
Tutorial baseado no texto “How to See What’s Behind a Website!” da Tactical Tech.
Traduzido e adaptado por Pedro Henrique, em junho de 2023.
Na internet, os sites são projetados para trazer informações ao público. No entanto, existem muitas informações por trás deles que estão ocultas, mas acessíveis através do navegador. Às vezes, essas informações “ocultas” podem ajudar a identificar indivíduos ou empresas que possuem um domínio ou mantém um site, determinar onde esse site foi registrado ou para recuperar conteúdos que foram removidos.
| Domínio – um nome que é comumente usado para acessar um site (escoladedados.org, por exemplo). Os domínios são traduzidos para endereços IP. |
Encontrar conteúdo “ocultos” não é uma ciência exata, mas uma combinação de habilidades adquiridas, um conjunto de ferramentas e uma dose de perseverança. Exploraremos algumas ferramentas e métodos úteis, que podem ajudar um a descobrir pistas enterradas dentro de um site – a partir de detalhes de registro, metadados² do código fonte³ e configurações do servidor.
| Metadados – partes de uma informação. Por exemplo: o conteúdo de um arquivo de som é a gravação, mas a duração da gravação é propriedade do arquivo que pode ser descrito como metadados. Configuração do servidor – uma combinação de configurações que determinam o comportamento do servidor. |
Um site e seus elementos
Para investigar um site de maneira eficaz, você precisará entender o que se passa em um. Isso inclui elementos aparentes para visitantes e a estrutura que permite que ele exista.
Site e página
Um site é composto de páginas da web que exibem informações. Estas informações podem incluir o perfil de uma empresa, uma lista de post em uma rede social, uma descrição de um produto, uma coleção de fotografias, um banco de dados, etc.
| Banco de Dados – um sistema usado para armazenar e organizar coleções de dados com um foco ou propósito específico. Por exemplo, um banco de dados de alunos em uma escola. |
Essas páginas da web geralmente podem ser visualizadas por qualquer pessoa que tenha acesso à Internet e um navegador. Olhando por outro ângulo, no entanto, uma página da web é apenas um arquivo digital armazenado em um disco, em um computador conectado na rede, em algum lugar do mundo. Às vezes é útil ter isso em mente.
Endereço IP
Para visitar um site, seu dispositivo precisa saber o endereço do Protocolo da Internet ou endereço IP, do computador que o hospeda. Hospedar um site significa disponibilizá-lo ao mundo. Os computadores responsáveis por isso são chamados de servidores.
| Endereço do protocolo da Internet (IP) – um conjunto de números usados para identificar um local do computador no qual você está se conectando. Exemplo: 213.108.108.217 |
Um endereço IP é normalmente escrito como uma série de quatro números, separados por pontos, onde os números em cada grupo variam de 0 a 255. Por exemplo: 172.217.16.174 é o endereço IP de um dos servidores que hospeda o buscador “google.com ”. Experimente colocar apenas estes números no navegador, teclar enter e ver o que acontece.
Todo dispositivo conectado à internet – seja uma servidor web, um serviço de email ou um roteador WiFi doméstico – é identificado por um endereço IP específico. Isso permite que outros dispositivos o encontrem, solicitem acesso ao que está hospedando e, em alguns casos, enviem conteúdo como termos de pesquisa, senhas ou mensagens de email.
| Servidor Web – também conhecido como servidor de internet, é um sistema que hospeda sites e entrega seu conteúdo e serviços aos usuários finais através da internet. Inclui máquinas de servidor físico que armazenam informações e software que facilita o acesso dos usuários ao conteúdo. |
Domínio
Como a maioria dos números longos, é difícil lembrar os endereços IP, por isso tendem a usar um domínio. Cada domínio aponta para um ou mais endereços IP. No exemplo acima, o domínio “ google.com ” aponta para 172.217.16.174 e é muito mais fácil para a maioria das pessoas lembrarem.
Registrador de domínio, registrantes de domínio e registro de domínio
Os domínios são únicos e precisam ser comprados. Só pode haver um “google.com”, por exemplo. Esta compra garante que os nomes de domínio permaneçam únicos e o torne mais difícil para pessoas personificar o site sem autorização. Quando alguém registra um domínio, um registro é gerado sobre o proprietário/administrador oficial desse domínio (ou seus representantes).
O proprietário do domínio- ou alguém a quem ele autorizou – pode apontar seu domínio para um endereço IP específico. Se um servidor estiver configurado com este endereço IP, nasce um site. As empresas que registram os domínios, como registro.br, GoDaddy, entre outras, no ato da venda de domínio precisam ter algumas informações sobre cada um de seus clientes.

Hospedagem na Web
Até aqui já sabemos que um site tem um domínio e este domínio é traduzido para um endereço IP. Também sabemos que todo site é realmente armazenado em um computador em algum do mundo físico. Este computador que hospeda o site é chamado de servidor. Existem diversas empresas de hospedagem na web. Elas possuem desde edifícios cheios de computadores a enormes espaços refrigerados chamados de data centers.
Ferramentas para investigações em sites
Agora que já sabemos o básico sobre a estrutura de um site, vamos conhecer algumas ferramentas que podem nos ajudar quando precisar investigá-los.
