
A partir de exemplos reais, neste tutorial, veremos como extrair informações relevantes a partir de bases de dados públicas. Inicialmente, veremos como importar e começar a explorar as informações sobre despesas dos deputados federais no Google Spreadsheets. Depois, iremos mostrar como cruzar informações do Tribunal Superior Eleitoral com o Governo do Distrito Federal em busca de insights interessantes.
Vamos lá?
Baixando os dados
Para começar, vamos dar uma olhada nos dados sobre gastos dos deputados federais. No site da Câmara dos Deputados, você encontra estas informações sob a alcunha de ‘COTA PARA EXERCÍCIO DA ATIVIDADE PARLAMENTAR‘. As despesas deste ano estão disponibilizadas em formato XML em um arquivo compactado (“zip”).
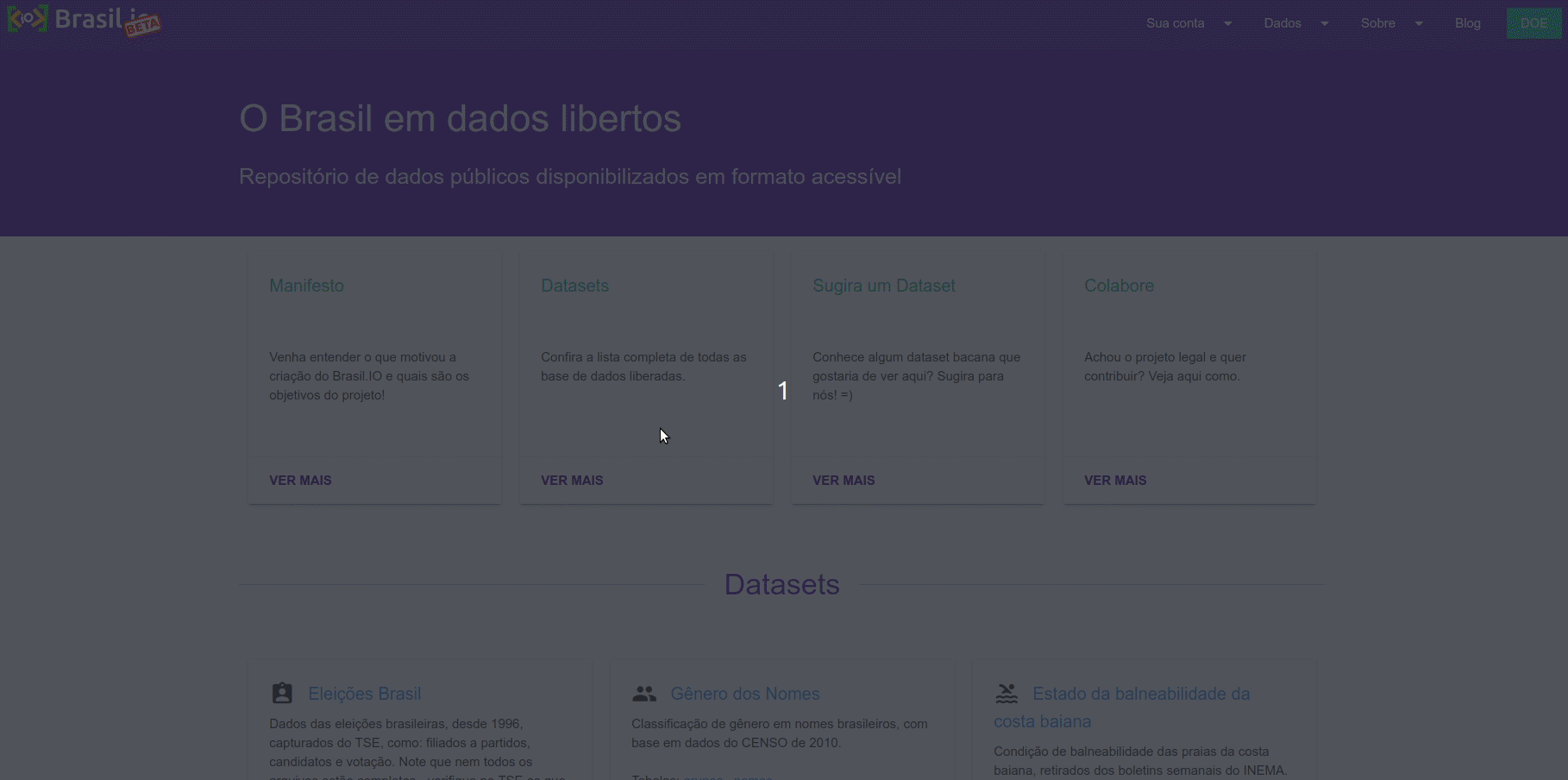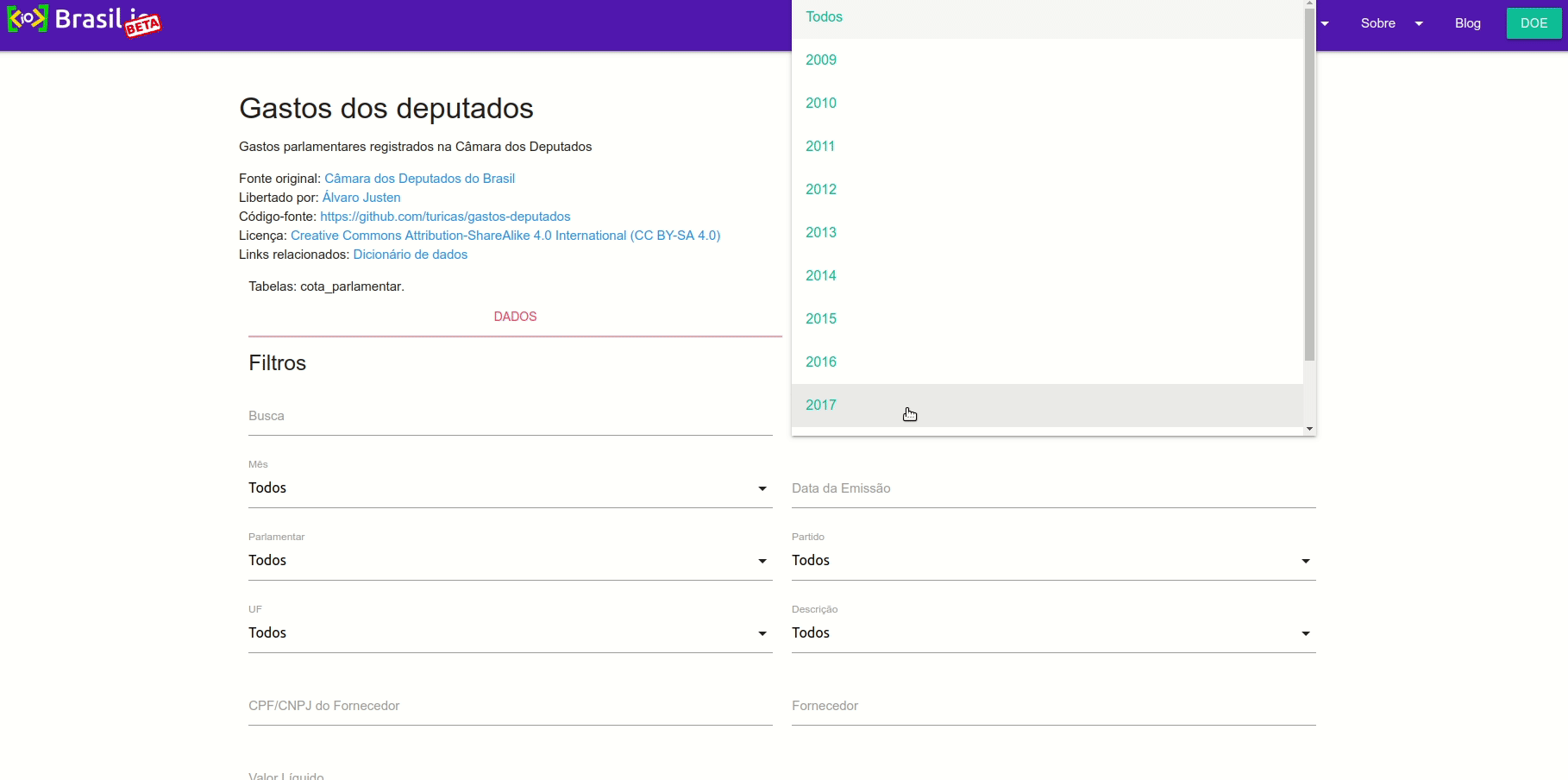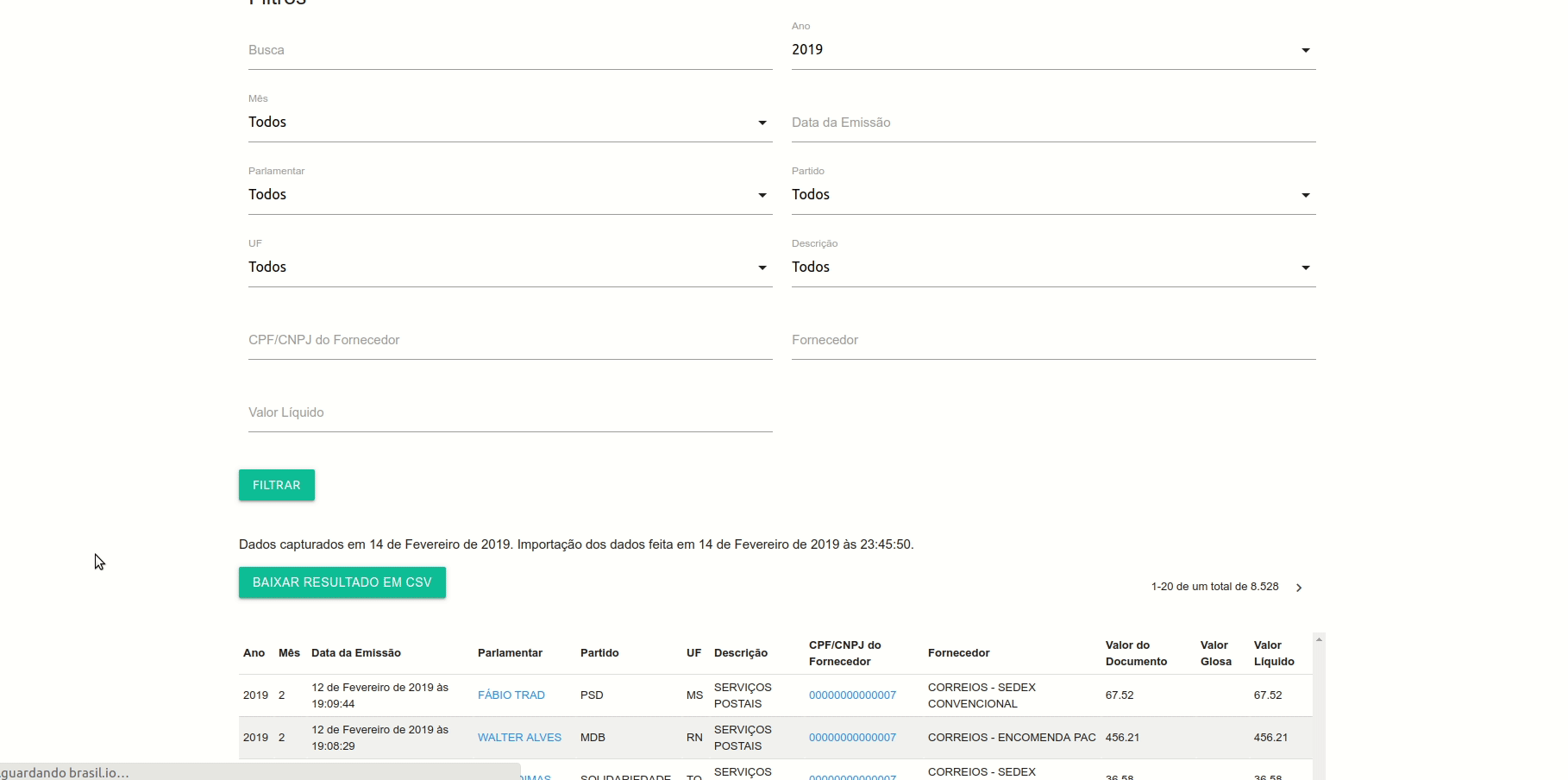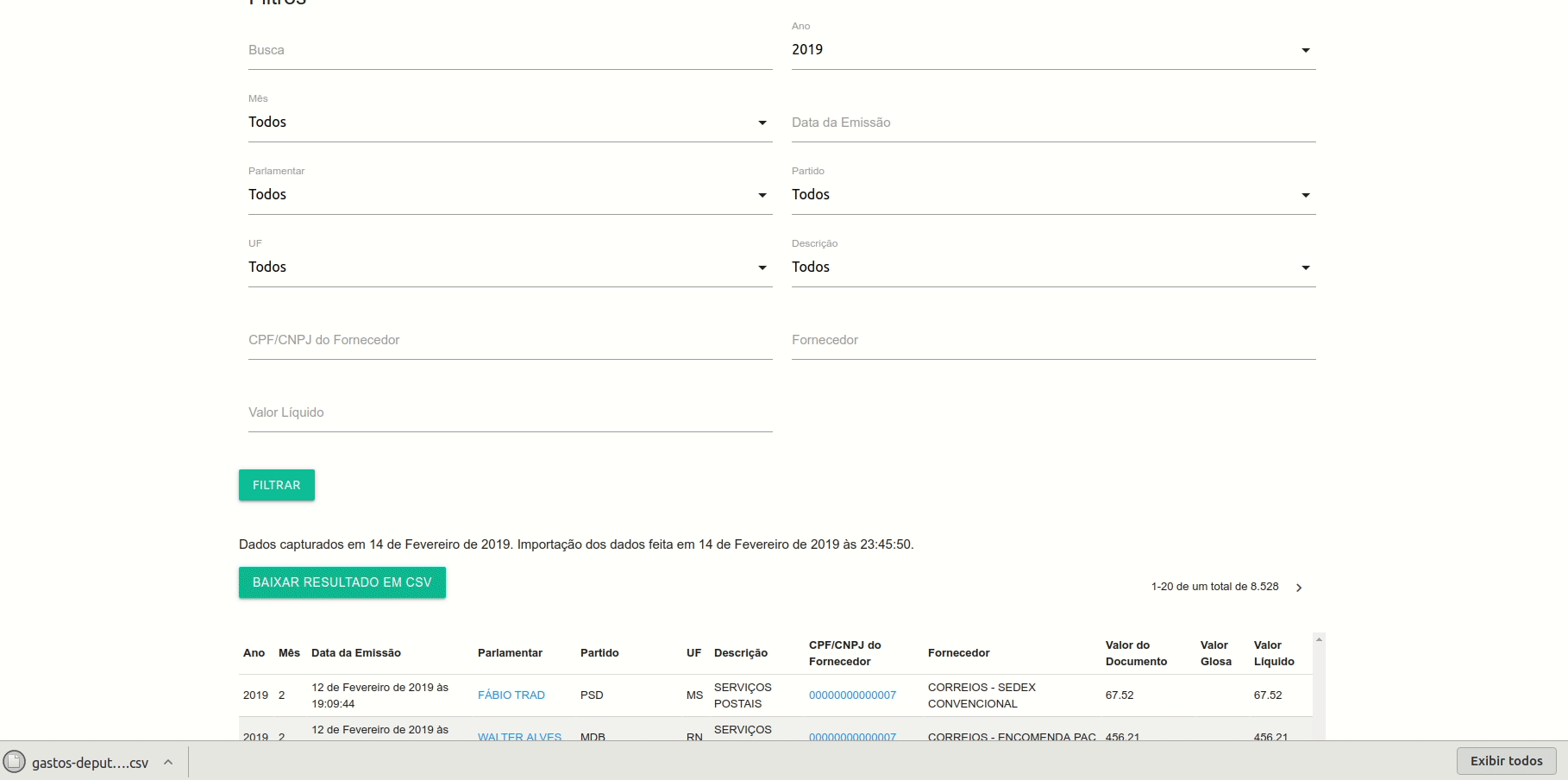
Para facilitar, vamos usar o site Brasil.io, que coletou e estruturou a série histórica de dados da Câmara. Através dele, em poucos segundos, podemos filtrar e exportar apenas os resultados de 2019 em um formato CSV, mais adequado para abrirmos com um editor de planilhas.
