no campo “Start URL” https://web.archive.org/web/20220405144719/https://www.cob.org.br/pt/cob/time-brasil/atletas?page=[1-2] |
ETAPA 2: Identificar cada um dos atletas
Depois de criar um Sitemap, teremos acesso a uma nova opção no menu, que no nosso caso se chama Sitemap cob. Ela traz as seguintes opções:
- Selectors: É a visualização/opção padrão, com detalhes sobre a construção raiz do raspador principal. A arquitetura do Web Scraper obedece etapas hierárquicas, onde teremos um raspador que vai indicar a base do site que precisa ser raspado e vários raspadores dentro dele para pegar os dados dentro do site escolhido;
- Selector graph: Mostra um modelo visual da arquitetura do raspador construído. Quando a bolha está mais escura, indica que tem mais ramificações. À medida que vai clicando, vão apresentando as seguintes;
- Edit metadata: Renomeia o raspador e edita a URL principal;
- Scrape: Edita o tempo que cada raspador vai fazer coleta dentro do site e o tempo que ele deve permanecer na página. O tempo é de milisegundos. Se você observar que não conseguiu coletar todos os dados, edite o page load para aumentar o tempo de permanência do robô na página.
- Browser: Mostra exatamente como vai ficar seu arquivo após os dados serem coletados. O botão Refresh Data possibilita que você atualize essa visualização com novos dados que possam ter sido incluídos na página.
- Export Sitemap: Mostra o script completo do seu robô. É ótimo para você exportar seu robô para outra máquina ou apresentar para alguém ler caso você esteja com algum problema.
- Export data: Baixa os dados coletados no formato .XLSX ou .CSV

Abaixo do menu superior, é possível ver também uma faixa com o nome _root. Nela, você poderá identificar qual é o seu atual posicionamento no caminho (ou árvore) do raspador. No momento, estamos na raiz (root), que representa as informações da página inicial que definimos (Start URL). E, dentro de cada caminho, teremos alguns seletores de informações.
Pareceu confuso? Tente pensar neste caminho como análogo àquele de um arquivo em um computador, ou seja, a sequência de diretórios, pastas e subpastas, necessários um certo recurso. Com a prática, isso vai ficar mais compreensível.
Vamos definir nosso primeiro seletor, clicando no botão Add new selector. E vamos entender melhor as novas opções exibidas e o que afinal são seletores.
Seletores serão a base de qualquer raspador que você queira construir no Web Scraper. Eles identificam informações ou recursos de sites com os quais nosso robô irá interagir de alguma forma.
Aqui, nosso primeiro seletor representará um atleta único. E, depois, criaremos novos seletores para identificar as informações que queremos de cada atleta único identificado. Veja abaixo como preencher os campos.
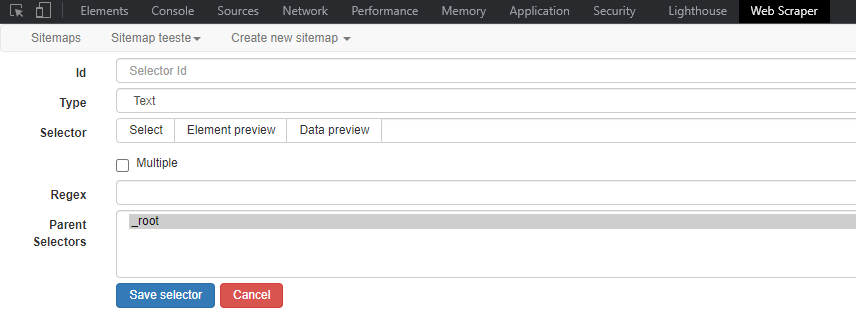
ID
Crie um identificador para o seletor. Aqui, vamos usar a seguinte palavra: atleta.
TYPE
O seletor representa que tipo de recurso no site? É um link a ser clicado? Um texto a ser copiado? Uma tabela? Dominar os diferentes tipos de seletores é a chave para extrair o máximo potencial do Web Scraper. Veja a documentação para saber mais sobre cada tipo. Vamos escolher a opção Element. De acordo com a descrição deste tipo de seletor na documentação, ele serve “para a seleção de elementos que contêm vários elementos de dados. Por exemplo, o seletor Element pode ser usado para selecionar uma lista de itens em um site de comércio eletrônico”. No nosso caso, cada atleta contém outros dados que queremos coletar.
SELECTOR
Lembra que explicamos sobre inspecionar elementos logo no início deste tutorial? Pois bem, é exatamente aqui que ele será importante. Se você souber utilizar a ferramenta de inspeção, poderá escrever os identificados do HTML direto nesse campo. Felizmente, também é possível fazer este processo visualmente, sem examinar o código HTML.
Basta apertar o botão Select e o WebScraper irá transformar o site em um ambiente onde é possível indicar com o mouse qual elemento você quer selecionar. A cor amarela indica a área que pode ser selecionada. Quando clicado, a área fica vermelha.