Pesquisa básica do WHOIS
Ao pesquisar em um site, uma das fontes de dados mais úteis pode ser encontrada nos detalhes de registro de domínio.
Ao longo de sua investigação, pode ser relevante saber quem – seja uma organização ou um indivíduo – possui um determinado domínio, quando foi registrado e por qual registrador, além de outras informações. Em muitos casos, esses dados podem ser acessados por meio de serviços de terceiros detalhados abaixo.
No entanto, como mencionado anteriormente, às vezes o proprietário de um domínio não gostaria de aparecer como vinculado ao site. Seja qual for o motivo – ora para não querer ser associado ao conteúdo do site, ora apenas para manter um certo grau de privacidade – vale a pena notar que os domínios podem ser registrados por meio de procuradores ou organizações intermediárias que ocultam todos os detalhes do registro.
As informações coletadas dos registrantes de domínio são chamadas de WHOIS data (dados WHOIS, em tradução livre) e incluem detalhes de contato da equipe técnica designada para gerenciar o site, bem como detalhes de contato do proprietário real do site ou seu procurador legal.
Esses dados são disponibilizados ao público em sites como o ICANN’s WHOIS Lookup. No entanto, atualmente existem outros serviços gratuitos ou parcialmente gratuitos (alguns têm taxas para pesquisas avançadas e resultados estendidos) que também agregam informações WHOIS e que geralmente fornecem mais detalhes do que a ICANN.
Se você estiver fazendo muitas solicitações de informações em um curto período de tempo, na maioria desses sites, poderá receber uma mensagem de erro e precisará aguardar ou mudar para um serviço diferente para continuar suas pesquisas. Da mesma forma, muitos desses sites exigem que você conclua CAPTCHAs (selecionando vários itens das imagens) para garantir que você não seja um robô.
Estes são alguns dos sites que fornecem dados WHOIS úteis gratuitamente:
- https://registro.br/tecnologia/ferramentas/whois/ – para sites nacionais
- https://iana.org/whois – funciona via navegador Tor e não possui CAPTCHA
- https://who.is – funciona via navegador Tor e não possui CAPTCHA
- https://www.whois.com/whois/ – funciona via navegador Tor e possui CAPTCHA
- https://godaddy.com/whois – funciona via navegador Tor e possui CAPTCHA
- https://whois.domaintools.com (pesquisa gratuita limitada) – funciona via navegador Tor e não possui CAPTCHA
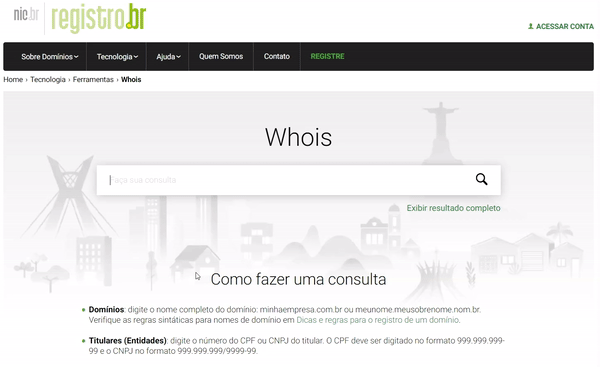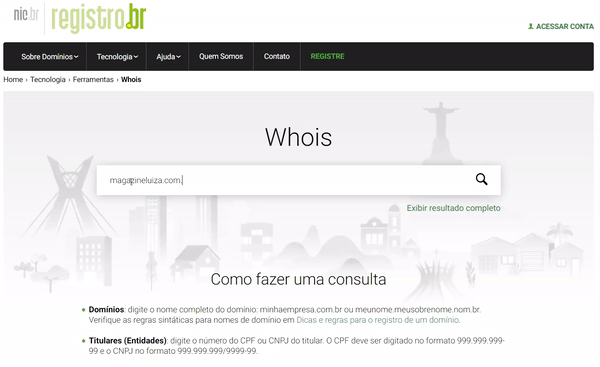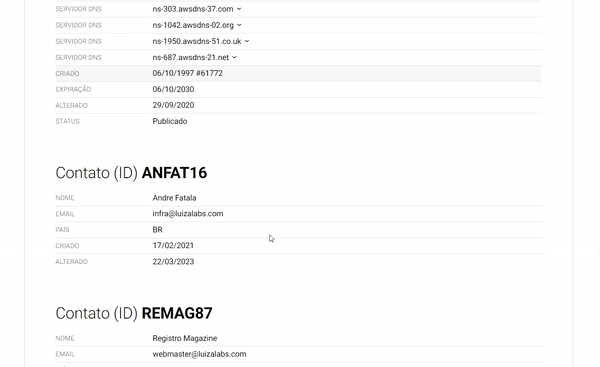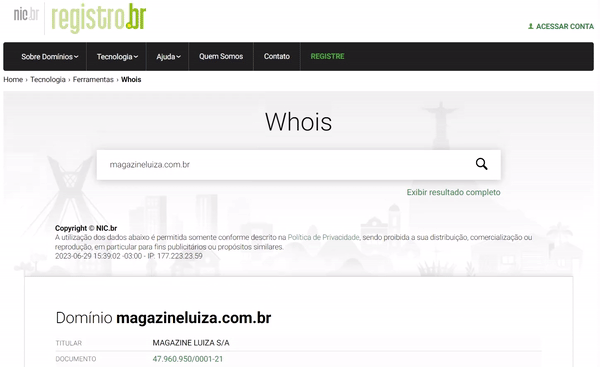
Conforme mencionado acima, muitos registradores oferecem a capacidade de atuar como contatos proxy nos formulários de registro de domínio, um serviço conhecido como “privacidade WHOIS”. Nesses casos, os domínios registrados com privacidade WHOIS não listarão os nomes reais, números de telefone, endereços postais e de e-mail do verdadeiro registrante e proprietário do site, mas sim os detalhes do serviço de proxy. Embora isso possa frustrar algumas consultas WHOIS, a ferramenta de pesquisa ainda é um recurso poderoso para investigar um domínio.