FAÇA-VOCÊ-MESMO
Você pode baixar o arquivo acessando a página principal do Brasil.IO e seguindo o caminho acima. Outra opção mais rápida é fazer o download diretamente via arquivo no Brasil.IO ou por meio deste link no Google Drive.
Atenção ao aviso no site. Os dados foram capturados e importados em 14 de Fevereiro de 2019, portanto, não contemplam despesas posteriores a isto, até o momento da publicação deste tutorial. Para fins de exploração neste tutorial, esta parcial já nos serve, então vamos em frente.
Importando os dados
O próximo passo é importar nossos dados para um editor de planilhas. Entre aqueles que rodam no seu próprio computador, as principais opções são o Excel, pago e de propriedade da Microsoft, e o LibreOffice, que é gratuito e tem o código-aberto.
Aqui, vamos usar uma opção online, o Google Spreadsheets, que exige uma conta no Google, mas é gratuito. De todo modo, você pode replicar os passos a seguir com algumas poucas alterações em outros programas também.
Se você já está logado no Google, basta entrar no endereço sheets.new para abrir uma nova planilha. Feito isso, vamos importar os dados que baixamos na etapa anterior.
Já com a planilha aberta, selecione “Arquivo” > “Importar” > “Upload”. Depois, encontre o arquivo no seu computador e faça seu envio para o Google Spreadsheets. Então, você verá algumas opções.
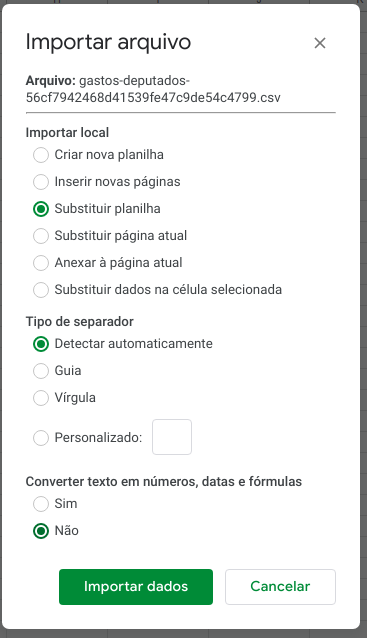
ATENÇÃO
Aqui, precisamos ter alguns cuidados. Vamos ver cada uma das opções, de baixo para cima.
Em especial, vamos selecionar a opção ‘não’ no campo ‘Converter texto em números, datas e fórmulas’. Isto vai evitar que eventuais conversões equivocadas feitas automaticamente desformatem ou suprimam informações importantes.
Outra configuração importante é o separador utilizado no arquivo CSV. No nosso exemplo, é a vírgula, então, tanto a seleção automática, como a opção “vírgula” irão funcionar bem.
Já na primeira opção “Importar local” dizemos onde queremos colocar os dados no arquivo. No nosso caso, como temos uma planilha recém-criada e vazia, vamos usar a opção ‘Substituir planilha’.
Entendendo os dados
É importante não confiar cegamente nos seus dados, seja quais forem. Por isso, também vale sempre se fazer perguntas mais gerais, tais como…
- Quem produziu e disponibilizou os dados?
- A fonte é confiável ou possui algum interesse em particular?
- Qual a metodologia utilizada para registrá-los? Houve alguma mudança nela ao longo da série histórica dos dados?
- Quando eles foram coletados? Qual o período que ele abrange?
- O que os dados significam? Qual significado das linhas e colunas?
Resumindo, seja cético ao trabalhar com dados.