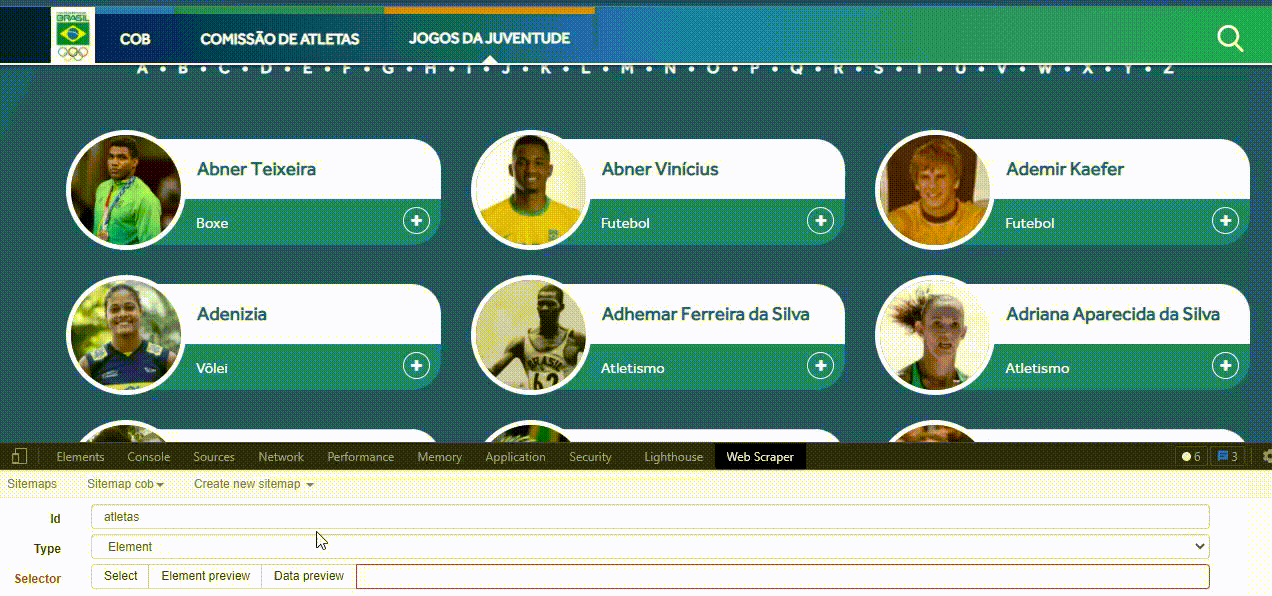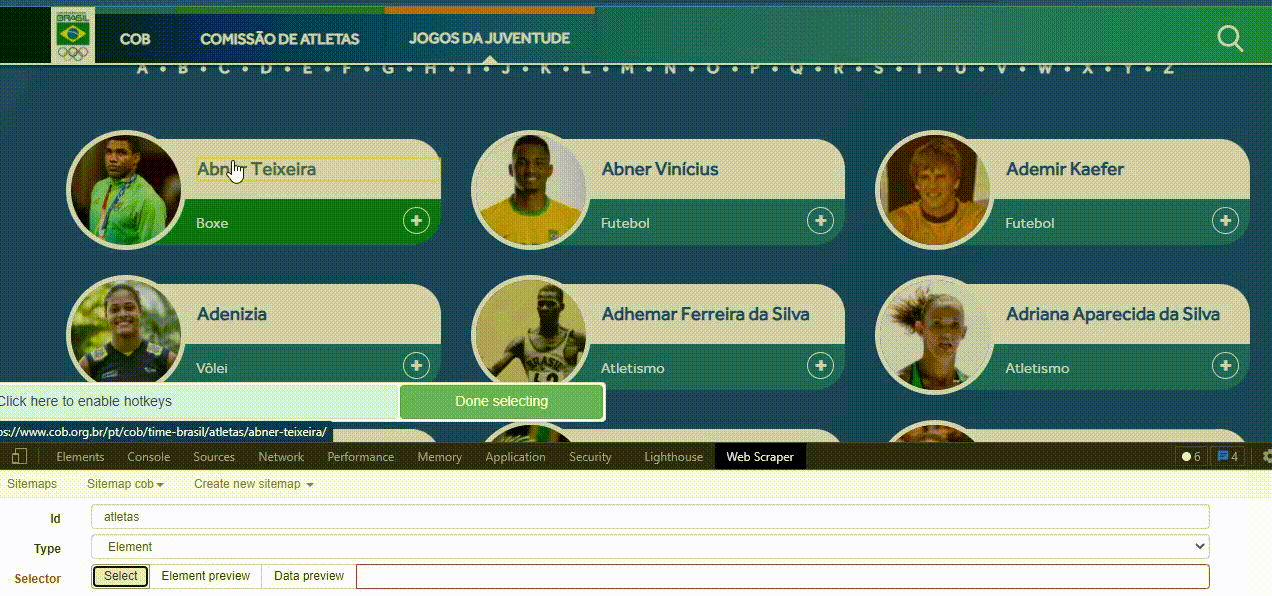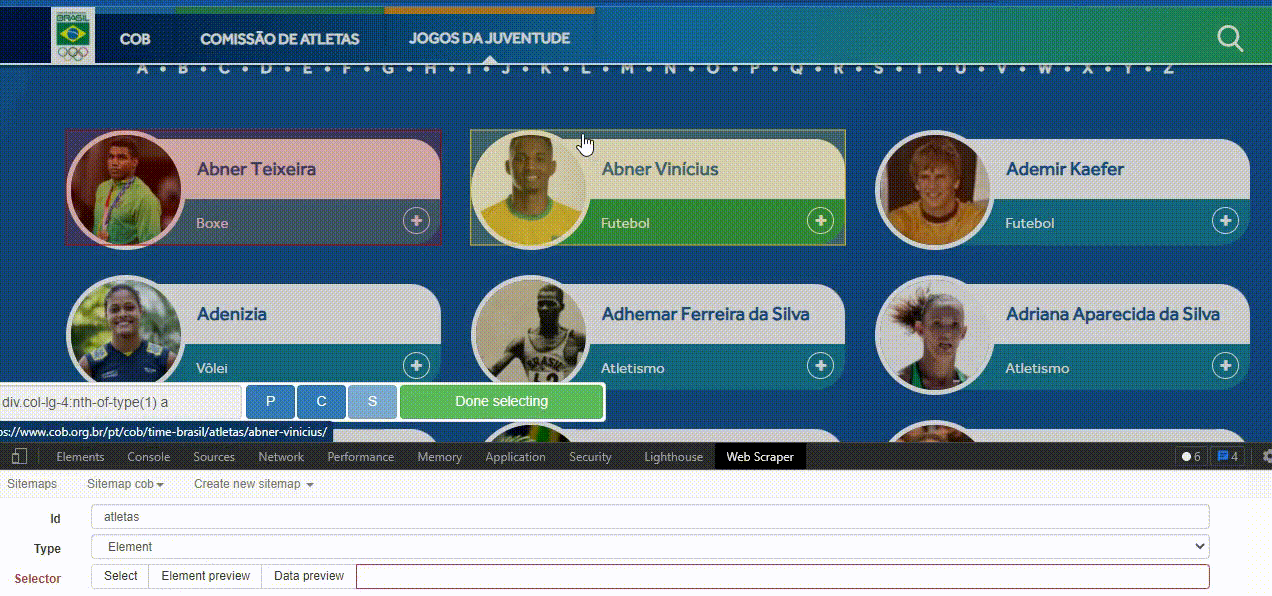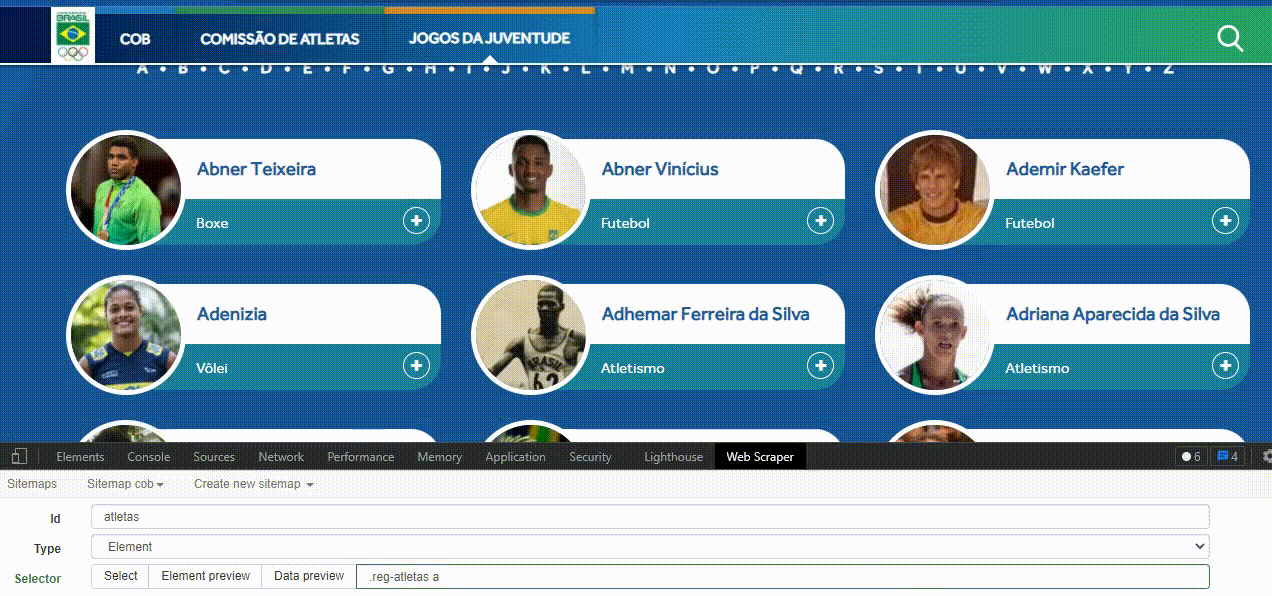
Repare também na parte inferior esquerda uma área azul, inicialmente com o texto ‘Click here to enable hotkeys’. Nela, cada vez que um elemento for selecionado, será possível ver o código HTML que o identifica. Ao lado, temos o botão verde Done Selecting, para salvar este código no seu seletor.
Para encontrar o seletor HTML correto de forma visual, basta tentar buscar com o mouse um quadrado que abranja toda a região onde está o conteúdo que você quer. Feito isso para o primeiro elemento, repita o processo para os demais elementos.
Perceba que quando você vai selecionar o segundo, ele já entende todos os outros e seleciona automaticamente. Depois de todos os