Como diferentes mecanismos de pesquisa retornam resultados diferentes para a mesma consulta, dependendo de seus índices e algoritmos, pode ser que a pesquisa com diferentes serviços de consulta WHOIS retorne vários detalhes sobre seu domínio de interesse. Verificar com várias fontes sempre que possível é, portanto, uma boa maneira de garantir a coleta do máximo de informações possível, como é de praxe em qualquer parte de uma investigação.
Implicações do GDPR
O Regulamento Geral de Proteção de Dados (GDPR, no original, ou RGPD, em tradução livre) da União Europeia (UE) gerou muita incerteza quanto ao status dos registros públicos de WHOIS na UE porque, em teoria, os dados WHOIS de proprietários e administradores de domínios registrados na UE não deveriam ser coletados e publicados pelos registradores. Sob o GDPR, é considerada informação privada.
No entanto, a ICANN processou vários registradores europeus por se desviarem de sua interpretação do GDPR, que tem uma abordagem mais flexível do regulamento e permite acesso limitado aos dados WHOIS. Mesmo após a implementação do GDPR, a ICANN continuou a exigir que os registradores da UE pelo menos coletassem dados sobre proprietários e administradores de sites, se não os tornassem disponíveis ao público. A interpretação da ICANN foi repetidamente rejeitada pelos tribunais, mas a insistência de que sua política para registrantes da UE é compatível com o GDPR deixa muitas perguntas sem resposta. Muito provavelmente, a coleta e o acesso aos dados WHOIS para registrantes baseados na UE serão restritos.
Mesmo nessas condições, alguns pesquisadores estão encontrando maneiras de contornar as restrições que às vezes tornam os dados de alguns registrantes inacessíveis. Esta postagem da GigaLaw – um escritório de advocacia americano especializado em disputas de nomes de domínio – fornece algumas dicas e técnicas que podem ser bem-sucedidas às vezes.
Histórico WHOIS
Os dados históricos podem ser uma ferramenta útil ao investigar sites, pois podem rastrear a transferência da propriedade de um domínio. Ele também pode ajudar a identificar proprietários de sites que não optaram consistentemente por ocultar seus dados de registro usando um serviço de privacidade WHOIS.
| Um exemplo em que esses dados históricos se mostraram úteis foi a investigação de uma gangue de crimes cibernéticos conhecida como Carbanak, que supostamente roubou mais de um bilhão de dólares de bancos. Usando os dados históricos fornecidos pelo DomainTools, um pesquisador conseguiu vincular vários sites, analisando seus registros históricos e encontrando centenas de domínios que foram inicialmente registrados com o mesmo número de telefone e endereço de e-mail do Yahoo. Esses detalhes de contato foram posteriormente usados para estabelecer uma ligação entre Carbanak e uma empresa de segurança russa. |
Para suas investigações, várias empresas oferecem acesso a registros históricos do WHOIS, embora esses registros possam ser restritos a países fora da UE devido ao GDPR, conforme mencionado acima.
DomainTools
É talvez a mais conhecida dessas empresas que oferecem hospedagem histórica e dados WHOIS. Infelizmente, esses dados não são gratuitos e o DomainTools exige que você se registre como membro para acessá-los.
Whoisology
Uma alternativa às ferramentas de domínio que também fornece dados históricos de WHOIS. Ele exige que você crie uma conta para os serviços básicos gratuitos e avançados baseados em taxas. Há um limite para o número de pesquisas básicas gratuitas por dia e esta opção fornece apenas o arquivo de dados históricos mais recente de um site (não o histórico completo). Os arquivos históricos completos exigem pagamento e existem várias taxas de anuidade dependendo do número de pesquisas e outros recursos que o serviço oferece. Whoisology não funciona através do navegador Tor e também pode usar CAPTCHAs para verificar se você é uma pessoa real em busca de informações.
| Segurança em primeiro lugar! Se você decidir criar uma conta nesses serviços, pode ser uma boa ideia criar um novo endereço de e-mail que possa ser usado apenas para essa finalidade. Dessa forma, você evita compartilhar seus dados de contato regulares e outros detalhes pessoais. |
Consulta reversa com WHOIS
Quando você pesquisa os nomes de domínio registrados em um determinado endereço de e-mail, número de telefone ou nome, isso é chamado de “pesquisa reversa com WHOIS”. Vários sites oferecem esses tipos de buscas.
