#12 Nooscópios, bad data e um convite para você
*Este conteúdo integra o acervo de Boletins de Dados, nossos informativos mensais sobre as principais novidades e oportunidades relacionadas ao trabalho com dados. Para acessar as edições mais recentes reunidas na seção exclusiva e receber a próxima edição em sua caixa de entrada, junte-se ao nosso programa de membresia e apoie nosso trabalho.
MAIO/2020
Olá,
Temos muitas novidades para contar! 🙂
Além do próprio programa de membros, temos boas novas também sobre a Conferência de Jornalismo de Dados e Métodos Digitais (Coda.Br), novos cursos online que anunciaremos, entre outras ações. Vamos conversar ao vivo e olho no olho sobre a Escola de Dados?
Convidamos todas as pessoas participantes do nosso programa de membros para um novo encontro online, no dia 29 de junho às 19 horas.
Iremos compartilhar algumas novidades para este ano e queremos ouvir suas sugestões, colaborações e ideias. Então, que tal já salvar esta data na agenda para não esquecer?
Boa leitura,
AGENDA
Oportunidades e prazos para não perder de vista
• 06/06 – O scikit-learn open source sprint promovido pela Data Umbrella e PyLadiesNYC já tem data e objetivo: aumentar a participação de grupos sub representados nesta ferramenta e na comunidade Python em geral. • 09-10/06 – MongoDB Live é um evento virtual sobre este banco de dados, que acontece em junho. • 11/06 – Prazo final da consulta pública sobre reestruturação da Infraestrutura Nacional de Dados Abertos. • 15/06 – Encerramento do concurso de jornalismo de dados ‘Todos os Olhos na Amazônia’. • 15/06 – O Ministério da Justiça e Segurança Pública está contratando cientista, engenheiro e analista de governança de dados, com remuneração mensal de R$ 8,3 mil. • 30/06 – Data limite para as inscrições para a Bolsa Rosalynn Carter de Jornalismo em Saúde Mental 2020. • 12/07 – Começa a International Conference on Machine Learning. Inscrições abertas. |
NO MUNDO DOS DADOS
Notícias e discussões quentes
Um nooscópio para navegar nos dados
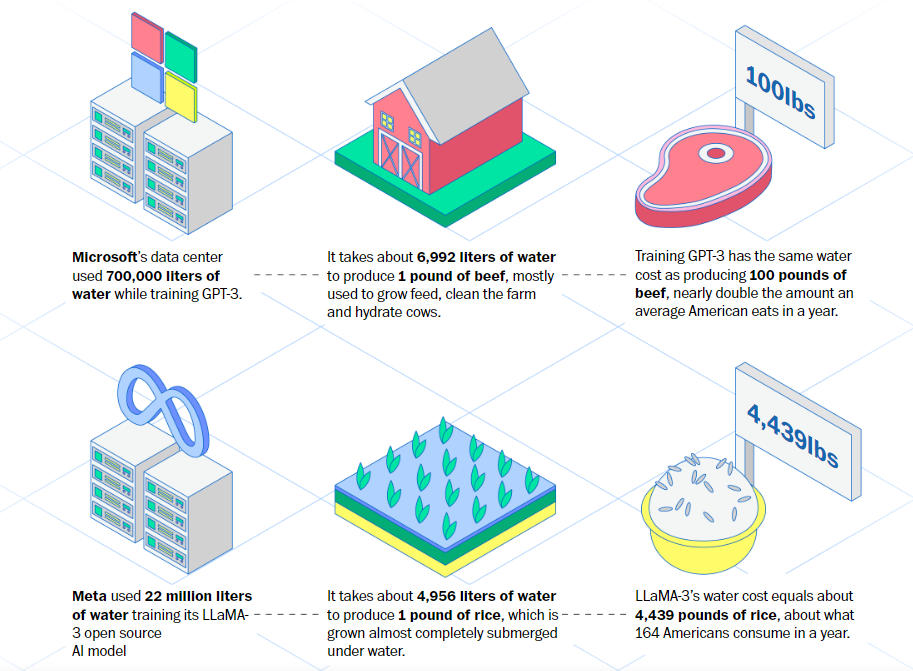
No recém-lançado ‘The Nooscope Manifesto’, Matteo Pasquinelli e Vladan Joler propõem uma redefinição conceitual para a aprendizado de máquina (machine learning – ML). Ela não seria um exemplo de “inteligência artificial”, uma racionalidade estranha àquela humana, mas sim “instrumentos de ampliação do conhecimento” para identificar características, padrões e correlações na vastidão dos dados. As técnicas de ML seriam um ‘nooscópio’, um instrumento para ver e navegar no espaço do conhecimento.