atletas estarem destacados em vermelho, como na imagem acima, aperte o botão Done Selecting e o código será salvo na opção “Selector”.
O botão Element preview mostra quantos elementos foram selecionados utilizando o identificador HTML em questão. Já o Data preview apresenta previamente quais dados são coletados, esta opção será mais útil em breve.
MULTIPLE
Este caixa permite sinalizar se múltiplos registros serão extraídos. De acordo com a documentação oficial, quase sempre deve ser selecionada. Por outro lado, nos seletores filhos (os que irão identificar as informações necessárias para cada atleta), não será preciso marcar esta opção.
PARENTS SELECTORS
Aqui indicamos em qual camada hierárquica iremos salvar este seletor. Esse primeiro iŕa ficar no _root (raiz). À medida que mais seletores forem sendo criados, eles aparecerão nesse campo abaixo.
Clique no botão Save selector para terminar esta etapa.
ETAPA 3: Identificar informações para cada atleta na página inicial
Até agora nosso robô só consegue entender que iremos extrair dados de atletas, mas não sabe ainda quais dados. Vamos agora dizer a ele quais. Para cada dado que queremos coletar, criaremos um novo seletor dentro do seletor criado na etapa anterior. Vamos começar com o nome.
Clique no nome do seletor criado na etapa anterior e veja que agora o caminho exibido é “_root / atletas”, ao invés de apenas “_root”.
Isso sinaliza que futuros seletores serão criados dentro do seletor “atleta”.
As etapas a seguir serão semelhantes à criação do primeiro seletor. Vamos criar um novo seletor e definir sua “Id” como nome.
O type será “text”, para extrair/copiar o texto puro (sem formatação) com o nome do atleta.
