
Este texto é baseado no tutorial escrito por Marco Túlio Pires para o curso de raspagem de dados oferecido pela Escola de Dados e o Knight Center em 2016.
O texto foi revisado e atualizado por Adriano Belisário em 2018.
O XPath é uma linguagem de consulta que nos ajuda a navegar por documentos que usam marcadores, como os arquivos XML (Extensible Markup Language) e HTML (HyperText Markup Language). Para você que já entende o básico de HTML, aqui será possível ter uma introdução sobre como usar XPath para extrair informações deste tipo de documento.
No HTML, as informações ficam agrupadas em tags, lembra? Por exemplo: <body>, <title>, <b>, etc. Estas tags ficam agrupadas, mais ou menos do mesmo modo como organizamos um esquema de arquivos e pastas ou hierarquizamos elementos em uma visualização em árvore.
Acima, vemos diretórios e arquivos organizados em pastas e em uma visualização em árvore de um documento HTML. Para chegar de um ponto a outro, você precisaria navegar por estas hierarquias e níveis até encontrar o elemento que procura. O XPath funciona mais ou menos como uma rota para esta navegação.
A grande sacada do XPath é conseguir localizar pontos específicos do documento HTML com “endereços“, navegando por estes elementos aninhados, como as tags pais (parent) e filhas (child). Assim como as pastas no seu computador, os elementos pelos quais o XPath vai navegar são hierarquizados usando barras ( / ) como separadores.