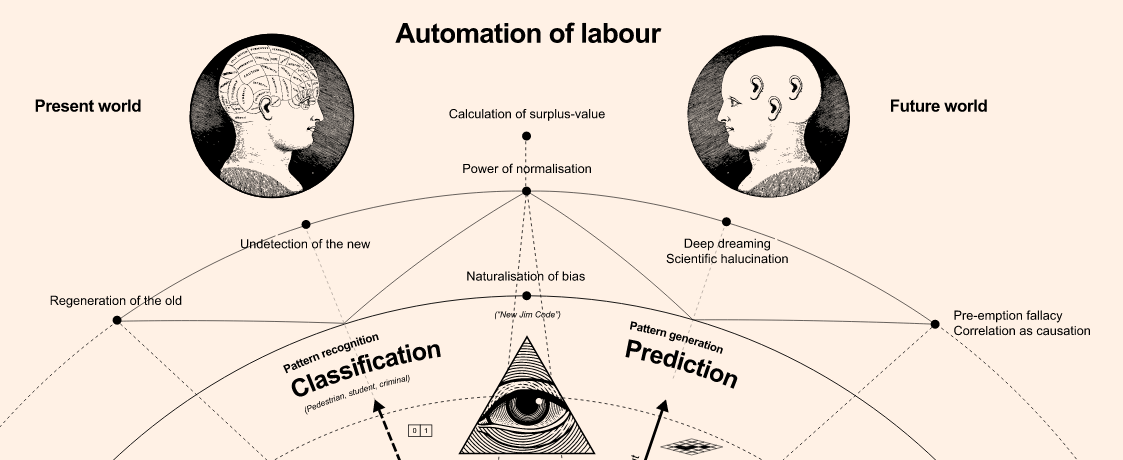
Além de um manifesto, o site nooscope.ai traz um diagrama que mostra não só como ‘machine learning’ funciona, mas também como ele falha, ilustrando erros em aprendizagem de máquina, vieses e limitações.
O manifesto e o diagrama resumem uma ótima reflexão crítica sobre este tema tão atual. Além deste ‘nooscópio’, as técnicas de ML também são definidas como um instrumento de extrativismo do conhecimento.
Pasquinelli e Joler enfatizam a ‘aprendizagem de máquina’ como uma construção social, não só técnica. No fim do dia, dizem, a automação se revela como um mito, pois o trabalho das máquinas depende de pessoas, como os terceirizados da Amazon que fazem o “trabalho invisível” de catalogação de imagens no Mechanical Turk. Leitura recomendada!

Bad data
No Brasil e no mundo, algumas bases de dados relacionadas à Covid-19 viraram notícia não por aquilo que relevam, mas por serem fonte de interpretações e informações equivocadas sobre a pandemia. Por aqui, a Folha de São Paulo destacou os problemas na base de dados de mortalidade dos cartórios brasileiros. Lá fora, a CNN fez uma reportagem sobre o Worldometer, um portal de dados desconhecido que foi catapultado à fama apresentando dados duvidosos e sem fontes confiáveis.
Outro aspecto negativo do uso de dados foi destacado em um relatório da empresa Veritas, que trabalha com armazenamento de informações. Segundo as estimativas noticiadas, mais da metade de todos os dados que empresas e organizações armazenam mundo afora são… inúteis. Isso mesmo: sequer são utilizados. Mas o impacto ambiental não é pequeno: apenas em 2020, a empresa calcula 6,4 milhões de toneladas de CO² lançadas na atmosfera para dar conta de armazenar estes dados inúteis, o equivalente às emissões de uma cidade como São Paulo durantes alguns meses.
Covid-19 para além do óbvio
Nem tudo são exemplos negativos quando o assunto é dados da Covid-19. O Infoamazonia publicou um bom trabalho mostrando as dificuldades de atendimento enfrentadas pela população indígena da Amazônia. Já o PressGazette publicou uma compilação de trabalhos internacionais de excelência em jornalismo de dados sobre o novo coronavírus. E o site Data Journalism deu dicas de como pensar em coberturas, projetos e investigações criativas sobre o tema.
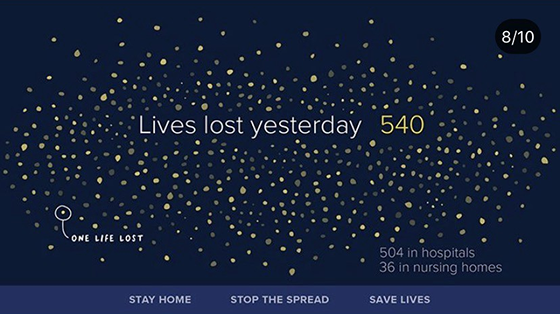
Exemplo de visualização de dados sobre mortalidade da Covid-19, feito por Giorgia Lupi e destacado no artigo de Eliza Fagundes.
Quem trabalha com obtenção e análise de dados sobre a pandemia pode conferir o site da Academic Data Science Alliance, já aquelas pessoas mais interessadas em visualização da Covid-19 têm à mão o excelente artigo de Eliza Fagundes mostrando como as designers Mona Chalabi e Giorgia Lupi visualizam dados do coronavírus humanamente, com imperfeições e de forma analógica.