Para definir o seletor, utilize a mesma abordagem visual para encontrar uma caixa que cubra todo o nome do atleta. Como selecionamos a opção ‘Multiple’, basta clicar no primeiro. Você verá que ele está identificado com a tag h3.
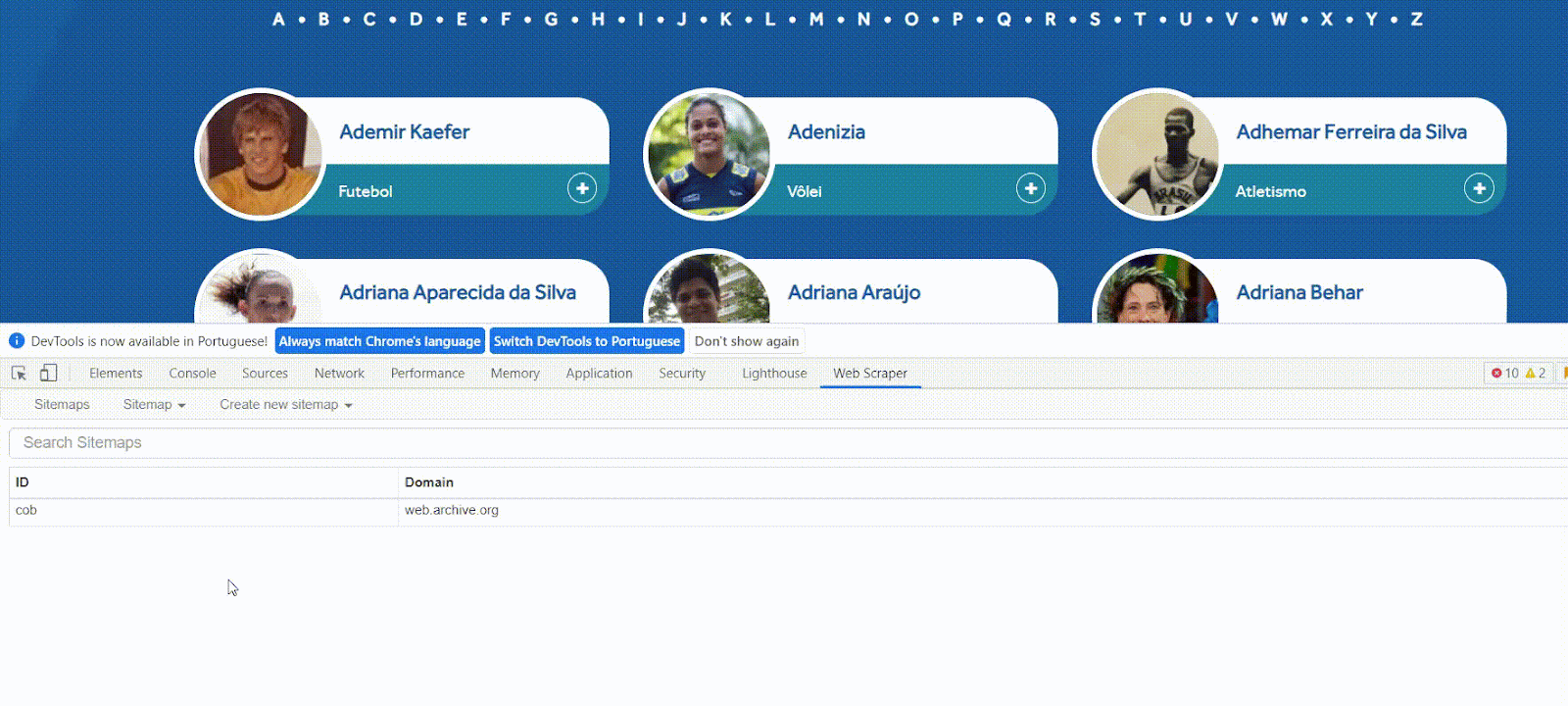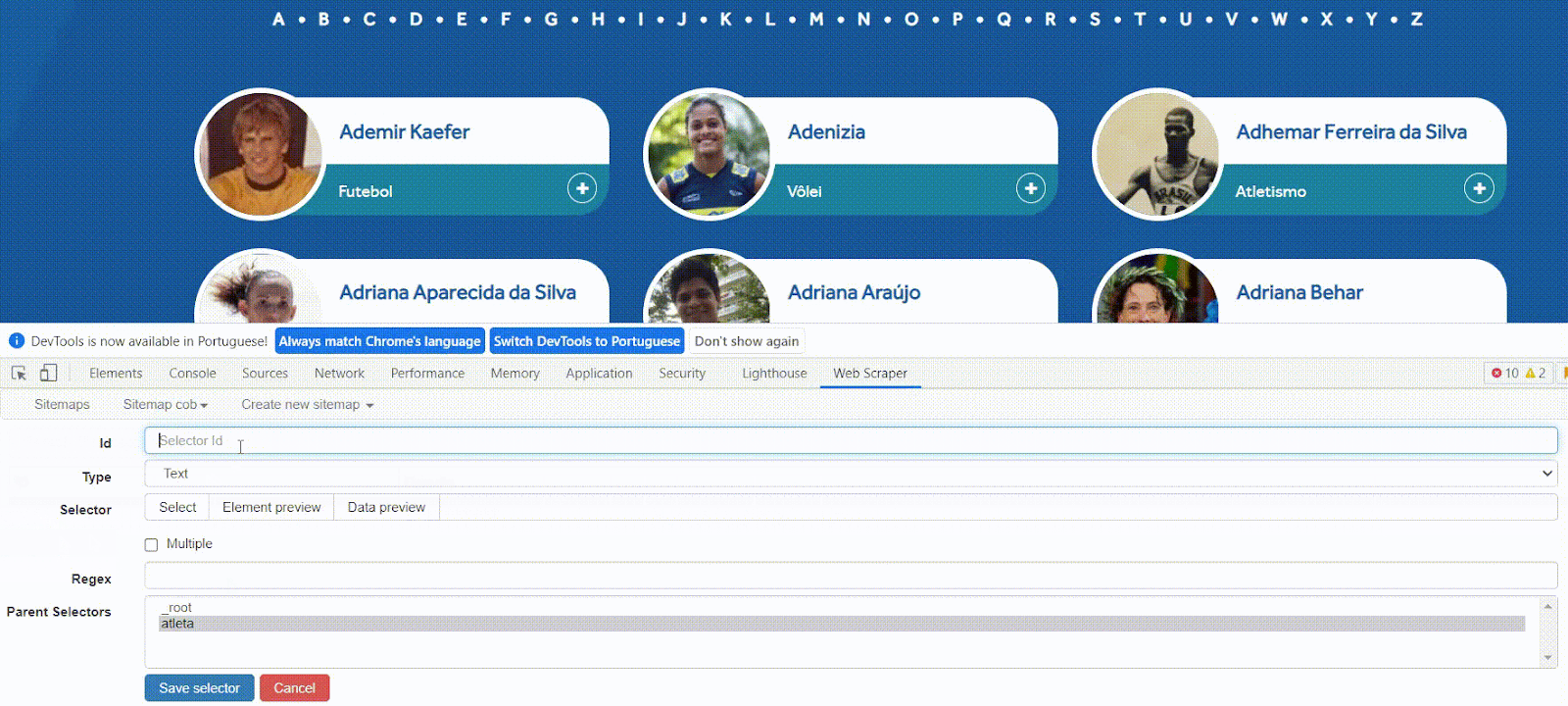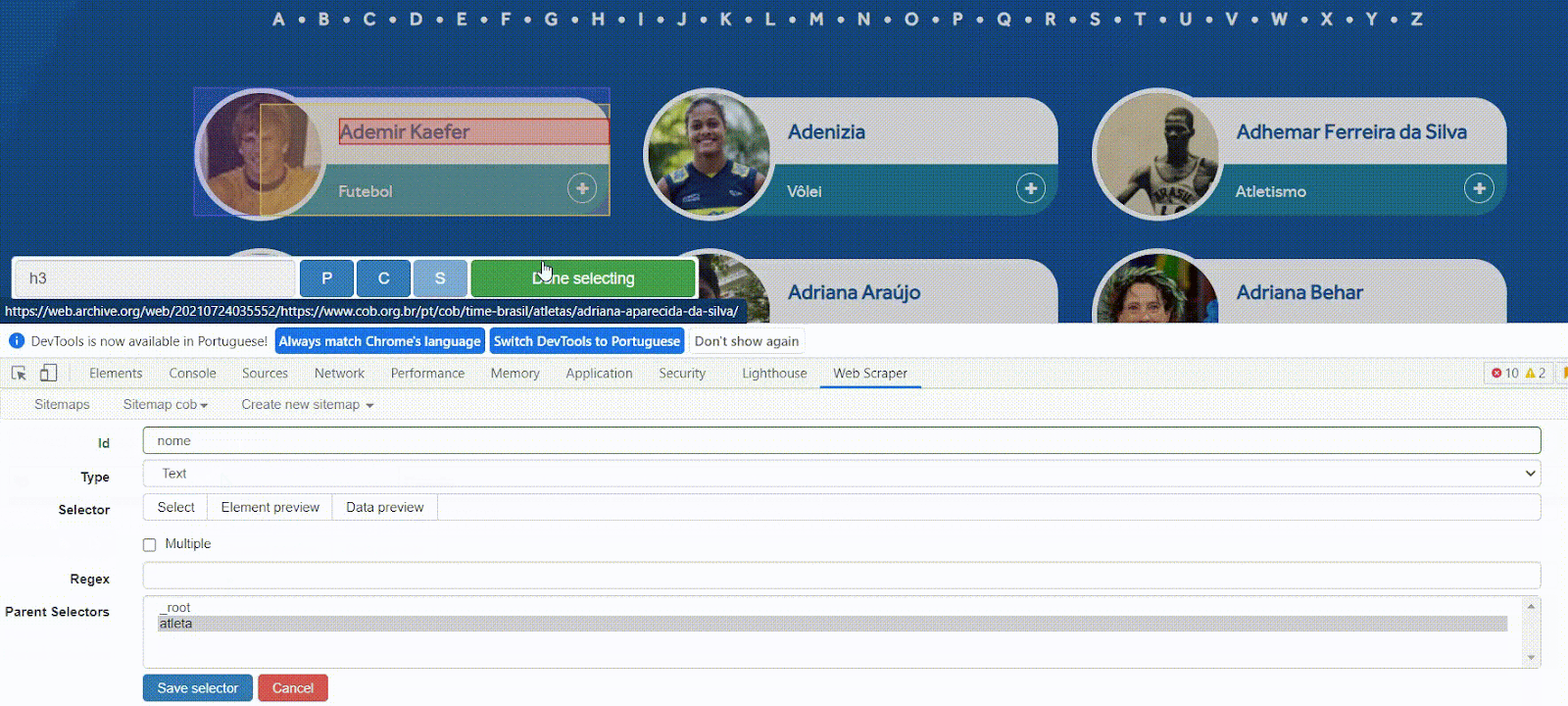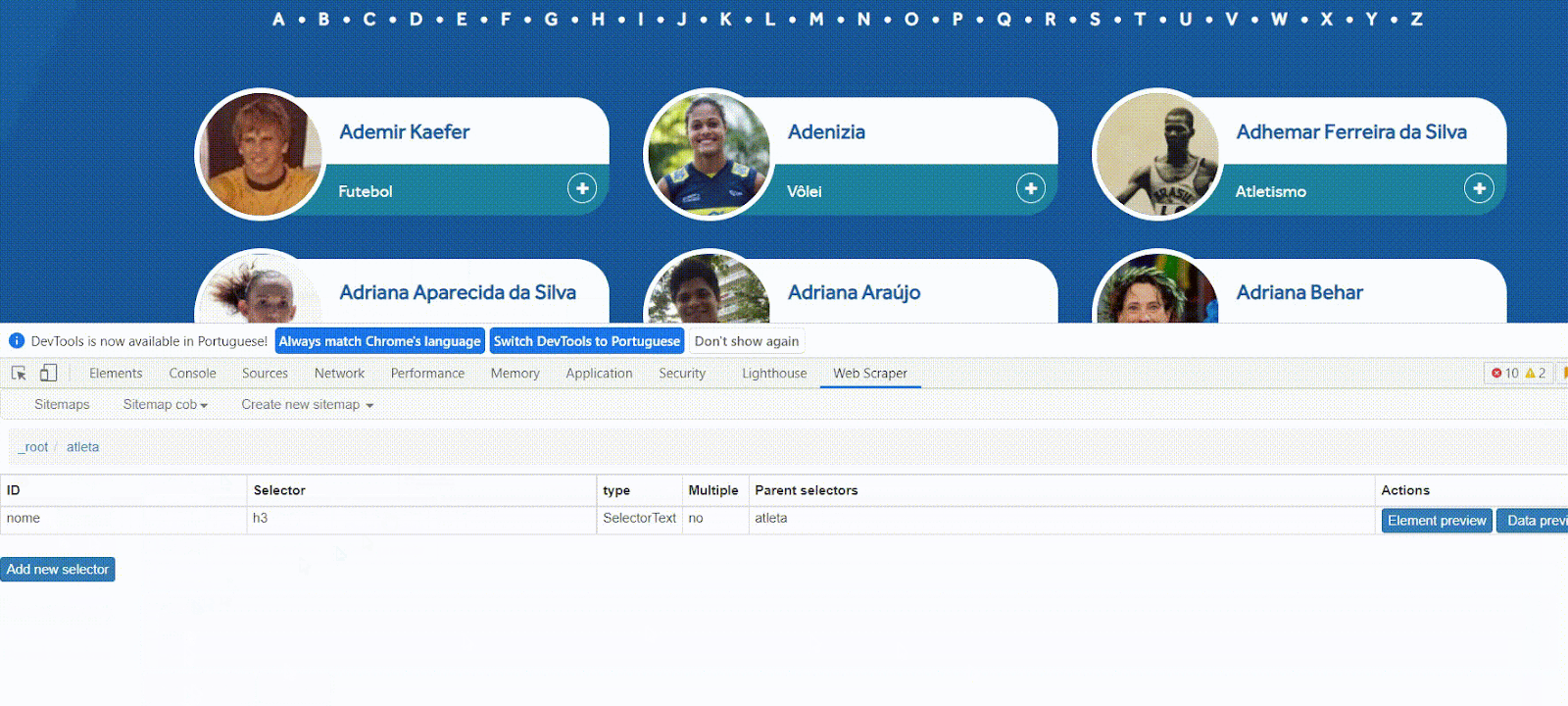
Por fim, em ‘Parent Selectors’, vamos clicar no seletor atleta, que criamos anteriormente.
Seus campos devem estar semelhante a esse:
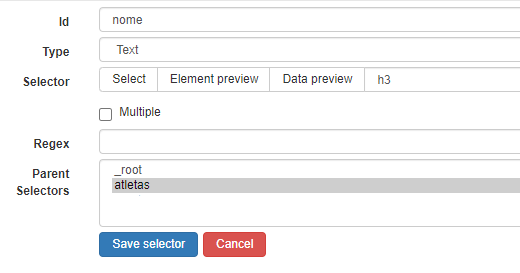
Quando criar seus seletores, use a opção ‘Data Preview’ para checar se os identificadores HTML estarão retornando as informações adequadamente. Você pode clicar neste botão para ver os nomes que seriam coletados na página atual.