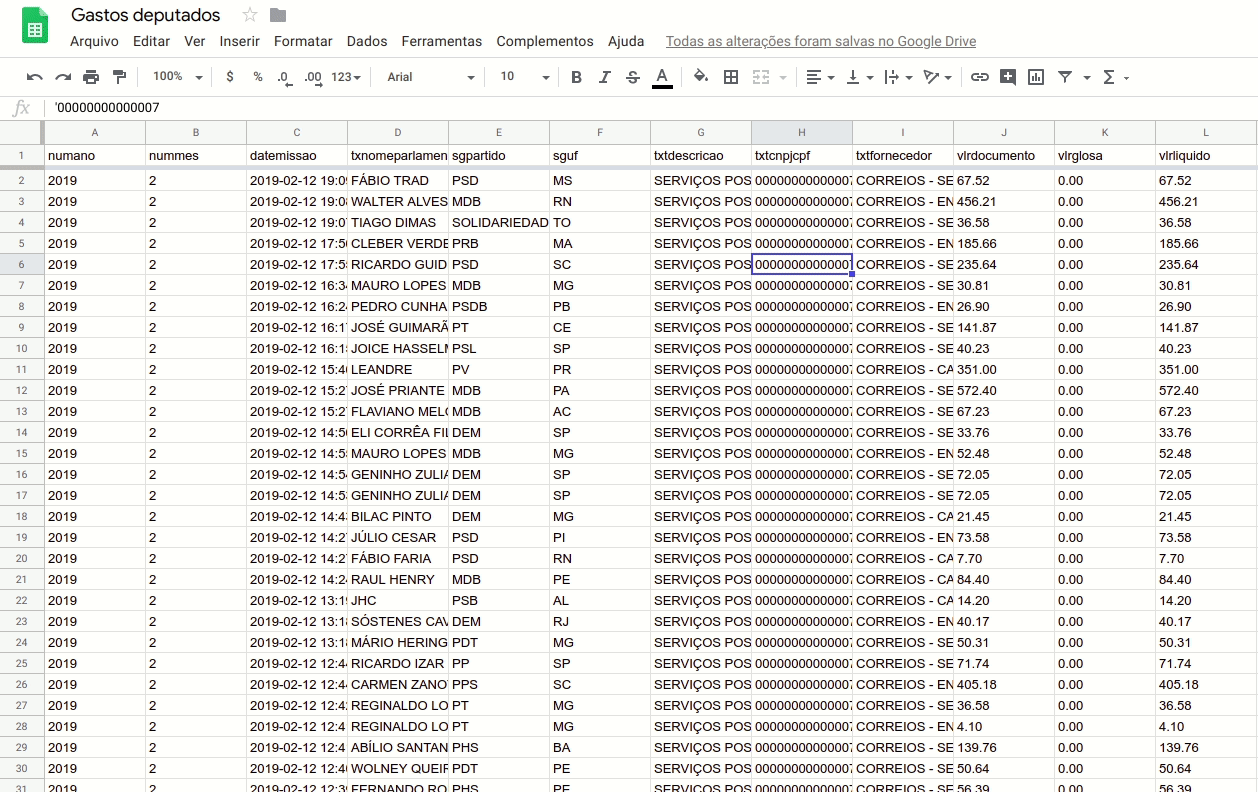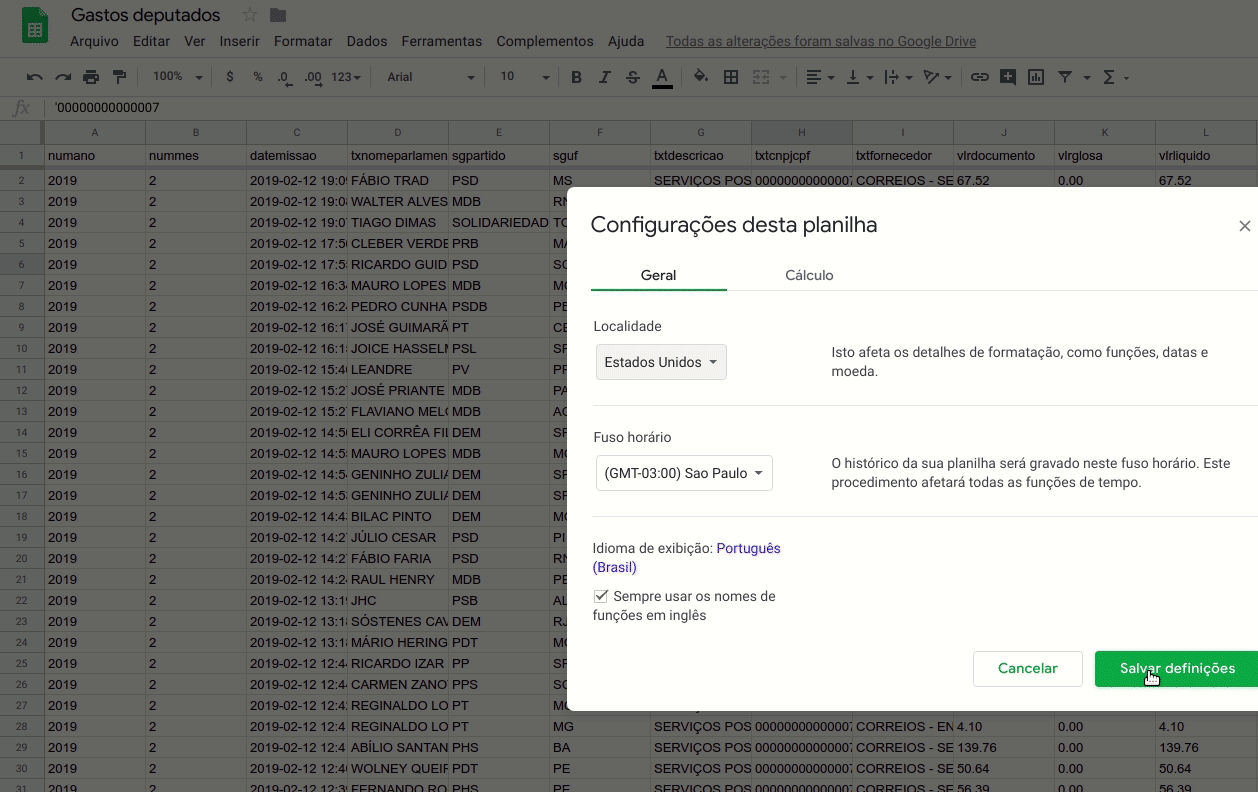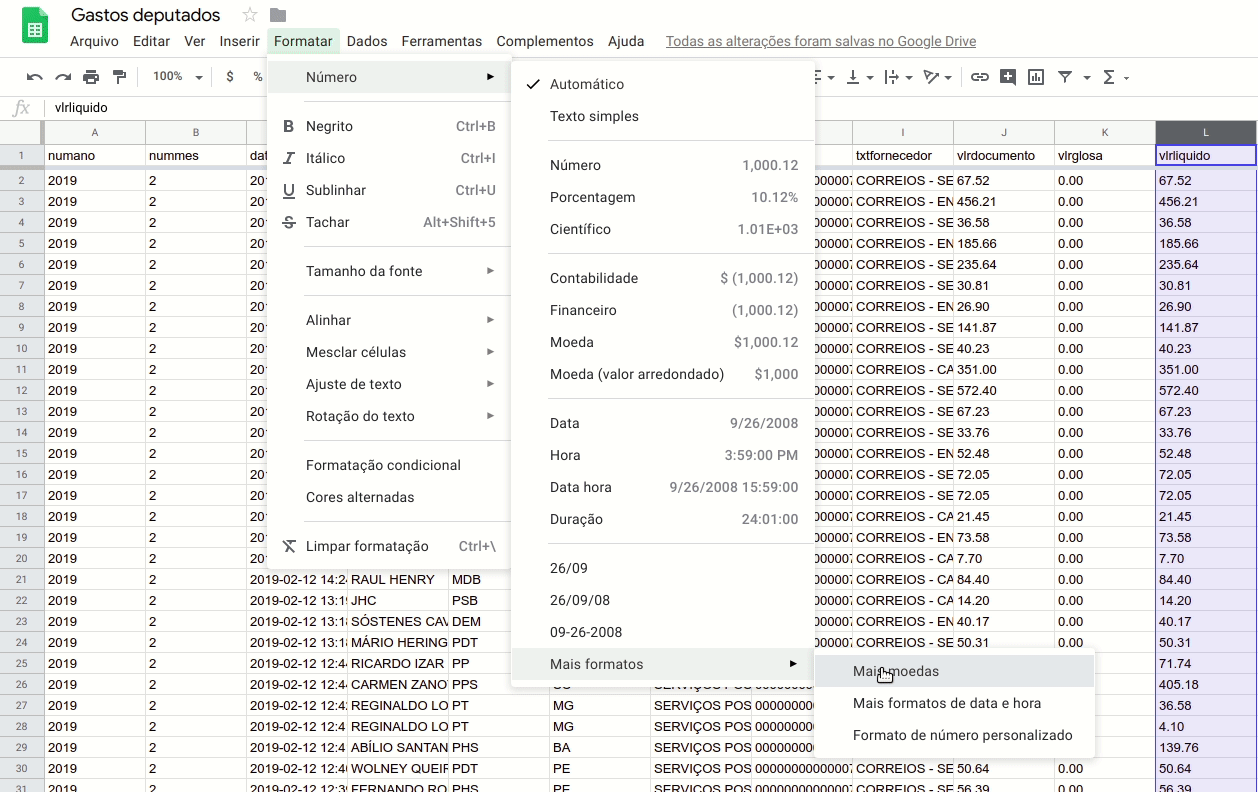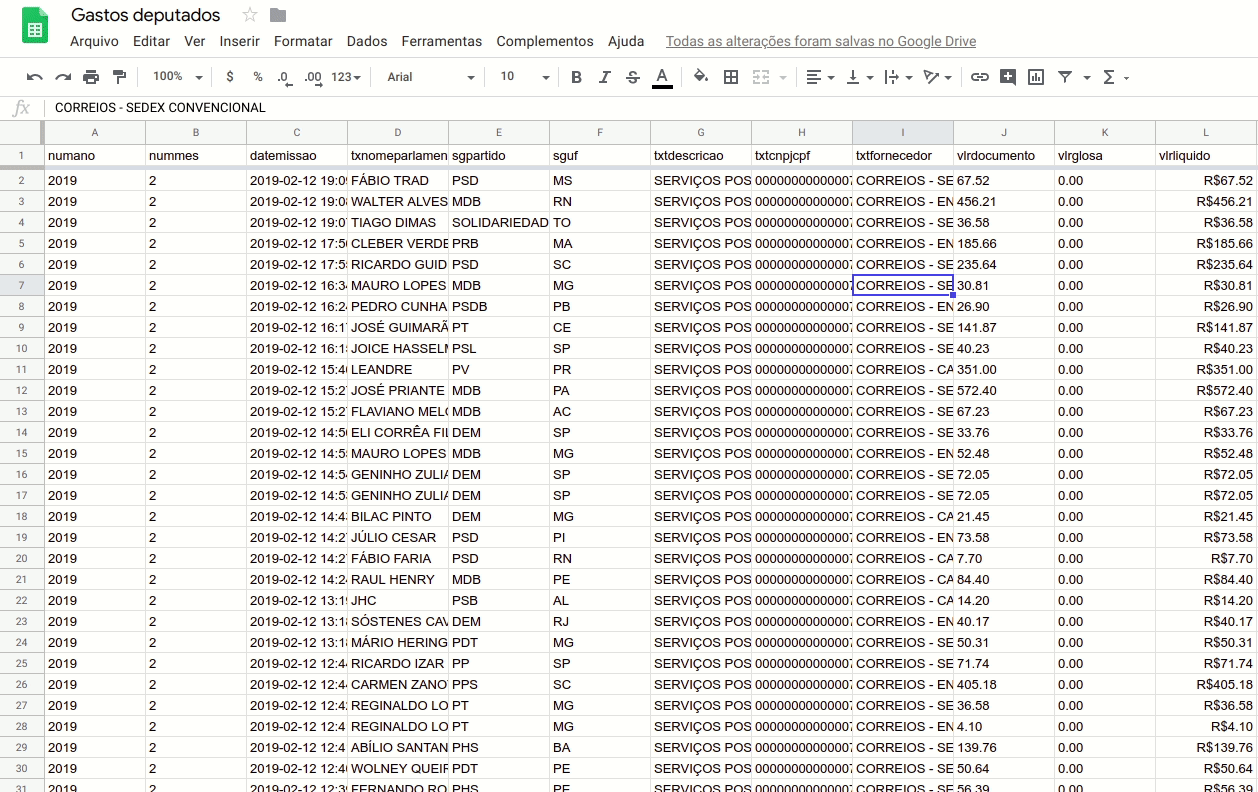
Voltando para o nosso exemplo, com os dados importados, você deve ver uma planilha como esta. Ela tem 12 colunas (variáveis) e 8.529 linhas (observações).
Sempre, em qualquer análise, precisamos começar compreendendo como estão organizados os dados que temos em mãos. Se você não sabe o que é a Cota de Exercício da Atividade Parlamentar (CEAP), vale conferir este post da Operação Serenata de Amor, que explica como estas despesas funcionam.
No nosso caso, cada despesa de cada deputado federal é registrada como uma observação. Mas e as colunas? O que significam?
Vejamos uma a uma:
- Ano (numano): ano de realização da despesa
- Mês (nummes): mês de realização da despesa
- Data (datemissao): data de emissão da despesa
- Deputado (txnomeparlamentar): parlamentar responsável pelo gasto
- Partido (sgpartido): sigla do partido do parlamentar
- UF (sguf): sigla da unidade federativa do parlamentar
- Descrição (txtdescricao): descrição da despesa
- CNPJ do fornecedor (txtcnpjcpf): sequência de caracteres do CNPJ do fornecedor
- Nome do Fornecedor (txtfornecedor): nome do fornecedor
- Valor do documento (vlrdocumento): valor do comprovante do gasto apresentado
- Valor glosado (vlrglosa): valor retido pela Câmara