Para identificar o proprietário de um domínio – especialmente quando esse proprietário tomou algumas medidas para ocultar sua identidade – você precisará localizar todas as informações sobre o site que podem ser pesquisadas. As ferramentas disponíveis para cruzar informações de um site mudarão e as informações disponíveis variarão de site para site, mas o princípio geral é constante. Ao tentar localizar o proprietário de um nome de domínio, concentre-se em localizar informações que possam ajudá-lo a “reverter” para um proprietário final. Aqui estão algumas ferramentas que você pode usar para pesquisas reversas:
Exibir informações de DNS
É gratuito e permite pesquisas por e-mail ou número de telefone. O ViewDNSinfo também fornece outras opções úteis, como pesquisa por um indivíduo ou empresa, pesquisa histórica de endereço IP (lista histórica de endereços IP em que um determinado nome de domínio foi hospedado, bem como onde esse endereço IP está geograficamente localizado) etc. Observe que o endereço IP os proprietários às vezes são marcados como ‘desconhecidos’, portanto, é útil usar vários sites para suas pesquisas e combinar os resultados para obter uma imagem mais completa. Funciona via navegador Tor e não possui CAPTCHA.
Domain Eye
Você pode se registrar no Domain Eye para obter 10 pesquisas gratuitas por dia. Funciona via navegador Tor e não possui CAPTCHA.

DomainTools
Um serviço pago sem demonstrações gratuitas disponíveis para WHOIS reverso no momento. Funciona via navegador Tor e não possui CAPTCHA.
Encontrando informações com hospedagem compartilhada e pesquisa reversa de IP
Você pode usar o endereço IP para ver quais outros sites estão hospedados no mesmo servidor. Isso é útil para identificar sites que podem estar relacionados.
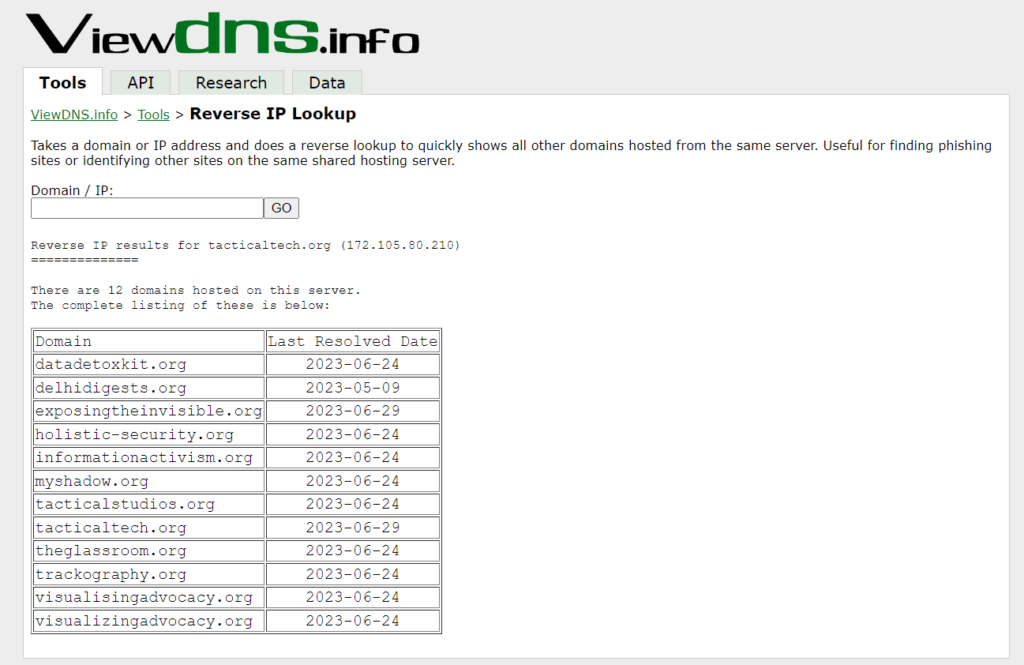
ViewDNSinfo
Você pode encontrar resultados completos procurando por um nome de domínio ou endereço IP na caixa de pesquisa de IP reverso do ViewDNSinfo.
Bing IP search
Outra maneira de listar sites que compartilham o mesmo endereço IP é adicionando o prefixo “IP:” à sua consulta de endereço IP no mecanismo de pesquisa do Bing.