Entender o XPath para raspar dados é importante porque, em geral, você não está interessado em todos elementos de um website, mas apenas em um dado, uma lista de nomes ou uma tabela específica.
Boa parte do trabalho de mineração de dados e raspagem está relacionado a encontrar um padrão que facilite a extração das informações desejadas. Quando se trata de páginas na web, isto envolve também entender a fundo como o dado está sendo disponibilizado, ou seja, qual a estrutura do site e os caminhos que te permitem chegar ao elemento desejado.
Nestas horas, seu melhor amigo será o Web Inspector do seu navegador. Esta é funcionalidade presente na maioria dos navegadores mais utilizados hoje, que permite vermos os códigos por trás do sites que abrimos no navegador.
Para encontrá-la, dê um clique do lado direito em qualquer lugar da página, e vá em “Inspecionar” ou “Inspecionar o elemento”. Agora, sim, estamos pronto para ver como o site funciona por dentro.
Vamos ver como XPath funciona para um caso real: extrair os dados de uma tabela que aparece em uma página Web.
Sim, existem ferramentas que fazem extração automática de tabelas e, para casos como esses, pode ser mais rápido utilizá-las. Um exemplo é a biblioteca Python rows, que também possui uma interface de linha de comando, capaz de converter tabelas de HTML para CSV e outros formatos.
De qualquer forma, sabendo XPath você poderá extrair qualquer dado de um HTML. Então, vamos lá…