FAÇA VOCÊ MESMO
Tente criar um robô que colete o tipo de esporte que o atleta pratica. Se quiser se desafiar um pouco mais, crie outro robô para coletar a foto. Mas saiba que o Web Scraper pode apenas criar uma coluna na tabela com a URL de cada imagem, mas não baixa os arquivos de imagem em si.
ETAPA 4: Identificar informações das páginas internas
Para coletar a ficha técnica e a apresentação (mini bio) de cada profissional, precisamos sair da galeria e acessar a página individual de cada atleta.
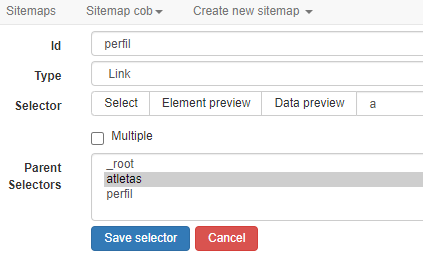
Para simular este comportamento com o robô, criaremos um novo seletor. Sua ID será perfil – claro, você pode escolher outros nomes.
Já no campo ‘Type’ usaremos a opção Link. Este tipo de seletor tem uma dupla função, de acordo com a documentação.
Sem seletores filhos, ele serve apenas para copiar a URL em questão. Caso contrário, esta URL servirá como página inicial para a coleta de novas informações, permitindo que o robô navegue pelo site. Este é o nosso interesse, neste tutorial.
Utilize o mesmo método visual para identificar uma área do site que tenha o link para a página de cada atleta. O link é identificado com a tag a. A opção ‘Parents Selector’ continua sendo ‘atletas’.
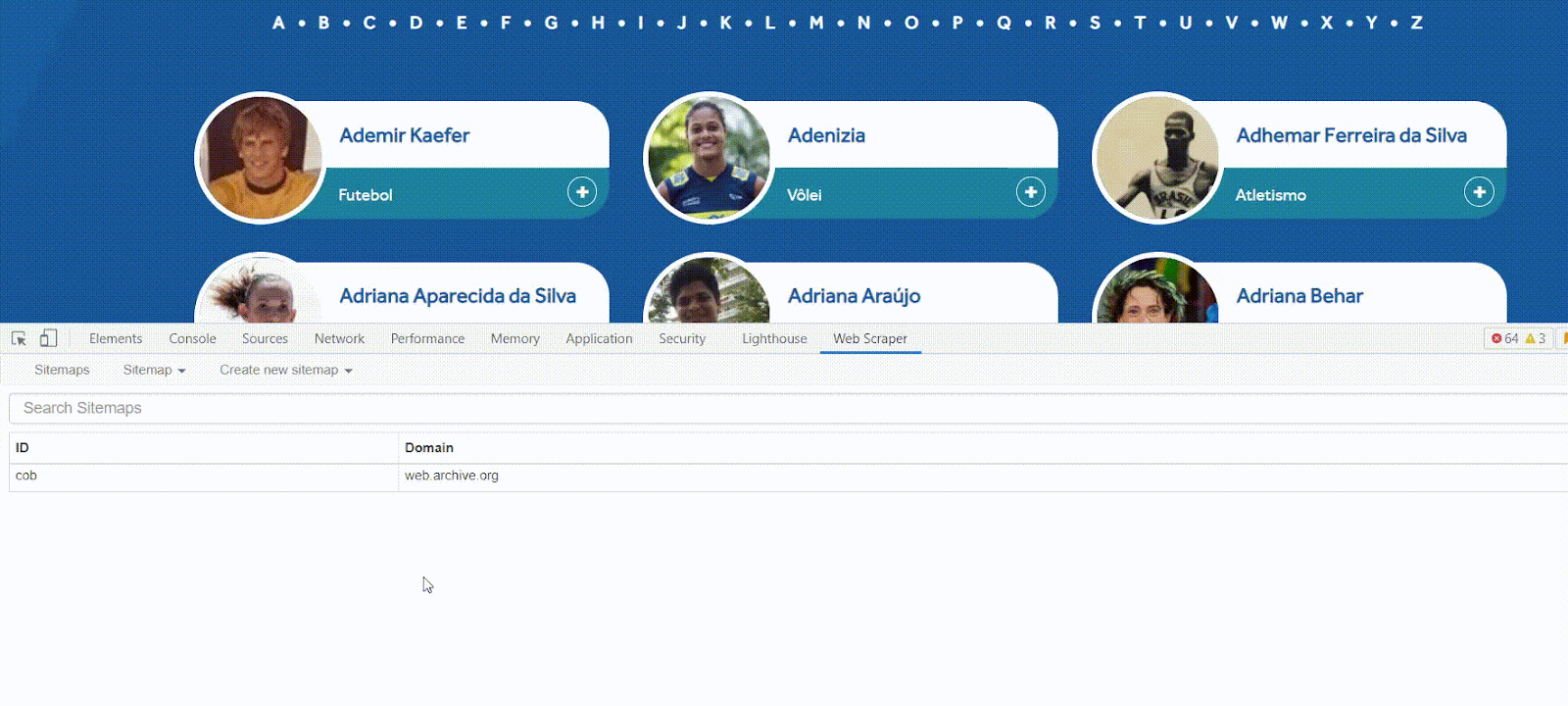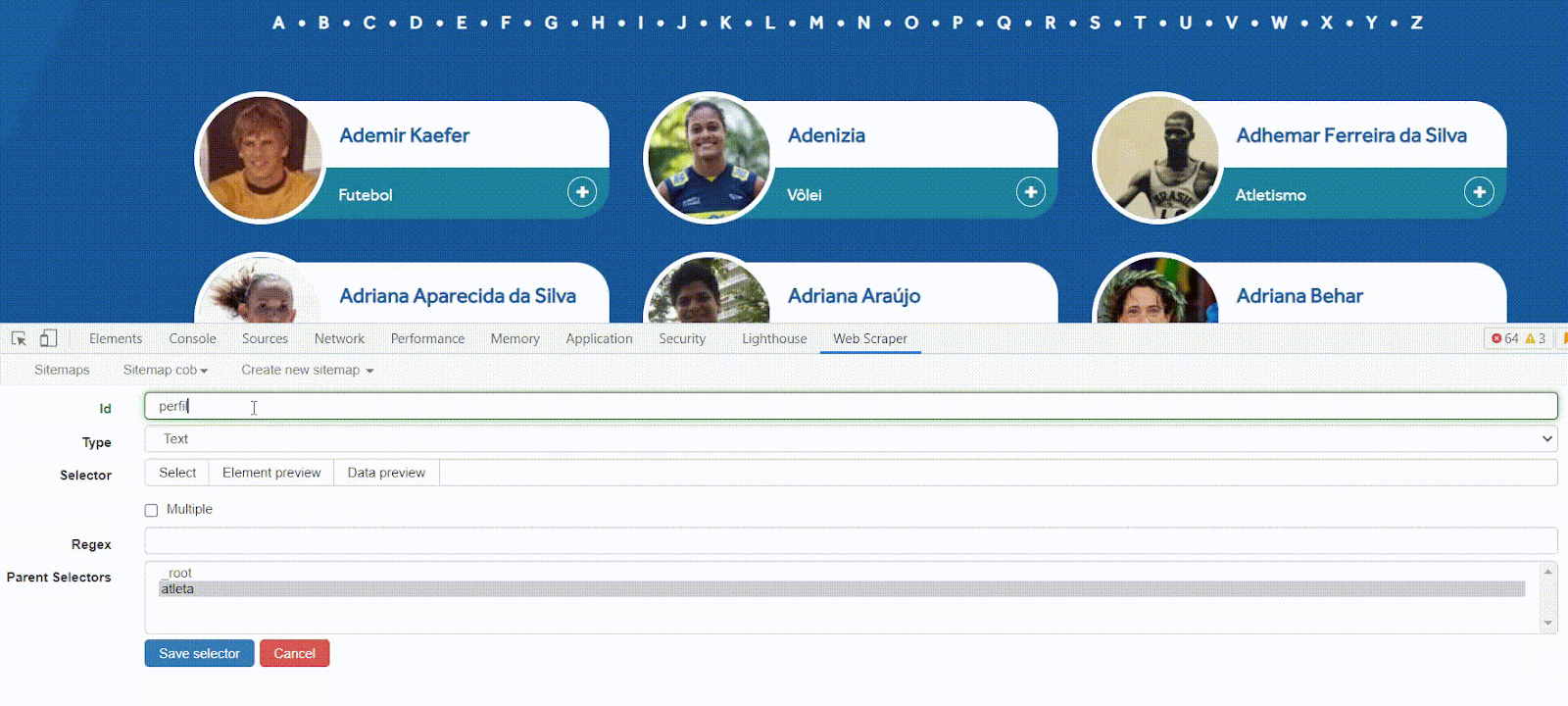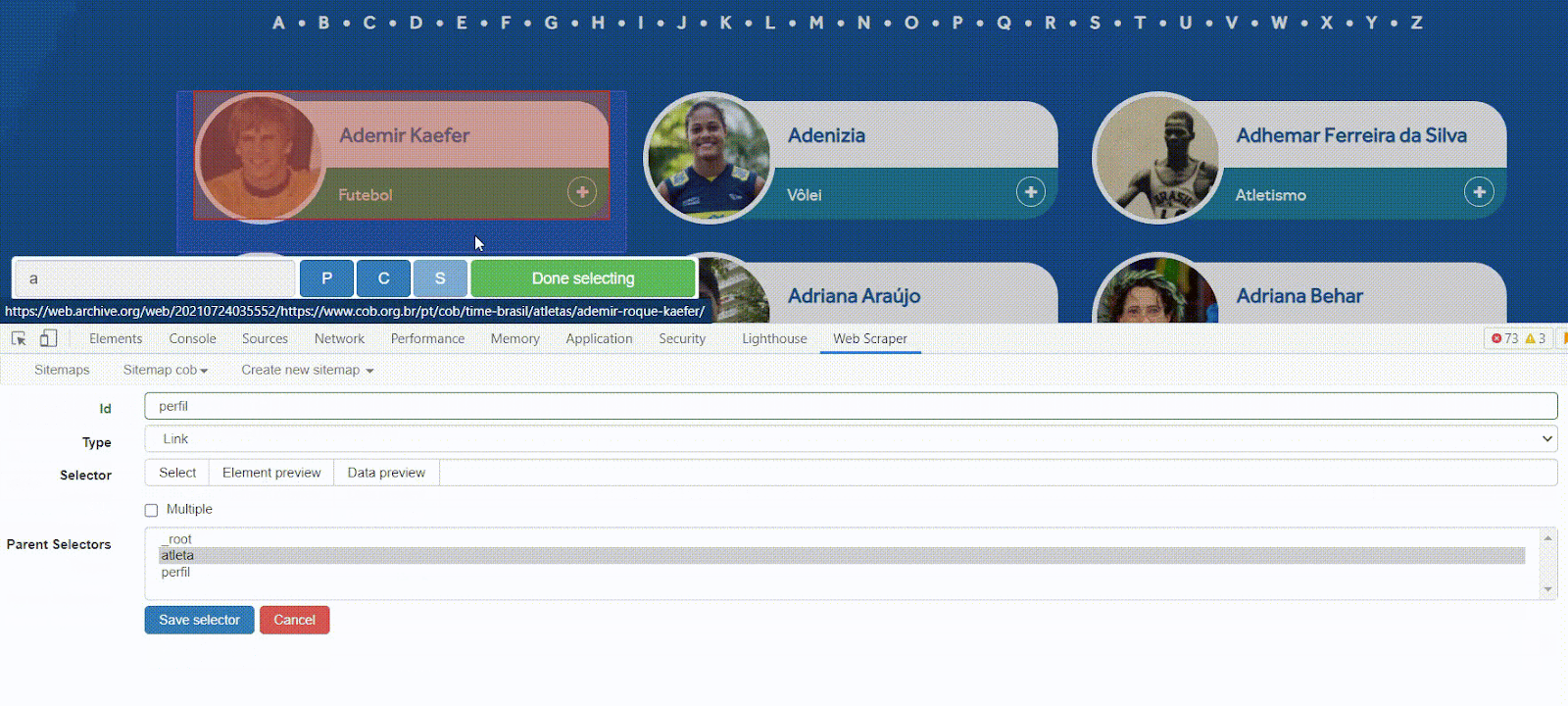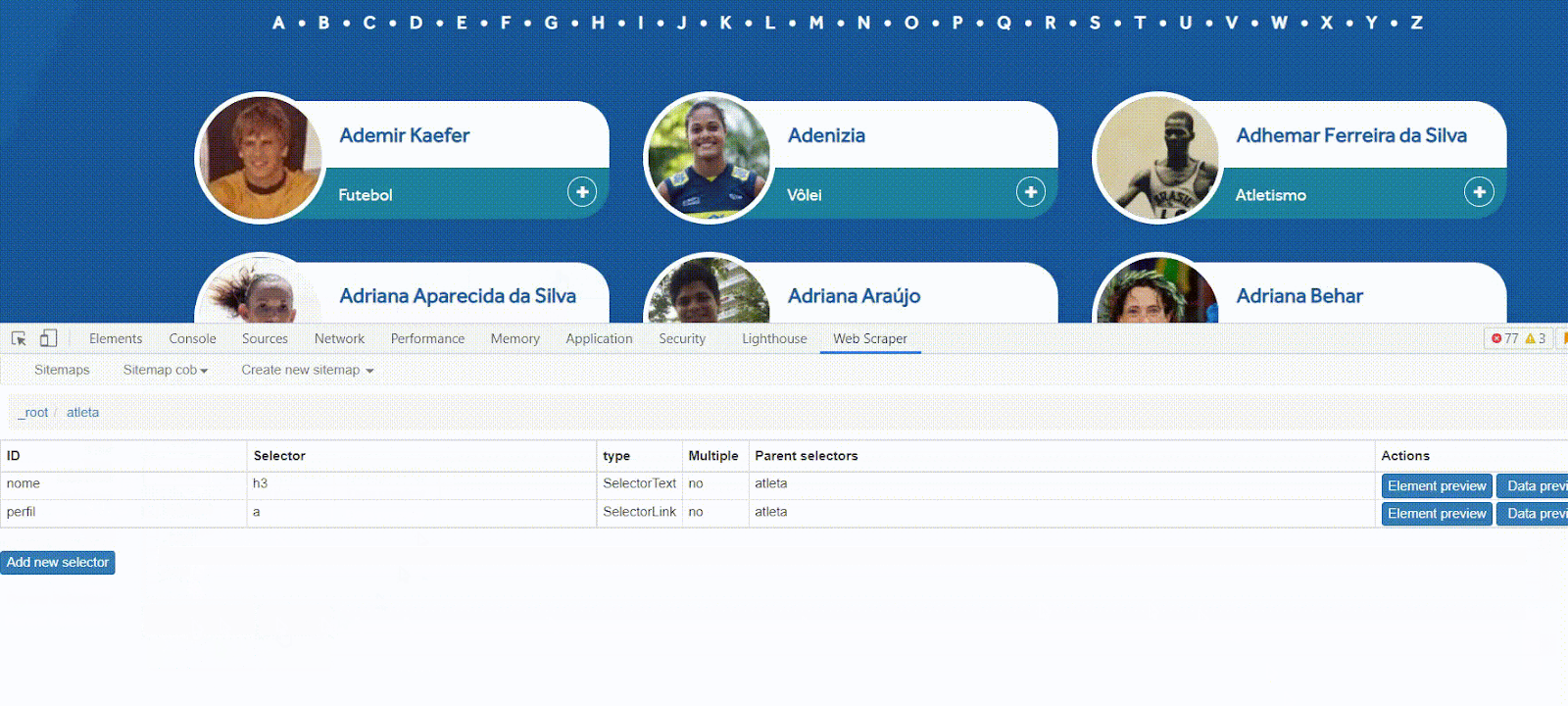
O novo seletor deve ser parecido com esse:
FAÇA VOCÊ MESMO