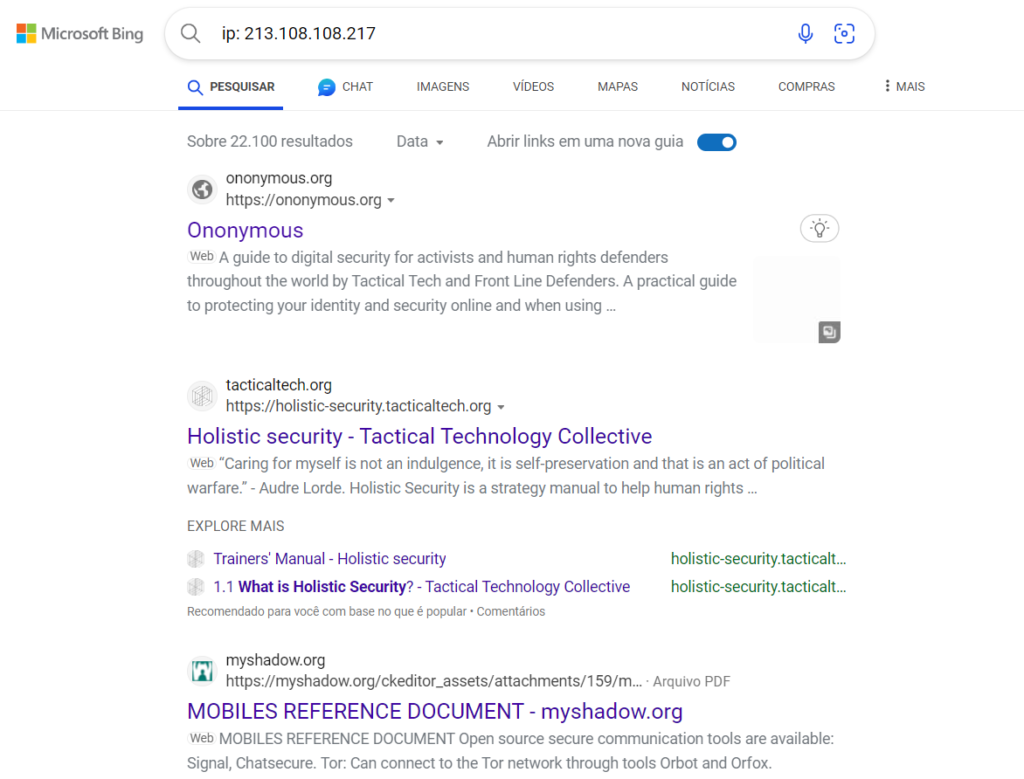
Vale ressaltar que, embora o ViewDNS forneça uma lista de domínios, pesquisar um endereço IP com o prefixo de pesquisa “IP:” no Bing também retorna endereços de páginas específicas da Web. Dados os resultados variados de qualquer coleção de fontes, você deve novamente usar vários serviços e comparar os resultados.
Descobrindo informações úteis por meio do código-fonte e o inspetor de elementos em uma página da Web
As páginas da Web geralmente são escritas em texto simples usando uma combinação de linguagens de script, como HTML (HyperText Markup Language) e JavaScript, entre outras.
Juntos, eles são chamados de código-fonte de um site, que inclui o conteúdo e um conjunto de instruções, escrito por programadores, o qual garante que o conteúdo seja exibido conforme pretendido.
O navegador processa essas instruções nos bastidores e produz a combinação de texto e imagens que você vê ao acessar um site. Com uma simples etapa extra, seu navegador permitirá que você visualize o código-fonte de qualquer página que visitar.
Geralmente, você pode clicar com o botão direito do mouse na página e selecionar “Exibir código fonte da página”. Na maioria dos navegadores Windows e Linux, você também pode pressionar as teclas “CTRL+U” no teclado de seu computador. Para obter instruções sobre o Mac e dicas adicionais, confira este guia sobre como ler o código-fonte (também acessível pelo navegador Tor).
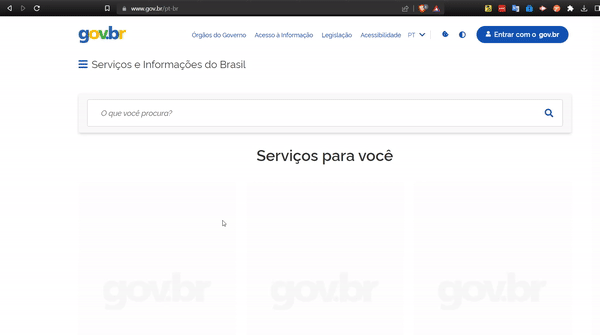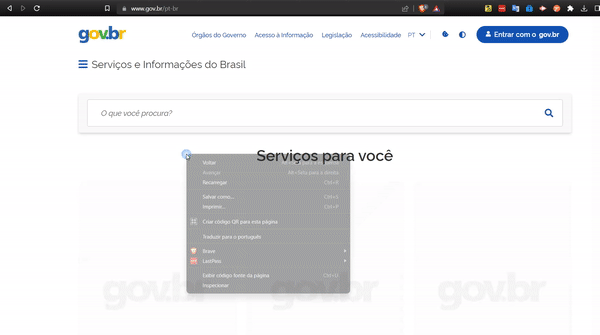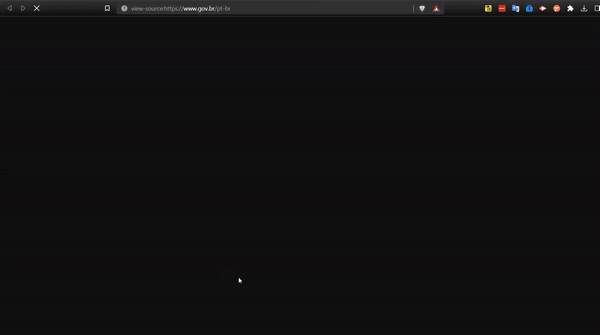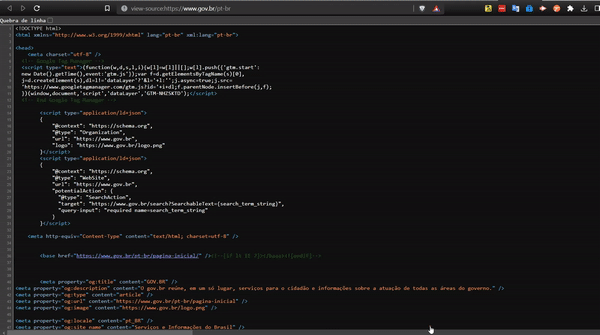
O inspetor de elementos também é uma ferramenta bem interessante e semelhante a opção de código-fonte. Utilizando o botão direito em cima da página e escolhendo “Inspecionar” ou colocando o atalho “Ctrl+Shift+I”, é possível entender como é construído cada elemento que constitui aquela página web e fazer pequenos testes de edição, com modificações simples de textos. Um caso muito famoso de investigação utilizando também esta ferramenta, foi o do jornalista Rodrigo Menegat, ao investigar o aplicativo TrateCovid e descobrir que independente das variáveis incluídas no aplicativo, sempre seria receitado cloroquina.