Extraindo dados do Governo Federal com XPath e Google Spreadsheet
Neste exemplo, vamos usar XPath para extrair automaticamente dados do site de Transparência do Governo Federal e, então, processar isso no Google Spreadsheet.
Vamos supôr que você precise ter uma célula em uma planilha com o número exato de pessoas beneficiadas com programas sociais no Orçamento do Governo Federal. E, claro, você quer que este número esteja sempre atualizado, para não precisar consultar manualmente o site oficial a cada vez que queira utilizá-lo.
Primeiro, vamos abrir a página com os resumos das despesas correntes do Portal da Transparência.
De cara, vemos que há uma lista de valores, logo no início do site. Dali, queremos extrair respectivamente os números dos campos “Pessoas Físicas (incluindo os programas sociais)” e “Pessoas Físicas (sem os programas sociais)”.
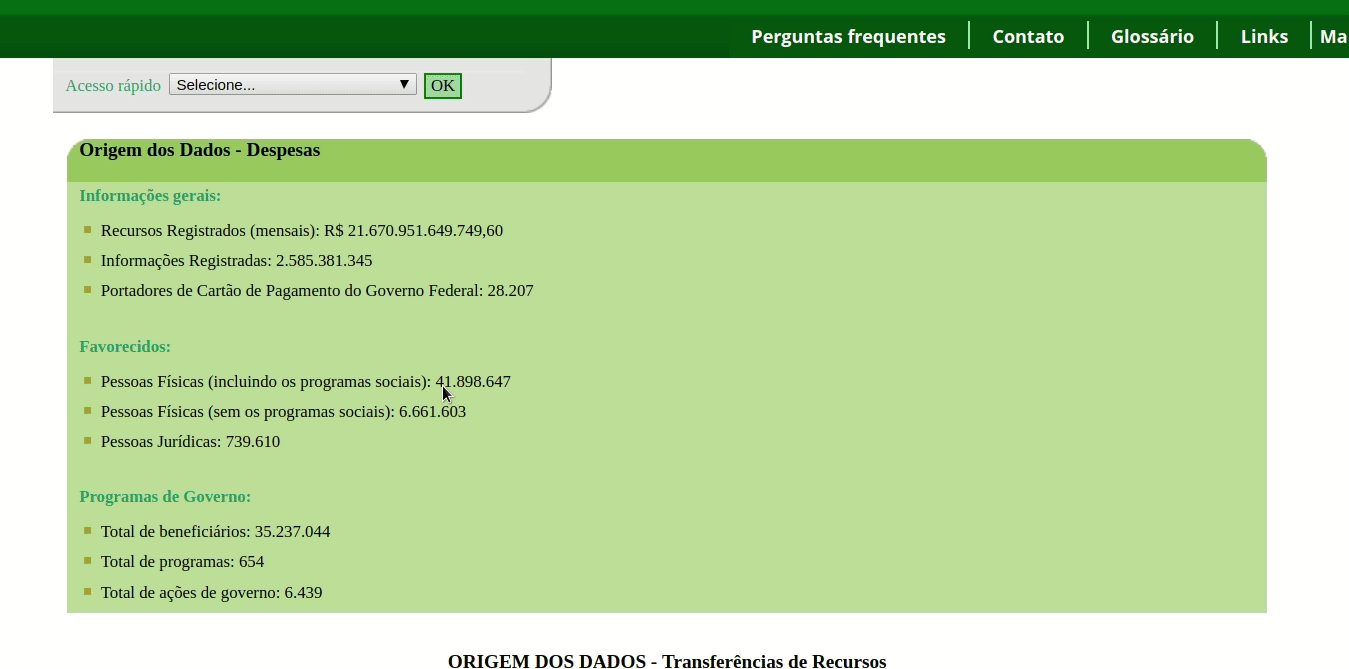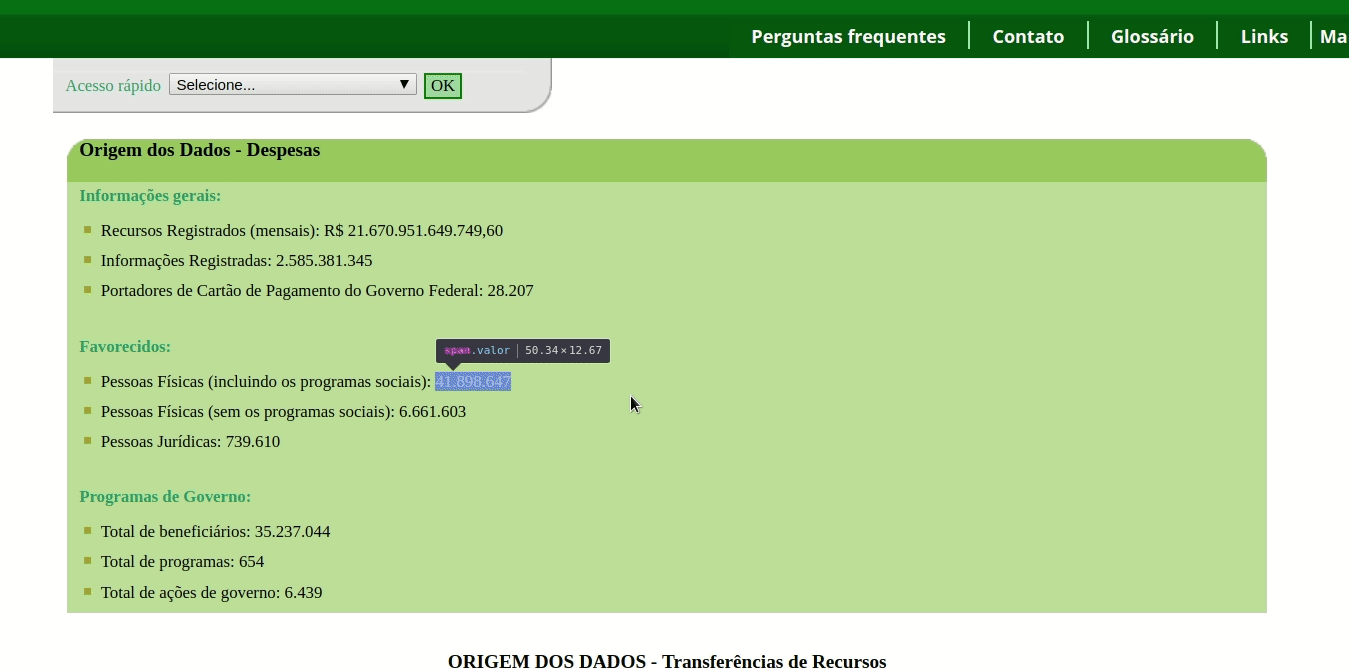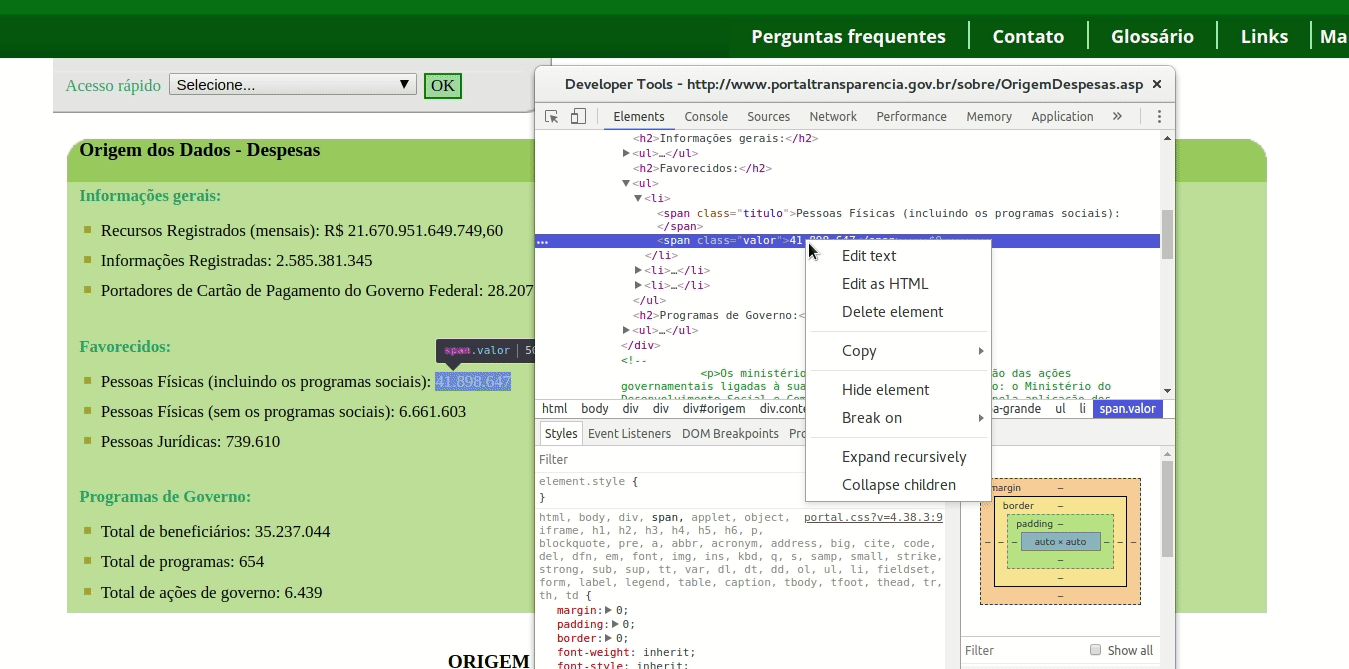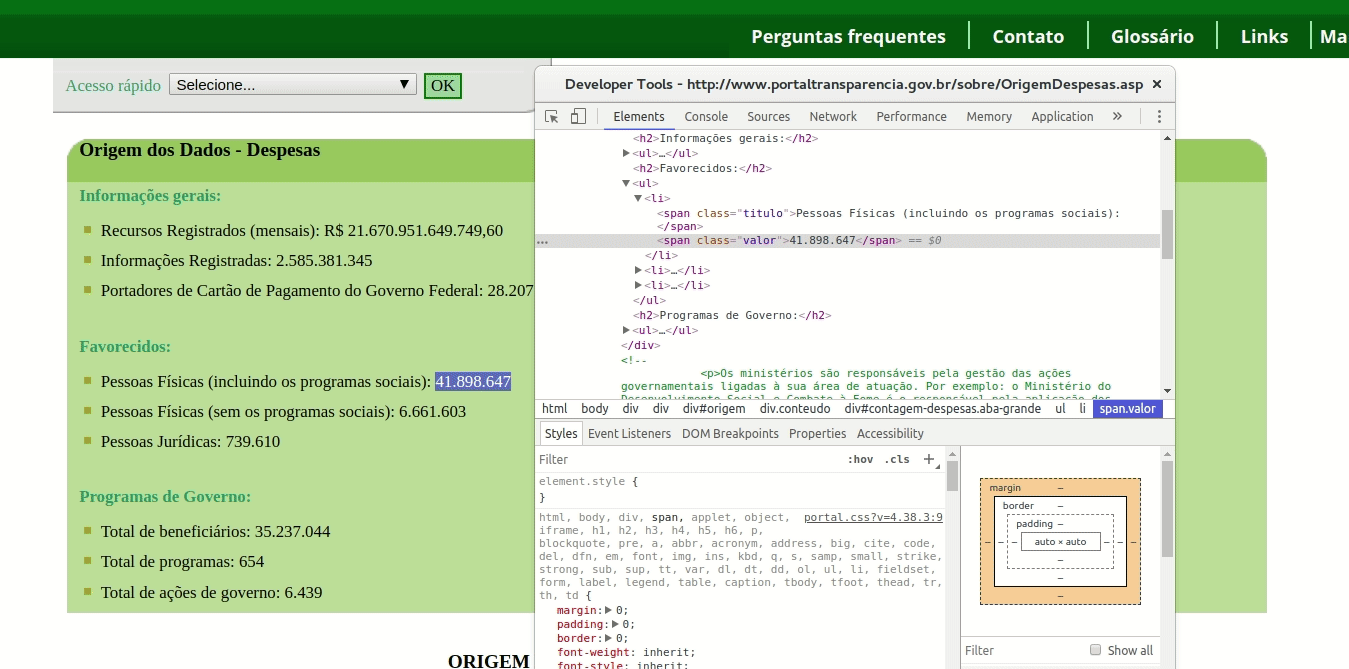
A primeira coisa a fazer é usar o Web Inspector para analisar o código HTML do site. Repare que há uma tag div com a id contagem-despesas, onde todos os dados estão inseridos.
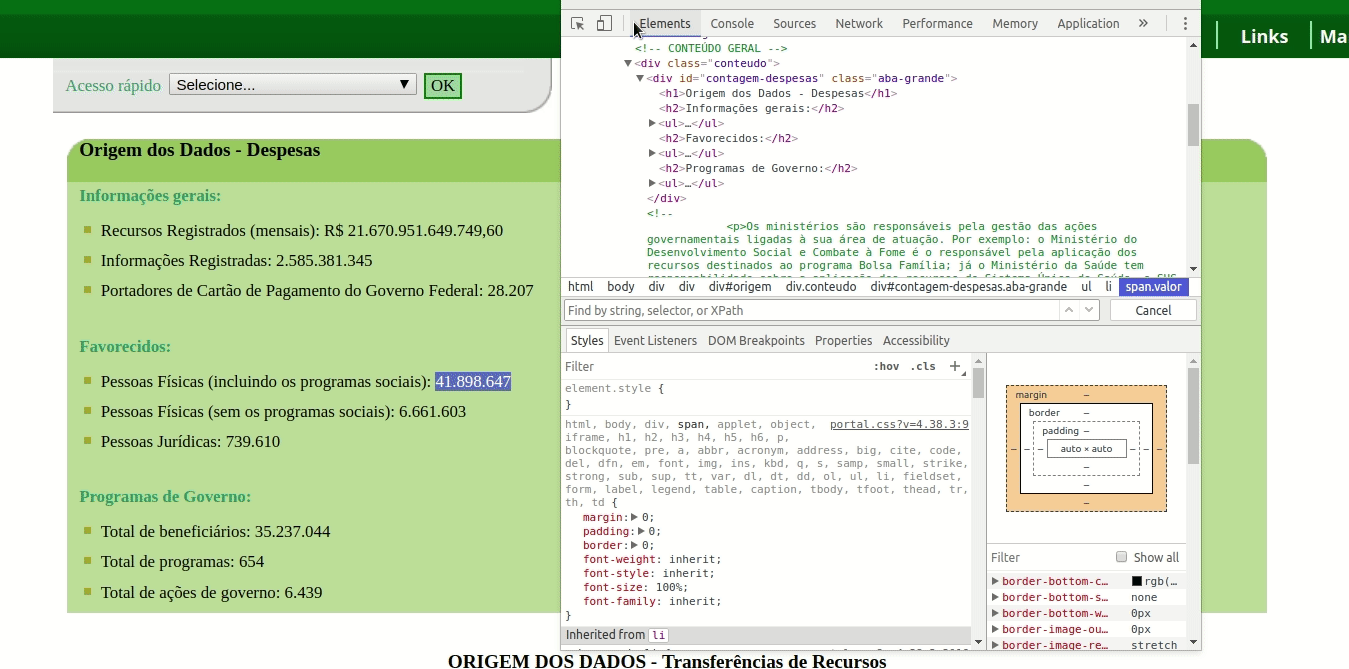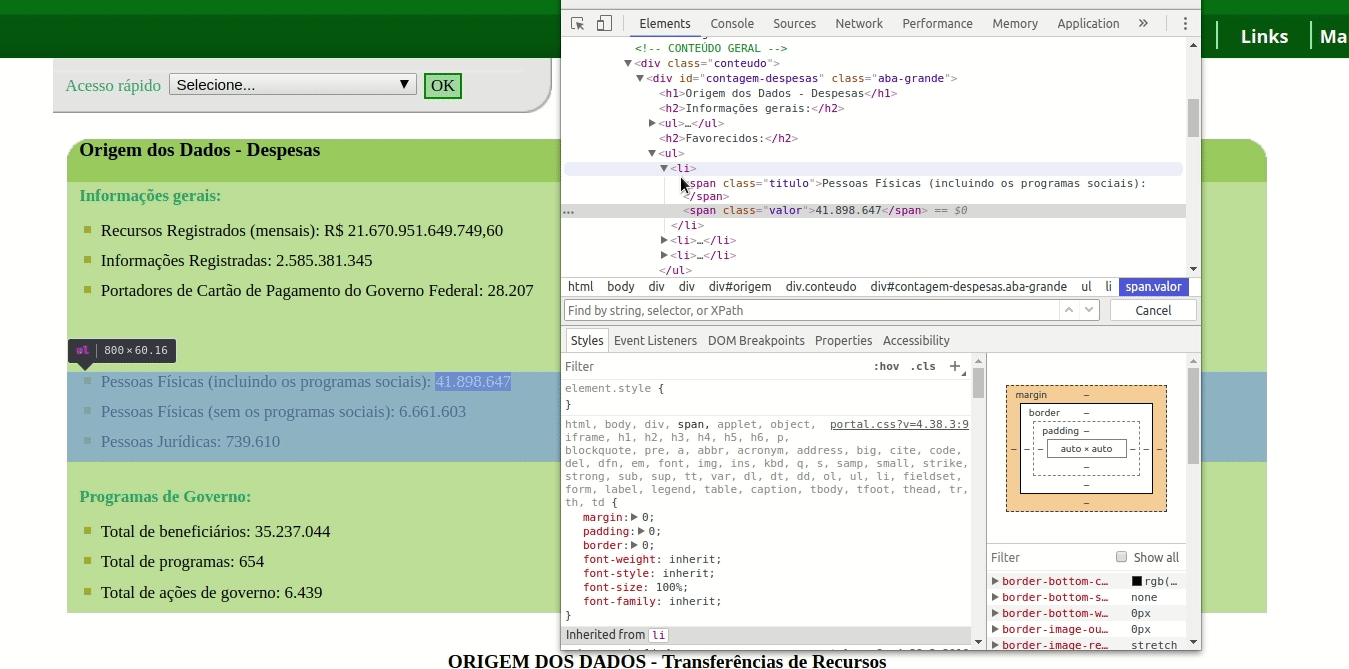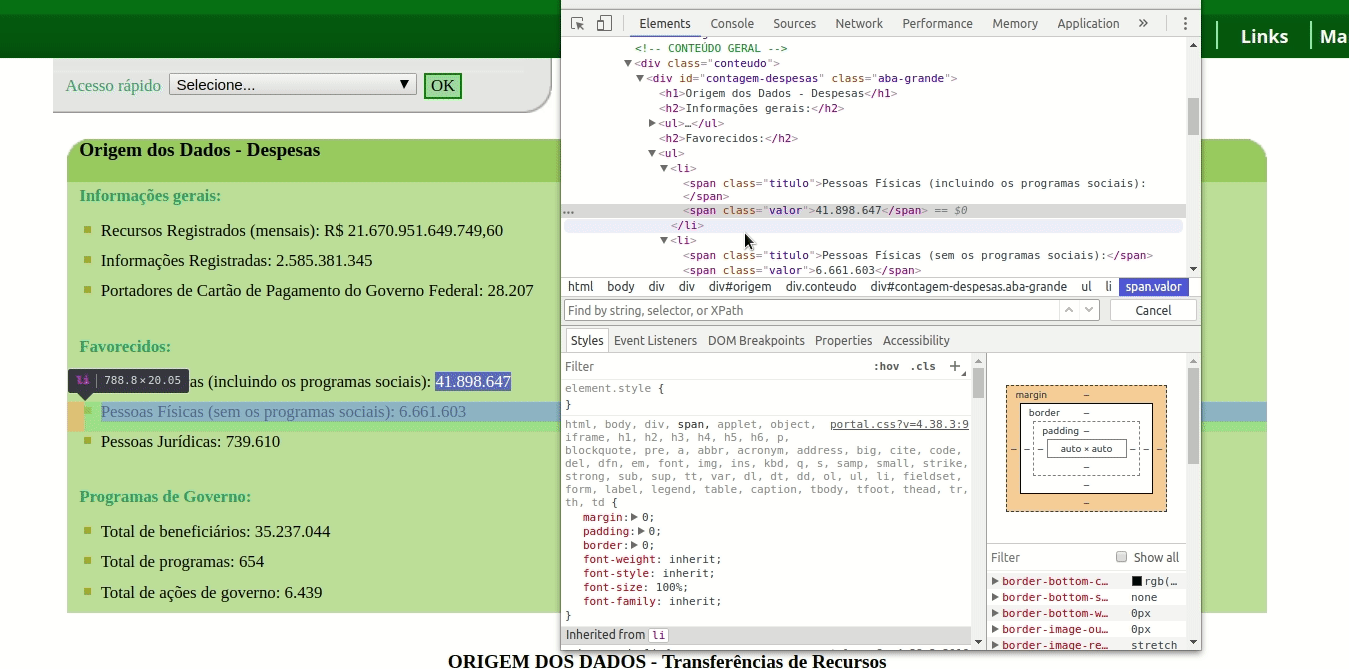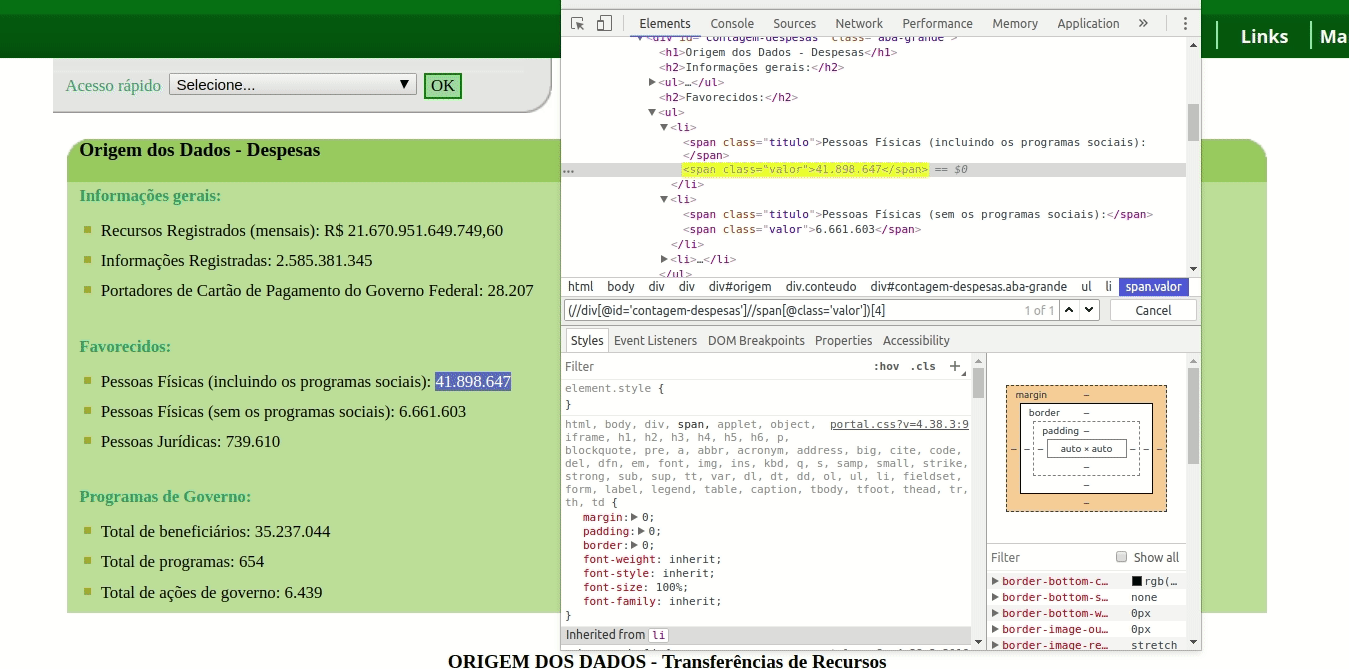