O próximo passo é criar seletores filhos para este seletor “perfil”. Eles identificarão as fichas técnicas e a mini bio da página de cada atleta.
Crie eles você mesmo. Mas lembre-se de usar a opção Type como ‘Texto’ e definir o ‘Parents Selector’ correto (‘perfil’).
ETAPA 5: Coletar (raspar) os dados do site
Agora é a hora de ver o robô em ação. Volte para a raiz do sitemap principal e clique em Sitemap cob > Scrape > Start Scraping.
Dependendo da quantidade de páginas de sua raspagem, este processo pode demorar. É possível alterar parâmetros que controlam o ritmo de requisições que o robô fará ao site, mas evite colocar valores muito baixos para não sobrecarregar os servidores. Por outro lado, valores maiores podem ser usados para evitar certos mecanismos de prevenção de raspagem de dados, por exemplo. Aqui, vamos manter os valores padrão.
Depois disso, é só aguardar enquanto o Web Scraper faz o seu trabalho. Você irá ver o robô carregando cada página. Quando ele terminar, para exportar os dados, basta ir em Sitemap cob > Export data e escolher o formato de arquivo desejado.
O WebScraper permite também exportar o código por trás de cada raspador, para você salvar ou compartilhar com outras pessoas. Basta selecionar a opção ‘Sitemap cob’ > ‘Export Sitemap’.
Aqui está o código do robô desse tutorial:
{“_id”:”cob”,”startUrl”:[“https://www.cob.org.br/pt/cob/time-brasil/atletas?&page=[1-18]”],”selectors”:[{“id”:”atletas”,”parentSelectors”:[“_root”],”type”:”SelectorElement”,”selector”:”div.col-lg-4″,”multiple”:true,”delay”:0},{“id”:”nome”,”parentSelectors”:[“atletas”],”type”:”SelectorText”,”selector”:”h3″,”multiple”:false,”delay”:0,”regex”:””},{“id”:”esporte”,”parentSelectors”:[“atletas”],”type”:”SelectorText”,”selector”:”span”,”multiple”:false,”delay”:0,”regex”:””},{“id”:”perfil”,”parentSelectors”:[“atletas”],”type”:”SelectorLink”,”selector”:”a”,”multiple”:false,”delay”:0},{“id”:”ficha”,”parentSelectors”:[“perfil”],”type”:”SelectorText”,”selector”:”.shadow p”,”multiple”:false,”delay”:0,”regex”:””},{“id”:”bio”,”parentSelectors”:[“perfil”],”type”:”SelectorText”,”selector”:”.texto p”,”multiple”:false,”delay”:0,”regex”:””}]}
Se você deseja importar este raspador pronto, para comparar com suas tentativas locais, basta ir em Create New Sitemap > Import sitemap, colar o texto acima e clicar em Import Sitemap.
Pronto! Você criou um raspador, obteve os dados e já sabe como compartilhar seu robô com outras pessoas.
Para saber mais
Para melhorar ainda mais suas habilidades no WebScraper e com raspagem de dados em geral, confira nossos outros tutoriais:
Introdução ao XPath para raspagem de dados em HTML
Expressão regular pode melhorar sua vida









Boa noite.
Excelente tutorial, muito importante para o momento que estou vivendo em busca de skills na área de dados.
Parabéns, agregou demais para mim.
Agradecemos o retorno, Paulo! Esperamos que faça bom proveito dos tutoriais que vêm por aí 🙂