Encontrando conexões com o IP reverso do Google Analytics
Há inúmeras coisas que você pode descobrir no código-fonte de uma página, mas um bom exemplo é o código que ajuda os proprietários e administradores de sites a monitorar o tráfego que um site está recebendo. Um dos serviços mais populares é o Google Analytics.
Os sites relacionados geralmente compartilham um ID do Google Analytics. Como o Google Analytics permite que vários sites sejam gerenciados por uma conta de monitoramento de tráfego, você pode usar seus números de ID para identificar domínios que podem estar conectados por uma propriedade ou administrador compartilhado.
Os sites que usam o Google Analytics incorporam um número de ID em seu código-fonte. Todos os IDs do Google Analytics começam com “UA-” e são seguidos por um número de conta. Eles se parecem um pouco com isso: “UA-12345678-2”.
Como essas pesquisas podem auxiliar uma investigação?
Se o proprietário ou administrador de um site estiver ocultando sua identidade em um site, ele pode não ter tomado medidas semelhantes em todos os sites que gerencia ou possui. Enumerar esses sites por meio da pesquisa reversa dos IDs do Google Analytics pode ajudá-lo a localizar sites relacionados que podem ser mais fáceis de identificar.
| Em um artigo de 2011, o colunista da Wired, Andy Baio, revelou que, de uma amostra de 50 blogs anônimos ou pseudônimos que ele pesquisou, 15% estavam compartilhando seu ID do Google Analytics com outro site. Essa descoberta provou ser proveitosa para desmascarar sites anônimos. Da amostra de 50, Baio afirmou ter identificado sete dos blogueiros em 30 minutos de busca. |
Análise de metadados
Quando alguém cria um arquivo (como um documento, PDF ou planilha) em seu computador, os programas usados incorporam automaticamente as informações no mesmo.
Podemos considerar “dados” o conteúdo que você vê em um arquivo: as palavras em um documento, os gráficos em um PDF, os números em uma planilha ou os elementos de uma fotografia.
Por outro lado, as informações incorporadas automaticamente são chamadas de “metadados”.
Exemplos de metadados podem incluir o tamanho do arquivo, a data em que foi criado ou a data em que foi alterado ou acessado pela última vez. Os metadados também podem incluir o nome do autor do arquivo ou o nome da pessoa que possui o computador usado para criá-lo.
Existem muitos tipos de metadados. Aqui, veremos como encontrar e dar sentido a vários exemplos que são úteis para investigações.
Com documentos, mesmo que os metadados nem sempre identificam o autor ou criador de um arquivo, geralmente ainda fornecem pistas sobre sua identidade ou outros fatos significativos sobre eles ou os dispositivos e softwares que foram empregados para trabalhar nesses arquivos.
Uma situação semelhante acontece quando tiramos fotos: os arquivos de imagem que nossas câmeras produzem geralmente contêm um tipo de metadado chamado EXIF (Exchangeable image file format – formato intercambiável de arquivo de imagem, em tradução livre). Os metadados EXIF podem revelar informações relacionadas a quando e onde a foto foi tirada: hora, data, localização GPS (Global Position Satellite), etc.
Os usuários podem remover manualmente essas informações potencialmente identificáveis, e muitos aplicativos e sites limpam os metadados dos arquivos carregados para proteger seus usuários. Em alguns casos, no entanto, os metadados EXIF que permanecem na versão final de uma fotografia podem acabar revelando pistas sobre a identidade do fotógrafo, locais, datas e outras informações que podem ajudar a conectar os elos perdidos em sua investigação.