- Valor líquido (vlrliquido): valor efetivamente reembolsado
Sabendo isso, podemos formular algumas perguntas que façam uso destas colunas, por exemplo:
- Qual maior valor pago pelos cofres públicos (coluna 12) em despesas dos deputados federais do partido da situação (coluna 5) em São Paulo (coluna 6)?
- Considerando todas as despesas de todos os candidatos, o quanto os valores dos documentos apresentados (coluna 10) se parecem entre si? Ou seja, como é sua distribuição?
Agora, é sua vez: com as informações acima, pense em outros exemplos possíveis de perguntas a serem respondidas.
Definindo um cabeçalho
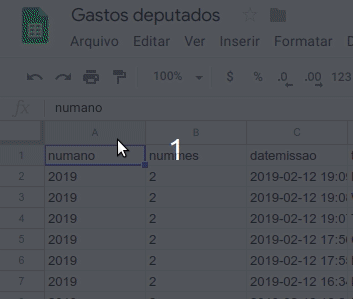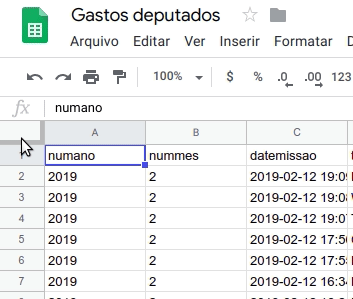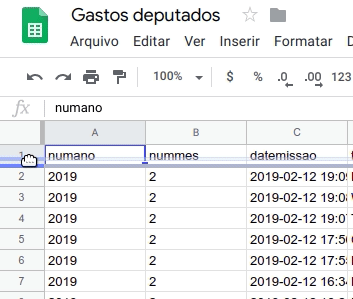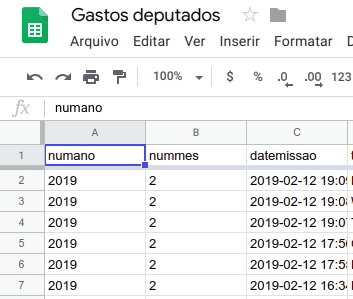
Em geral, a primeira linha das tabelas é formada pelo cabeçalho os dados, com um nome que identifica cada coluna, e os registros nas linhas inferiores são suas respectivas observações.
Configurar seu cabeçalho no Google Sheets é muito simples. Basta selecionar a primeira linha e ir no menu “Ver” > “Congelar” > “1 linha”. Ou simplesmente arrastando a barra localizada no encontro do topo da primeira linha para baixo, como nesta imagem.
Configurando os dados
Basicamente, você precisa prestar atenção em duas configurações importantes aqui. Sem elas, mesmo operações básicas como ordenar as linhas não funcionarão adequadamente.