Dois séculos de Nightingale
E, por falar em dados, trabalhos inspiradores e saúde pública, em maio, foi celebrado os 200 anos de Florence Nightingale (1820-1910). Ela foi pioneira na enfermagem e na visualização de dados, sendo criadora de um tipo um gráfico hoje conhecido como “diagrama de área polar”. Allen Hillery destacou três vantagens desta forma de representar dados criada por Nightingale.
SAIBA MAIS
Para aprender mais e aprender sempre
Poesia e filosofia na visualização de dados
Crédito: The Data Painter and the Data Poet
Ainda sobre visualização de dados, em maio, tivemos a publicação de vários outros conteúdos interessantes. No blog do Data Visualization Society (DVS), Alberto Cairo trouxe uma reflexão filosófica sobre o tema, enquanto Guillaume Meigniez publicou um artigo abordando o aspecto poético e artístico das visualizações. E Duncan Geere compartilhou em seu blog algumas vantagens de usar papel e caneta na hora de prototipar suas visualizações.
***
Mercado de trabalho
Já se você quer saber mais sobre o mercado de trabalho na área de visualização de dados, temos duas dicas. O podcast Visualmente convidou o pessoal da Café.art, uma referência nessa área no Brasil, para compartilhar um pouco de sua experiência e inspirações. O blog da DVS também abordou o tema neste artigo, que traz dicas para você construir sua própria carreira na área.
SNIPPETS
Dicas curtas e certeiras sobre o trabalho com dados
Celulares: o Data Visualization Society publicou um artigo sobre como contar histórias atraentes com dados em celulares. E o projeto BeeWare foi tema de matéria na ZDNet (inglês) e Olhar Digital (em português). Ele promete levar o Python para as telinhas.
***
O livro Exploratory Data Analysis with R foi atualizado e pode ser baixado gratuitamente no Learnpub.
***
O cientista da computação Diego Nogare ofertou um minicurso de introdução a machine learning e inteligência artificial em português, enquanto Julia Silge publicou estudos de caso de aprendizado de máquina supervisionado em R, usando o tidymodels.
***
A Fundación Gabo disponibilizou um ciclo de webinars sobre epidemiologia para jornalistas.
***
A Abraji mostrou o passo a passo para explorar os dados de gastos do governo com a pandemia usando Python.
***
A série de encontros do OSINTCURIOUS convidou Aliaume Leroy (BBC), que falou sobre o uso de Open Source Intelligence no jornalismo. E o Bellingcat publicou uma investigação sobre uma rede de robôs pró-governo chinês.
***
Foi publicado no site Data Journalism a terceira edição do Verification Handbook, um manual para verificação e checagem de fatos.
***
O Ministério da Saúde disponibilizou uma nova plataforma de dados abertos, o Open DataSUS.
***
A pesquisa TIC Domicílios 2019, que investiga o acesso e uso da Internet nos domicílios e pela população brasileira, foi lançada.
INSPIRA
Trabalhos e iniciativas inovadoras para te inspirar
O jogo People of the Pandemic simula os impactos de ações coletivas durante uma pandemia. Você pode jogá-lo sozinho direto do navegador ou em grupos de até 20 participantes. Os criadores Shirley Wu e Stephen Osserman explicaram em entrevista ao blog da DVS sobre as tecnologias utilizadas no projeto.
Crédito: People of Pandemic
Moradores dos Estado Unidos podem colocar um ZIP code (equivalente ao CEP) para carregar no jogo dados reais sobre sua localidade, como o números sobre a capacidade hospitalar. A simulação requer a criação de estratégias de cooperação local para atendimento das necessidades individuais, aliada à redução do número de saídas à rua.
APT UPDATE
Atualize-se com as novidades de softwares para trabalhar com dados
A revista The Economist publicou o código e os dados do seu projeto para calcular o excesso de mortalidade por conta da Covid-19.
***
O mais famoso programa de código-aberto para edição de imagens vetoriais chegou na sua versão 1.0. O Inkscape é uma alternativa aos softwares pagos na hora de finalizar a arte de um gráfico estático.
***
Já para fazer painéis interativos, vale conferir o Grafana, que também tem código-aberto e chegou na sua versão 7.0 reforçando as funcionalidades de conexão com dados externos.
***
A Plotly anunciou a criação do JupyterDash, uma nova biblioteca que deixa mais fácil criar dentro da interface do Jupyter alguns aplicativos em Dash, que é o framework da plataforma para construção de aplicações webs, sem necessidade de lidar com JavaScript.
***
E o AnyCharts lançou uma nova biblioteca de visualização de dados… em Javascript.
***
A recém-lançada versão 0.8 da interface do Github para linha de comando permite você fechar, reabrir e adicionar metadados às “issues” da plataforma.
***
Também foi anunciada a criação do Github Codespaces, um ambiente de desenvolvimento online. A iniciativa foi saudada pelo Gitpod, que já oferece este serviço.
***
Google em R: a nova versão do pacote para lidar com a API do Spreadsheets foi lançada (googlesheets4) e Janderson Toth publicou um tutorial em português sobre o gtrendsR, que lida com dados do Trends.
Ficou algo de fora? Envie sugestões e dicas para escoladedados@ok.org.br
Autoria

Escola de Dados