| O serial killer americano Dennis Rader foi preso depois de enviar um disquete contendo documentos de sua igreja para uma organização de notícias. Os documentos continham metadados que identificavam seu autor. Outros exemplos podem ser vistos no artigo ‘Behind the Data: Investigating metadata’. |
Pensando nisso, caso você não consiga encontrar o proprietário de um nome de domínio pelos meios e ferramentas apresentados acima, pode ser útil baixar todos os documentos de texto, planilhas, PDFs e outros arquivos hospedados pelo site. A partir daí, você pode analisar os metadados dos documentos e procurar o nome do autor ou outros detalhes de identificação. Você pode fazer isso verificando as propriedades dos documentos depois de baixá-los. Tenha em mente, no entanto, que documentos como esses às vezes contêm malware que pode colocar você e aqueles com quem você trabalha em risco. Para evitar isso, você não deve abri-los com um dispositivo que você usa para quaisquer outros fins (trabalho ou pessoal) ou que esteja conectado à internet.
| Segurança em primeiro lugar! – Abrindo arquivos baixados de fontes desconhecidas Alguns investigadores mantêm um laptop separado que usam apenas para abrir arquivos não confiáveis. Esses dispositivos costumam ser chamados de computadores “air gapped” porque, uma vez configurados, nunca são conectados à Internet. Como alternativa, você pode reiniciar o computador a partir de um pendrive que contenha o sistema operacional Tails quando precisar analisar documentos suspeitos. Mesmo que um documento contenha malware que afete o Tails, qualquer dano que ele possa causar se tornará irrelevante assim que você reiniciar o sistema operacional normal. E na próxima vez que você reiniciar no Tails, você terá um sistema limpo novamente. No entanto, o Tails é baseado no sistema operacional GNU/Linux, por isso vem com uma curva de aprendizado. Para usar qualquer uma dessas técnicas, você precisará de um pendrive ou disco rígido externo para poder transferir os arquivos em questão. Por fim, se você não estiver preocupado em se associar aos documentos ou em expor seu conteúdo ao Google (ou a qualquer pessoa com autoridade para acessar as contas do Google de outras pessoas), poderá enviá-los para o Google Drive e pesquisar metadados usando o Google Docs. Não se preocupe, o Google é muito bom em proteger seus servidores contra malware! |
Nem todos os documentos conterão metadados. Em primeiro lugar, nem sempre está incorporado, e o criador pode excluí-lo ou modificá-lo facilmente, assim como qualquer outra pessoa com a capacidade de editar o documento. Além disso, nem todos os metadados estão relacionados ao autor original. Os documentos mudam de mãos e às vezes são criados em dispositivos que pertencem a outras pessoas que não o autor.
Novamente, qualquer informação que você encontrar precisa ser verificada e corroborada por várias fontes. Apesar disso, os metadados podem fornecer pistas adicionais ou ajudar a confirmar outras evidências que você já encontrou.
Expondo o conteúdo oculto da Web
Quase todos os sites na internet escondem algo (e muitas vezes, muitas coisas) dos visitantes, intencionalmente ou não. Por exemplo, os sistemas de gerenciamento de conteúdo empregados pela maioria dos sites ocultam os arquivos internos usados para gerar postagens e manter o site. Os bancos de dados que armazenam dados para sites e aplicativos geralmente ficam ocultos do acesso público. Cookies e outros dados do lado do cliente, embora acessíveis e legíveis para um usuário experiente, são ocultados da visão do usuário comum, armazenados e processados automaticamente em segundo plano.
Existem ferramentas e técnicas simples que permitem que qualquer pessoa acesse essas informações sem fazer nada obscuro. Estes são apenas pequenos truques que permitem que você veja do que um site é feito e quais dados adicionais ele pode revelar a você. O acesso a essas informações pode ser útil ao investigar um site para determinar seus proprietários ou para identificar conexões com outros sites. Também pode ajudar a obter detalhes de contato ou mais pistas para sua pesquisa.
Robots.txt
Os sites indicam como os raspadores e os mecanismos de pesquisa devem interagir com seu conteúdo usando um arquivo chamado “robots.txt”. Esse arquivo permite que os administradores do site solicitem que os raspadores, indexadores e rastreadores limitem suas atividades de determinadas maneiras (por exemplo, alguns não desejam que informações e arquivos de seus sites sejam raspados).
Os arquivos robots.txt listam arquivos ou subdiretórios específicos – ou sites inteiros – que estão fora dos limites de “robôs”. Por exemplo, isso pode ser usado para impedir que os rastreadores da Wayback Machine arquivem todo ou parte do conteúdo de um site.
Alguns administradores podem adicionar endereços da Web confidenciais a um arquivo robots.txt na tentativa de mantê-los ocultos. Essa abordagem pode sair pela culatra, pois o arquivo em si é fácil de acessar, geralmente anexando “/robots.txt” ao nome do domínio.
Certifique-se de verificar o arquivo robots.txt dos sites que você investiga, caso eles listem arquivos ou diretórios que os administradores dos sites desejam ocultar. Se um servidor estiver configurado com segurança, os endereços da web listados podem ser bloqueados. Se estiverem acessíveis, no entanto, podem conter informações valiosas.
Cada subdomínio é gerenciado por seu próprio arquivo robots.txt. Os subdomínios têm endereços da Web que incluem pelo menos uma palavra adicional antes do nome do domínio. Por exemplo, o próprio Internet Archive tem pelo menos dois arquivos robots.txt: um para seu site principal, em https://archive.org/robots.txt, e outro para seu blog, em https://blog.archive.org/robots.txt.