LOCALIDADE
A forma como escrevemos números e datas variam de país para país. Por isso, o Google Spreadsheets oferece uma opção para se configurar a localidade do documento (“Arquivo” > “Configurações da planilha”).
Apesar dos parlamentares serem brasileiros, repare que as três últimas colunas do nosso arquivo de exemplo tem os valores em reais, mas usam o ponto como separador decimal, ao contrário do padrão brasileiro de usar a vírgula para tal. Por isso, vamos configurar a localidade como “Estados Unidos”.
TIPOS DE DADOS
O passo seguinte é configurar os tipos de dados. No mínimo, garanta que estejam configuradas pelo menos as colunas com números, valores e datas que serão utilizadas na sua análise ou entrevista com os dados. Basta selecionar a coluna desejada e ir no menu “Formatar” > “Número”.
Para responder às perguntas, vamos selecionar a última coluna e o tipo de dado como uma moeda em reais (“Formatar” > “Número” > “Mais formatos” > “Mais moedas”).
Entrevistando os dados
Com o terreno preparado, podemos começar a responder nossas perguntas. A primeira delas exige apenas filtrar e ordenar nossos dados. Já para a segunda vamos usar um gráfico para observar melhor os resultados.
FILTRANDO E ORDENANDO
Ou seja, para saber o maior valor pago em despesas de deputados do partido da situação (PSL) em São Paulo, eu preciso filtrar a coluna “sguf” pelo valor “SP”, a coluna “sgpartido” pelo valor “PSL” e, na sequência, ordenar os dados pela coluna “vlrliquido”.
Para habilitar os filtros, selecione o cabeçalho (a primeira coluna) e vá até o menu “Dados” > “Criar um filtro” ou use o ícone do funil, tal como na imagem abaixo. Depois, basta filtrar os valores desejados nas respectivas colunas.
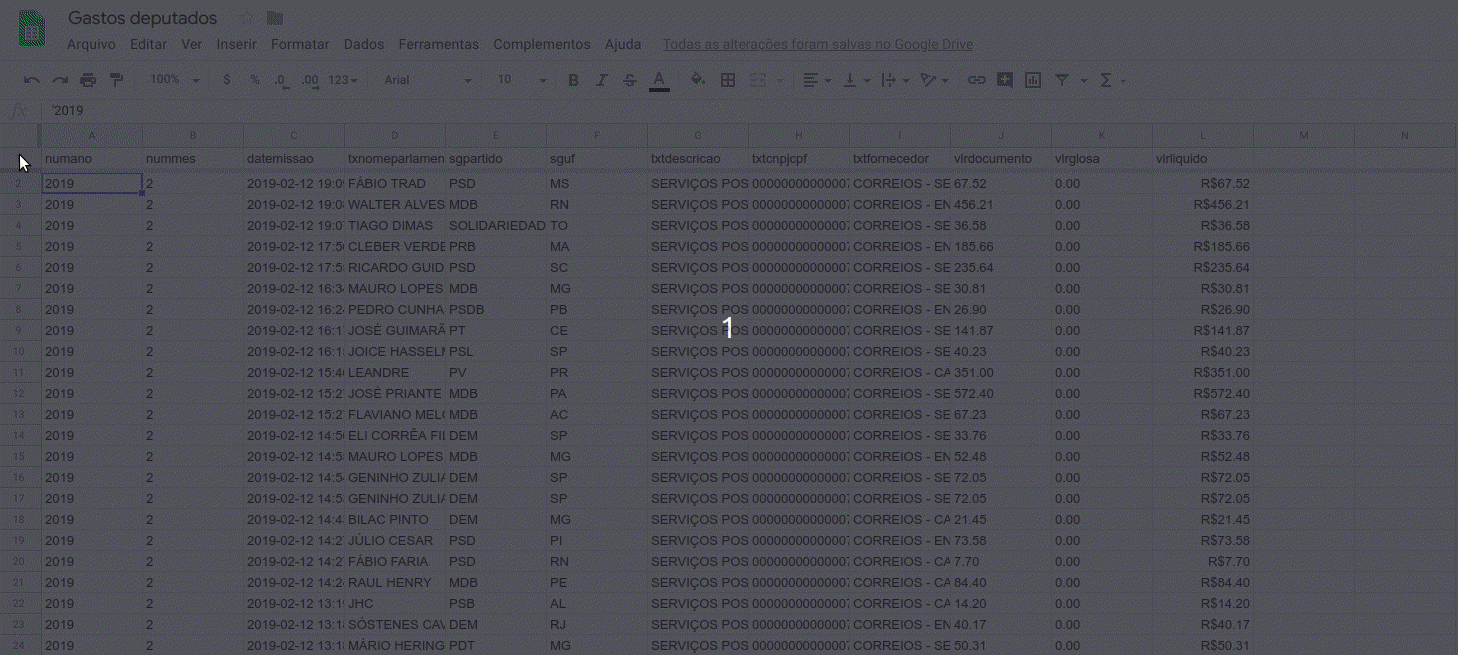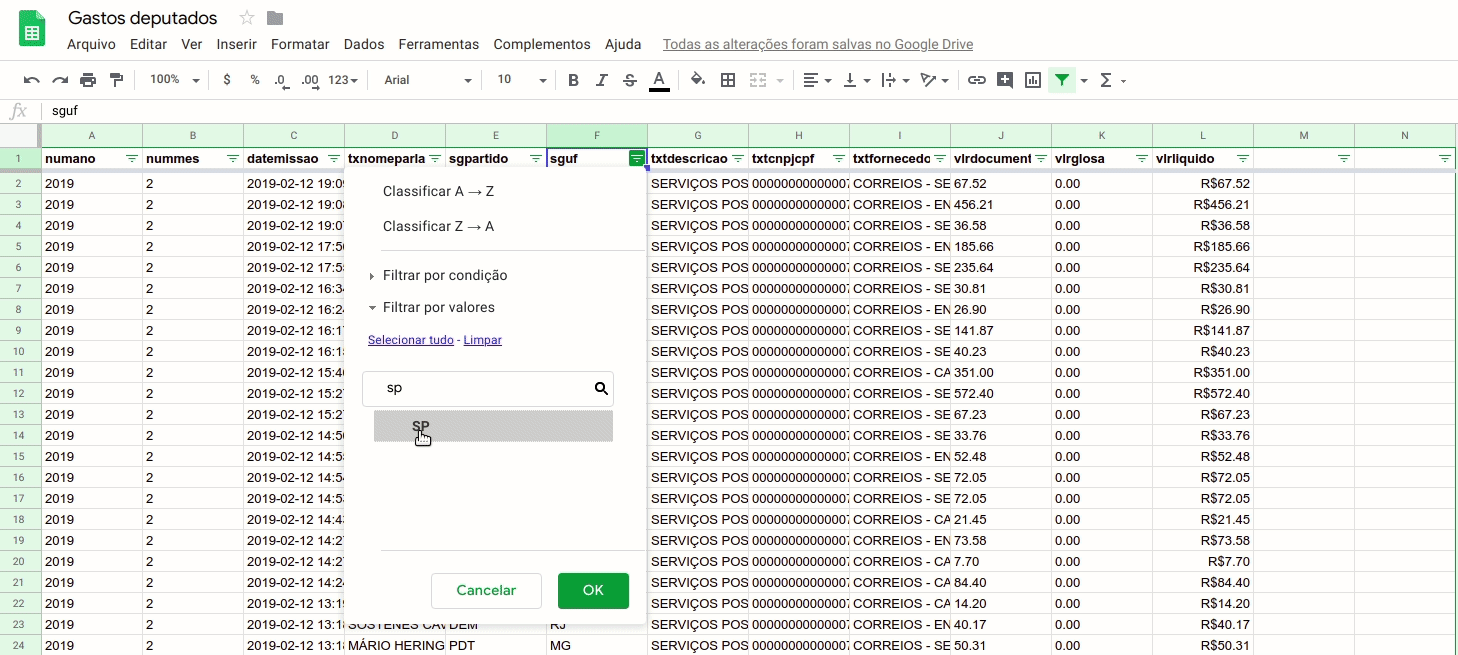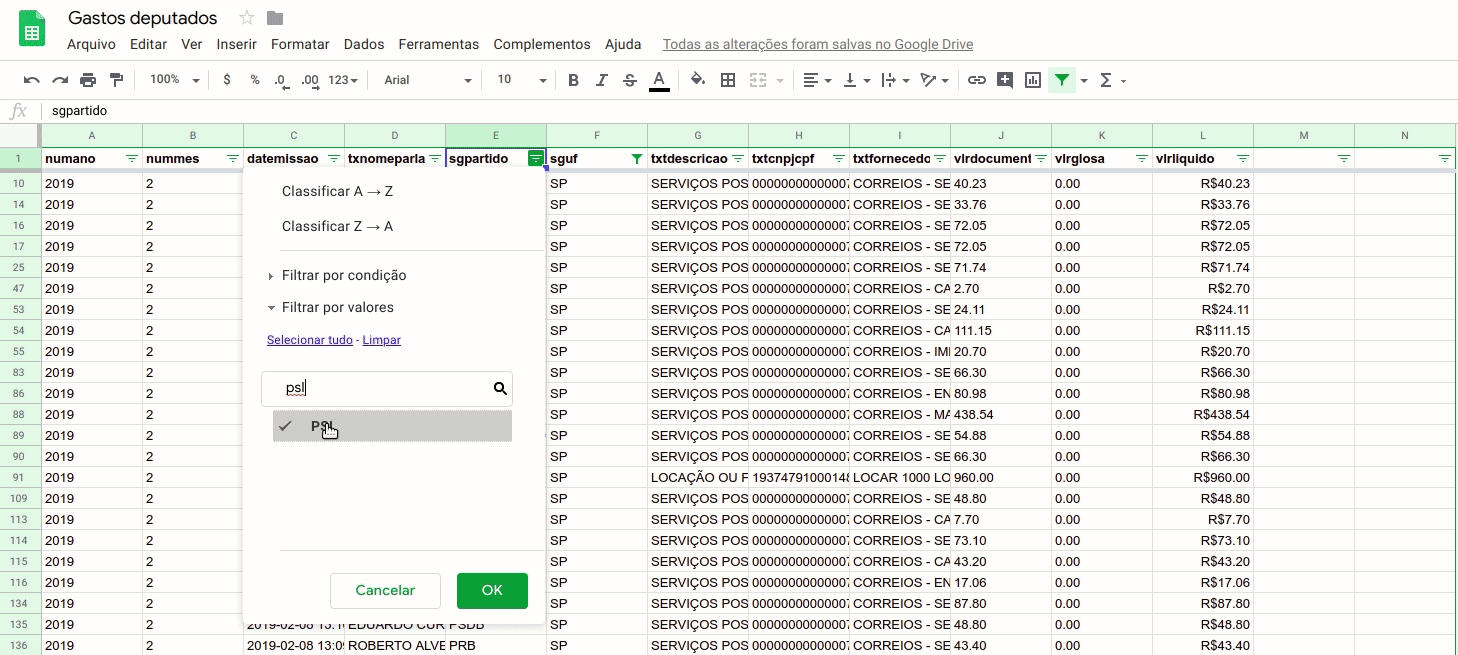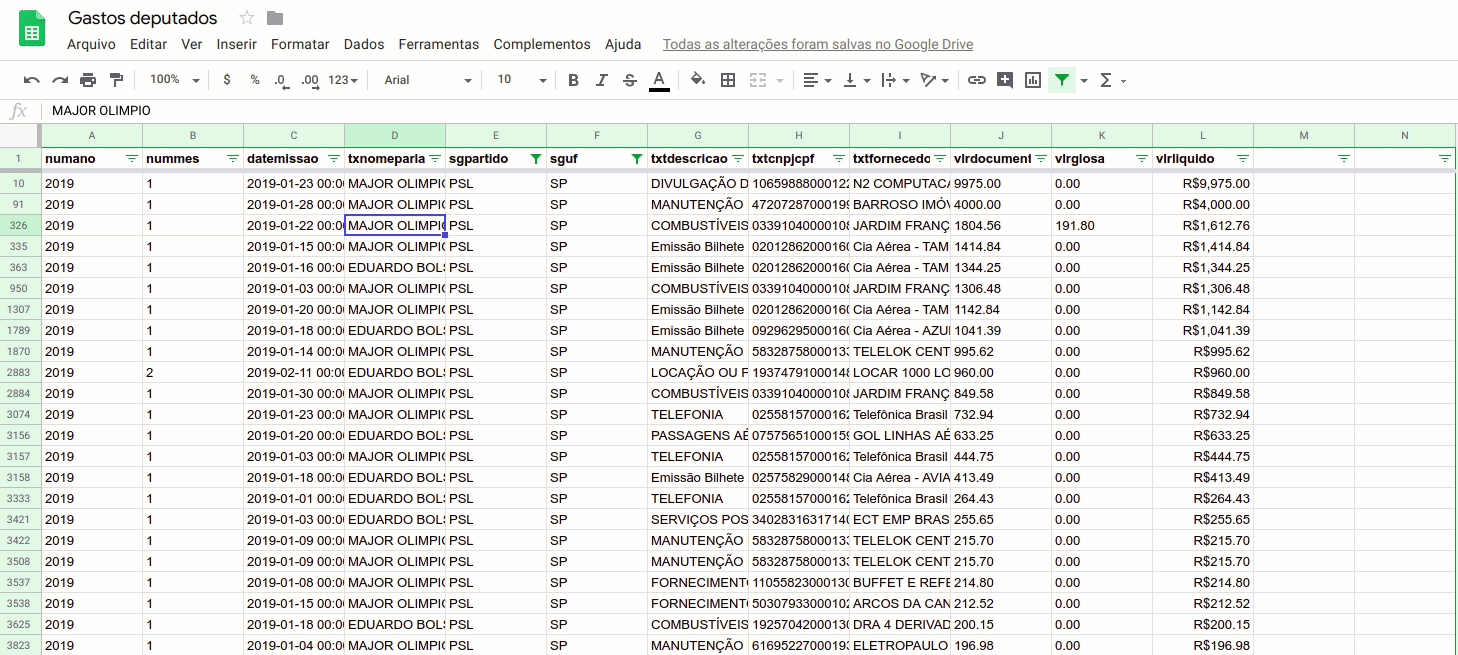
Assim, observamos que nos dias analisados, a maior despesa de deputados federais do PSL registrada foi de R$9,975.00, feita pelo deputado Major Olímpio com a empresa N2 COMPUTACAO GRAFICA LTDA.
OBSERVANDO A DISTRIBUIÇÃO
Agora, considerando todas as despesas de nossa tabela, vamos observar como se dá a distribuição dos valores nelas. Para isso, vamos criar um gráfico chamado histograma.