Em qualquer deslocamento, sempre é possível fazer diferentes rotas para chegar ao mesmo lugar. Do mesmo modo, no XPath, podemos escrever diferentes caminhos ou endereços para localizar a mesma informação.
O modo mais rápido de obter um endereço XPath geralmente é utilizando o próprio WebInspector. Basta selecionar o texto que deseja copiar, ir em ‘Inspecionar Elemento’, clicar do lado direito sobre o código HTML correspondente e selecionar a opção ‘Copiar XPath’.
Neste caso, o seguinte endereço é copiado para nossa área de transferência:
//*[@id=”contagem-despesas”]/ul[2]/li[1]/span[2]
Vamos analisá-lo da esquerda para a direita, para entender como o elemento desejado é traduzido neste endereço, dos itens mais genéricos para os mais específicas:
| // | as barras duplas indica que o que formos achar está em qualquer parte do documento |
| * | expressão coringa, o asterisco retorna qualquer marcador (tag), desde que tenha a condição a seguir |
| [@id=”contagem-despesa”] | os colchetes indicam uma condição que retorna apenas as tags com atributo id igual à palavra geral |
| / | a barra simples determina que o elemento seguinte está imediatamente dentro do anterior, no caso qualquer tag com o id igual a geral |
| ul[2] | Seleciona a segunda tag ul |
| /li[1] | Dentro dos elementos descritos até então, seleciona a primeira tag li |
| /span[2] | Dentro dos elementos descritos até então, seleciona a segunda tag span |