Vale a pena notar que os arquivos robots.txt não se destinam a restringir o acesso por humanos usando navegadores da web. Além disso, os sites raramente impõem essas restrições; portanto, coletores de e-mail, spambots e rastreadores maliciosos geralmente os ignoram. No entanto, se você estiver copiando um site usando ferramentas automatizadas, é considerado educado cumprir todas as diretivas encontradas em um arquivo robots.txt.
Como teste, podemos acessar o arquivo robots.txt para o Payment Card Industry Security Standards Council. Este é um exemplo interessante não porque o Conselho está tentando esconder alguma coisa, mas porque seu arquivo robots.txt – pcisecuritystandards.org/robots.txt / arquivado aqui – inclui vários arquivos digitais – incluindo documentos do Word, PDFs e planilhas – nenhum deles que apareceria nos resultados de pesquisa regulares:

Para visitar uma página da Web ou baixar um documento encontrado dessa maneira, basta copiar o endereço da Web parcial no lado direito de uma restrição “Proibir:” e colá-lo na barra de endereço do navegador após o nome do domínio. Nesse caso, você pode baixar o arquivo “SAQ_C_V3.docx” que vê na imagem, por exemplo, usando o seguinte endereço da Web: https://www.pcisecuritystandards.org/SAQ_C_v3.docx.
Frequentemente, esses arquivos estarão acessíveis por meio do próprio site, portanto, isso pode ser apenas um atalho. Em alguns casos, no entanto, você pode se deparar com páginas ou arquivos que o administrador do site estava tentando ocultar.
Lembre-se: os arquivos digitais podem conter malware, portanto, tenha cuidado ao abri-los. Considere usar um visualizador de documentos on-line, a menos que esteja preocupado em compartilhar o conteúdo desses documentos com quem opera seu serviço de visualização de documentos.
Sitemap.xml
Os arquivos de sitemap são o oposto dos arquivos robots.txt. Eles são usados pelos administradores do site para informar os mecanismos de pesquisa sobre as páginas do site que estão disponíveis para rastreamento. Os sites geralmente usam arquivos de mapa do site para listar todas as partes do site que desejam ser indexadas e com que frequência desejam que os índices do mecanismo de pesquisa sejam atualizados.
Assim como os arquivos robots.txt, os sitemaps ficam na pasta ou diretório superior do site (às vezes chamado de diretório ‘raiz’).
Para sites grandes e complexos, o mapa do site geralmente contém links para outros arquivos XML (Extensible Markup Language), que às vezes são compactados ou ‘zipados’. Onde esses arquivos estão acessíveis, eles às vezes apontam para seções do site que podem ser interessantes.
Às vezes, o resultado são URLs que normalmente não aparecem nas pesquisas. Você pode explorá-los manualmente.
Para acessar os sitemaps, você precisa adicionar “/sitemap.xml” ao nome do domínio. Nem todos os sites terão um arquivo sitemap.xml acessível.
Enumeração de subdomínio
Um subdomínio é um identificador extra, geralmente adicionado antes de um nome de domínio, que representa uma subcategoria de conteúdo. Por exemplo, “google.com” é um nome de domínio, enquanto “translate.google.com” é um subdomínio.
Os sites geralmente têm subdomínios não listados que seus administradores acreditam ser privados. Esses subdomínios ocasionalmente apontam para conteúdo inacabado ou destinado a um público interno. Isso pode incluir subdomínios de desenvolvimento usados por programadores para testar novos conteúdos, páginas de eventos com links para materiais distribuídos em conferências ou páginas de login para webmail interno.
Muitos subdomínios são desinteressantes do ponto de vista investigativo, mas alguns podem revelar detalhes ocultos sobre o assunto da pesquisa que não são facilmente acessíveis por meio de pesquisas on-line básicas.
Aqui estão algumas ferramentas e técnicas que você pode usar ao pesquisar subdomínios de sites:
Um exemplo de ferramenta que pode ser utilizada para pesquisar os subdomínios de sites é o DNS Dumpster, o qual fornece dados sobre subdomínios, localizações de servidores e outras informações de domínio.
Como FindSubdomains.com, ele não verifica ativamente o site conforme você solicita essas informações, o que significa que suas pesquisas não podem ser rastreadas pelo site que você está investigando. Também funciona através do navegador Tor.
Recursos
Artigos e guias
- How to Conduct the Best ‘WHOIS’ Search, da GigaLaw. Um breve guia de técnicas de pesquisa WHOIS. Também disponível como recurso arquivado no Wayback Machine.
- How to Read Your Website Source Code and Why It’s Important, de Neil Patel. Um guia com dicas, técnicas e ferramentas úteis para verificar o código-fonte dos sites e entender as informações que eles fornecem.
Ferramentas e bancos de dados (databases)
- IntelTechniques, por Michael Bazzell. Um recurso de inteligência e forense digital de código aberto com ferramentas, guias e dicas úteis para investigar sites e pessoas online.
- ICANN Whois, da Internet Corporation for Assigned Names and Numbers. A ferramenta oficial de busca Whois da ICANN para sites registrados em todo o mundo.
- Cover Your Tracks, da Electronic Frontier Foundation. Uma ferramenta online que analisa o quão bem seu navegador e complementos protegem você contra técnicas de rastreamento online.