Esta função é interessante, mas nem sempre vai ter expressões legíveis ou curtas. Por isso, vale a pena aprender pelo menos o básico da sintaxe XPath para você conseguir adaptá-la ou construir suas próprias expressões!
Como dito, todos os dados estão dentro de uma tag div com o atributo ID igual a “contagem-despesas”. Dentro desta div, logo na sequência, temos algumas tags h1 que não nos interessam, depois – dentro da segunda tags ul e dentro da segunda tag span com o atributo “class” igual a “valor” – finalmente temos o valor que queremos.
Obviamente, se a estrutura da página for alterada, o endereço também precisaria ser modificado. No entanto, atualmente, um outro modo válido de descrever com XPath este elemento (Favorecidos de Pessoas Físicas, incluindo os programas sociais) seria:
(//div[@id=’contagem-despesas’]//span[@class=’valor’])[4]
Veja na imagem abaixo que ao buscar esta expressão com o Web Inspector do Chrome, encontro justamente o valor que estou buscando.
A grande diferença aqui é que “encapsulamos” uma consulta entre parênteses, indicando uma condição por meio do uso [ ]. No exemplo, buscamos a quarta ocorrência da expressão entre parênteses.
Esta expressão (//div[@id=’contagem-despesas’]//span[@class=’valor’]) primeiro busca, em qualquer altura do documento (//), alguma tag div com a condição de que esta tenha o atributo “id” igual a “contagem-despesas” (div[@id=’contagem-despesas’]). Em qualquer nível dentro desta última div (//), então, busco por uma tag span com o atributo class igual a “valor”.
O caminho acima nos retornaria todos 9 valores exibidos naquele trecho da página. Por isso, precisamos indicar a condição de selecionar apenas a quarta ocorrência, que sabemos ser referente ao dado desejado. Se quisermos saber o valor dos favorecidos sem considerar os programas sociais, uma vez que este é o elemento seguinte da lista, bastaria manter a mesma expressão, apenas alterando o valor 4 por 5.
Agora que já entendemos como identificar o elemento que queremos, vamos ver como extraí-lo automaticamente para uma tabela no Google Spreadsheet.
Usando XPath em uma tabela online
No Spreadsheets, a função importXML é parecido com a importHTML, mas muito mais poderosa. Com ele, você consegue importar praticamente qualquer informação do código. Ele precisa de dois parâmetros: apenas a URL e o caminho XPath do elemento, com aspas e separados por ponto-e-vírgula.
O formato é este:
=IMPORTXML(“site”;”caminho_XPath”)
Entendeu? Então, vamos adaptar para o nosso caso:
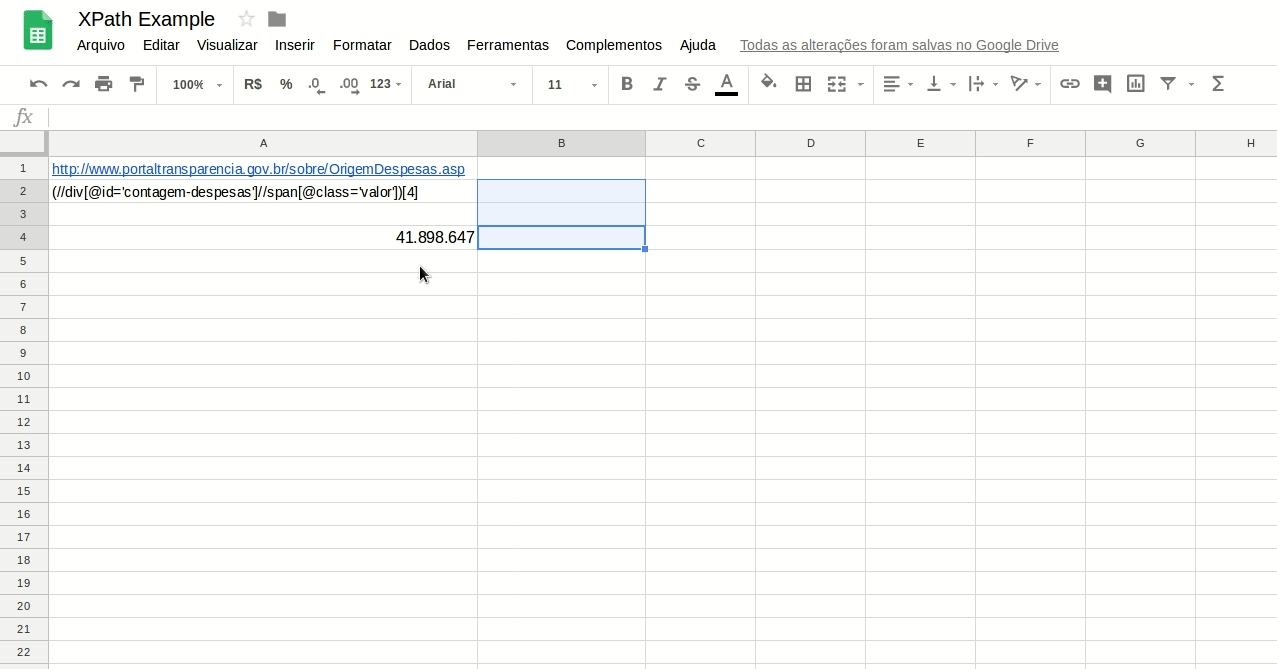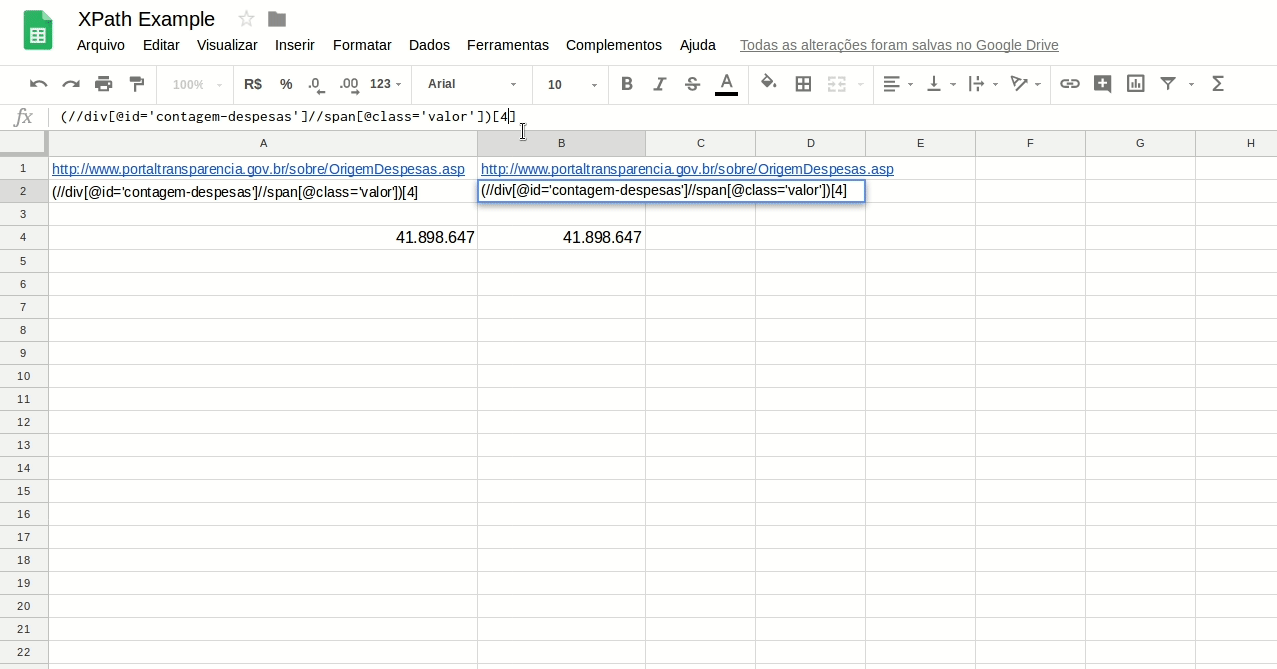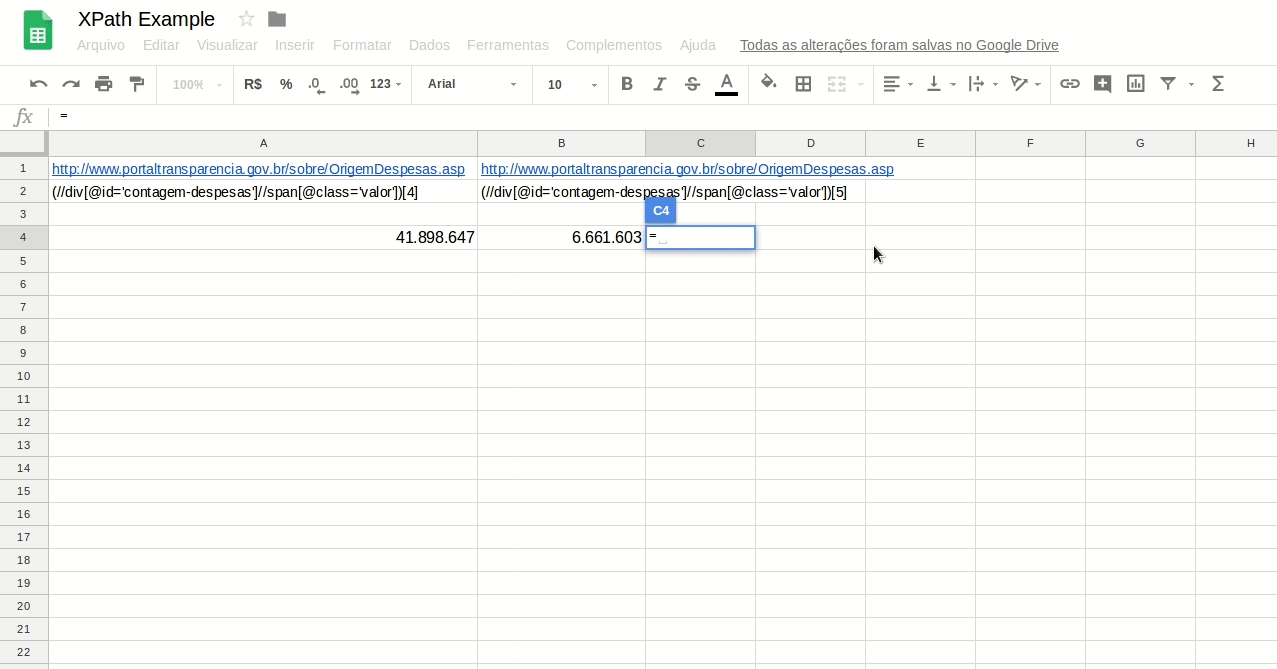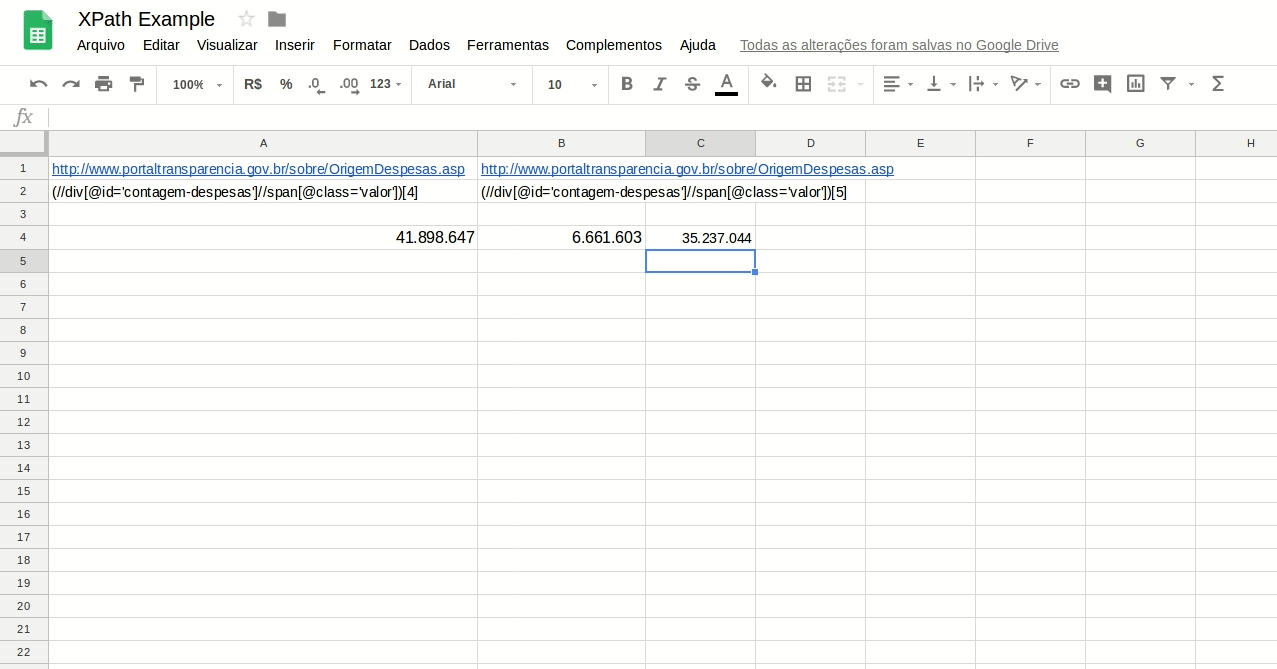
=IMPORTXML(“http://www.portaltransparencia.gov.br/sobre/OrigemDespesas.asp”;”(//div[@id=’contagem-despesas’]//span[@class=’valor’])[4]”)
IMPORTANTE: Lembre-se de trocar as aspas duplas do endereço XPath por aspas simples se for testar a expressão no Google Spreadsheet. Também não se esqueça que XPath é case sensitive, ou seja, faz diferença se os caracteres foram inseridos como maiúsculos ou minúsculos.
Você também poderia escrever a mesma fórmula colocando a URL e o XPath em células a parte, neste caso apenas retire as aspas e não esqueça de referenciar as células:
=IMPORTXML(A1;B1)
Esta fórmula irá buscar a URL no conteúdo da célula A1 e o XPath na B1. Isto é ótimo quando você precisa aplicar a mesma regra a URLs diferentes.
E, pronto, você já tem o dado que precisa. E para buscar outros valores você não precisa reescrever a fórmula, é tão simples quanto arrastar o mouse. No caso, nosso interesse é o valor seguinte, como já vimos, por isto só vamos alterar o valor 4 para 5 na nossa expressão XPath.
Então, para enfim saber quantas pessoas são favorecidas com programas sociais do Governo Federal, basta eu subtrair o primeiro campo (Total, incluindo programas) pelo segundo (Sem considerar os programas sociais).
Também é possível fazer tudo isso em uma só fórmula, caso você não precise exibir os valores totais separadamente. Para isto, bastaria encapsular cada consulta entre parênteses e subtrair uma pela outra.
Faça o teste com a expressão abaixo. Ela te retorna os número total de beneficiários de programas sociais do Governo Federal, segundo a estrutura do site atual:
=(IMPORTXML(“http://www.portaltransparencia.gov.br/sobre/OrigemDespesas.asp”;”(//div[@id=’contagem-despesas’]//span[@class=’valor’])[4]”))-(IMPORTXML(“http://www.portaltransparencia.gov.br/sobre/OrigemDespesas.asp”;”(//div[@id=’contagem-despesas’]//span[@class=’valor’])[5]”))
Expressões comuns em XPath
O XPath usa expressões que indicam um caminho necessário para chegar em algum marcador, como uma tag HTML, ou grupo de marcadores num documento. Assim, como em uma expressão regular, cada caractere e cada letra possui um sentido. Vamos dar uma olhada nas expressões mais comuns:
| Expressão | Descrição |
| table | Seleciona todas as tags com o nome “table” |
| / | Seleciona a tag raiz |
| // | Seleciona a partir da tag especificada antes da dupla-barra, independente de onde estejam
(se não houver nenhuma tag anterior a esta expressão, seleciona todos do documento independente de onde eles estejam) |
| . | Seleciona a tag atual |
| .. | Seleciona a tag-mãe da tag atual |
| @ | Seleciona atributos |
Na tabela abaixo estão listadas expressões de caminho e o resultado das expressões:
| Expressão de caminho | Resultado |
| div | Seleciona todas as tags de nome “div” |
| /div | Seleciona o primeiro elemento div, o que está na raiz
Atenção: Se uma expressão começar com uma barra (/) ela sempre representa o caminho absoluto para o elemento! |
| div/span | Seleciona todos os elementos span que são filhos da tag div |
| //span | Seleciona todos os elementos span independentemente da localização no documento |
| div//span | Seleciona todos os elementos span que são descendentes do elemento div, independentemente de onde estejam localizados abaixo do div |
| //@nome | Seleciona todos os atributos chamados “nome” |
Predicados
Predicados são usados para encontrar marcadores específicos ou um marcador que tem um valor específico. Os predicados sempre apresentam colchetes.
Na tabela abaixo estão listadas algumas expressões de caminho que são predicadas e o resultado das expressões:
| Expressão de caminho | Resultado |
| /div/span[1] | Seleciona o primeiro elemento span que é filho da tag div |
| /div/span[last()] | Seleciona o último elemento span que é filho da tag div |
| /div/span[last()-1] | Seleciona o penúltimo elemento span que é filho da tag div |
| /div/span[position()<3] | Seleciona os primeiros dois elementos span que são filhos da tag div |
| //a[@class] | Seleciona todas as tags a que po ssuem um atributo chamado “class” |
| //a[@class=’nome’] | Seleciona todas as tags a que possuem um atributo “class” de valor “nome” |
| /div/span[b>35.00] | Seleciona todas as tags span do elemento div que possuem um elemento b de valor acima de 35.00 |
| /div/span[b>35.00]/class | Seleciona todos os elementos class das tags span que estão no elemento div que possuem um elemento b com valor acima de 35.00 |
Selecionando tags desconhecidas
Coringas XPath podem ser usados para selecionar marcadores HTML desconhecidos.
| Coringa | Descrição |
| * | Retorna qualquer marcador |
| @* | Retorna qualquer atributo |
| node() | Retorna qualquer elemento de qualquer tipo |
Na tabela abaixo estão listadas expressões de caminho e seus resultados:
| Expressão de caminho | Resultado |
| /div/* | Seleciona todos os elementos filhos da tag div |
| //* | Seleciona todas as tags do documento |
| //class[@*] | Seleciona todos os elementos class que possuem pelo menos um atributo de qualquer tipo |
Selecionando vários caminhos
Ao usar o operador | numa expressão XPath você pode selecionar vários caminhos. Na tabela abaixo estão listadas algumas expressões e seus resultados:
| Expressão Path | Resultado |
| //span/class | //span/b | Seleciona todos os elementos class e b de todas as tags span |
| //class | //b | Seleciona todos os elementos class e b do documento |
| /div/span/class | //b | Seleciona todos os elementos class da tag span que são filhos do elemento div e todos os elementos b do documento |









Achei super interessante. Gostaria de saber se poderia buscar arquivos em uma determinada pasta, estes arquivos estariam em pdf e seu nome o cpf da pessoal, como eu poderia fazer digitar o numero do cpf e a pessoal teria acesso a download ou visualização deste arquivo.
Poderia me ajudar?
funciona para raspagem de midia/video? estou com dificuldades na execução
Como repassar os dados capturados para html em formato de texto com javascript?
Olá, Marcos. Pedimos que utilize nosso fórum para tentar achar uma solução para esta dúvida: https://forum.jornalismodedados.org.