Primeiro, vamos desfazer nosso filtro e depois selecionar a coluna desejada. Então, clicamos em “Inserir”> “Gráfico”, escolhendo depois o tipo de gráfico desejado.
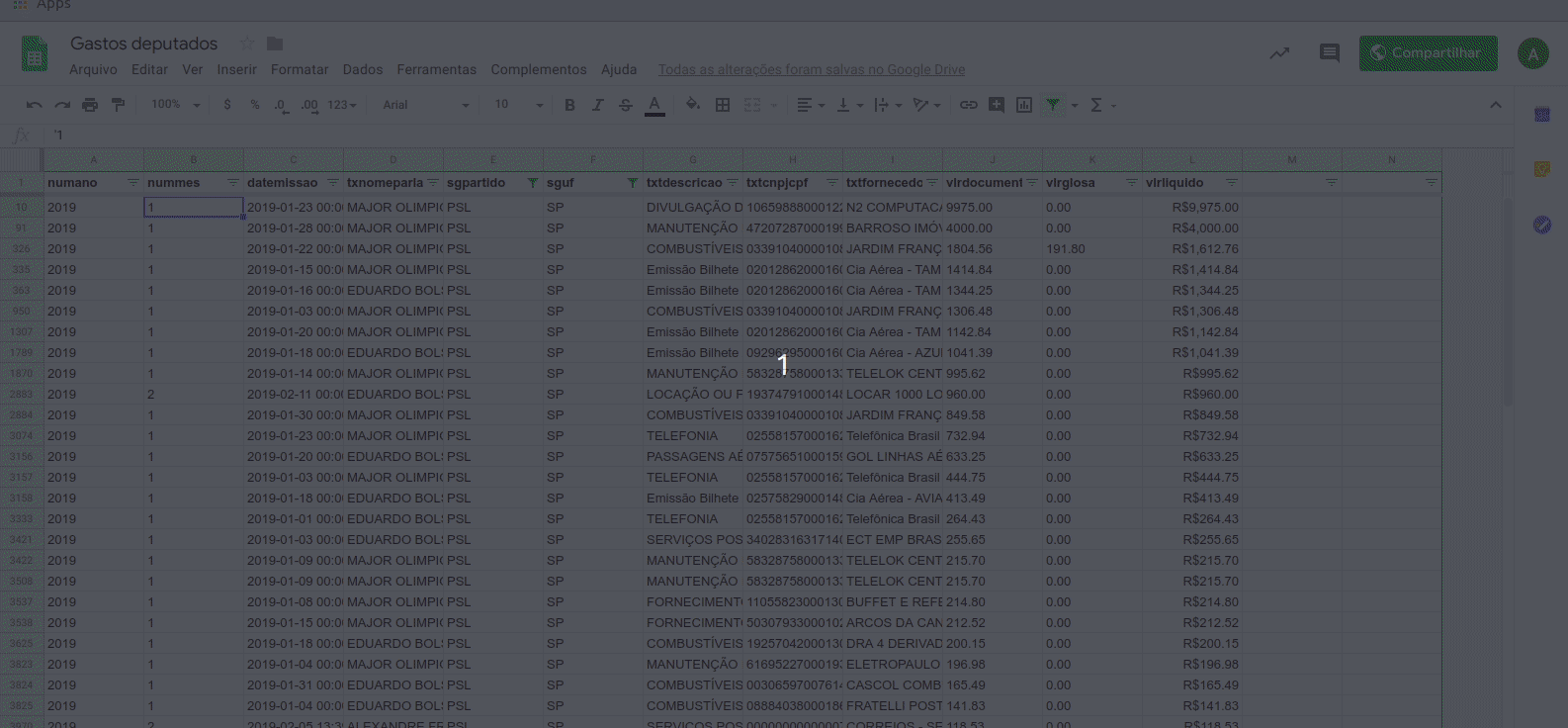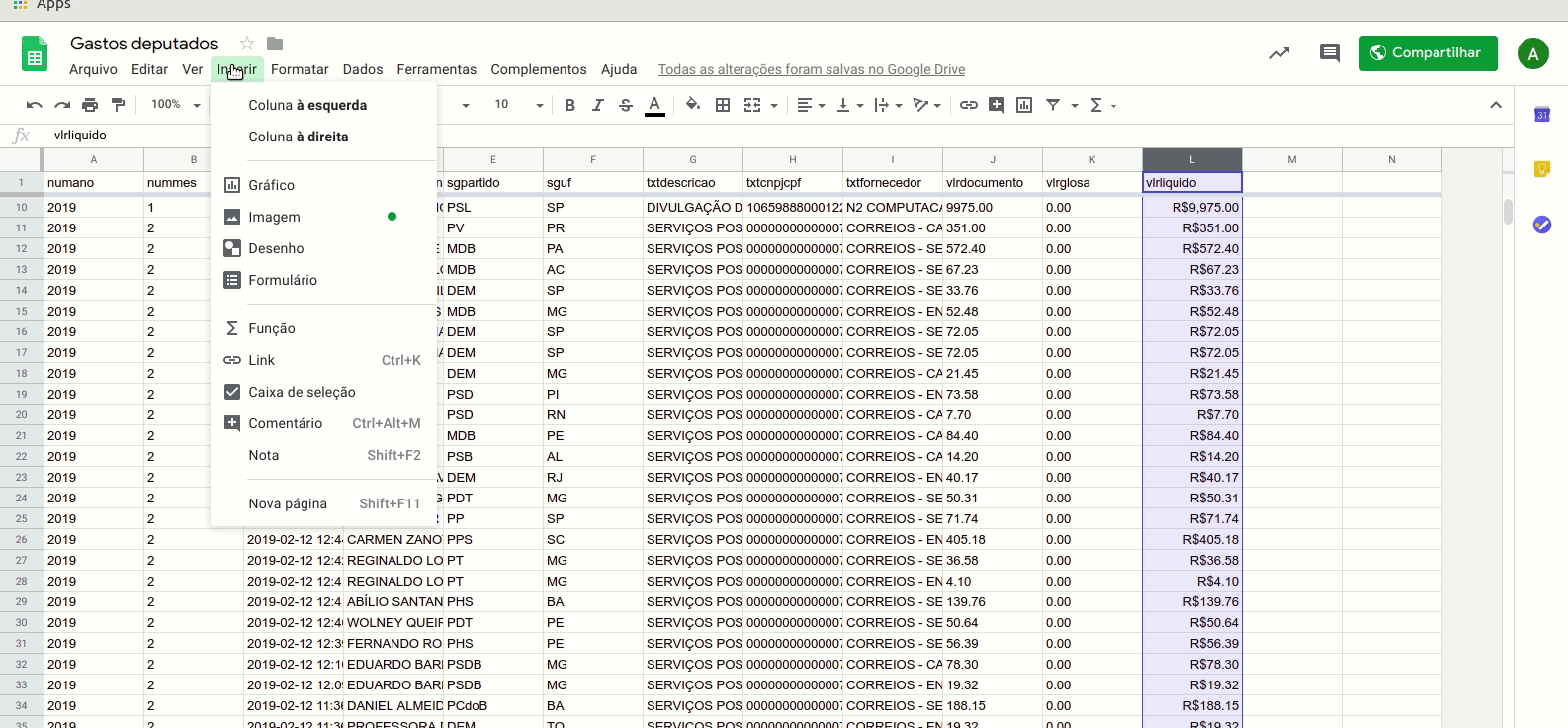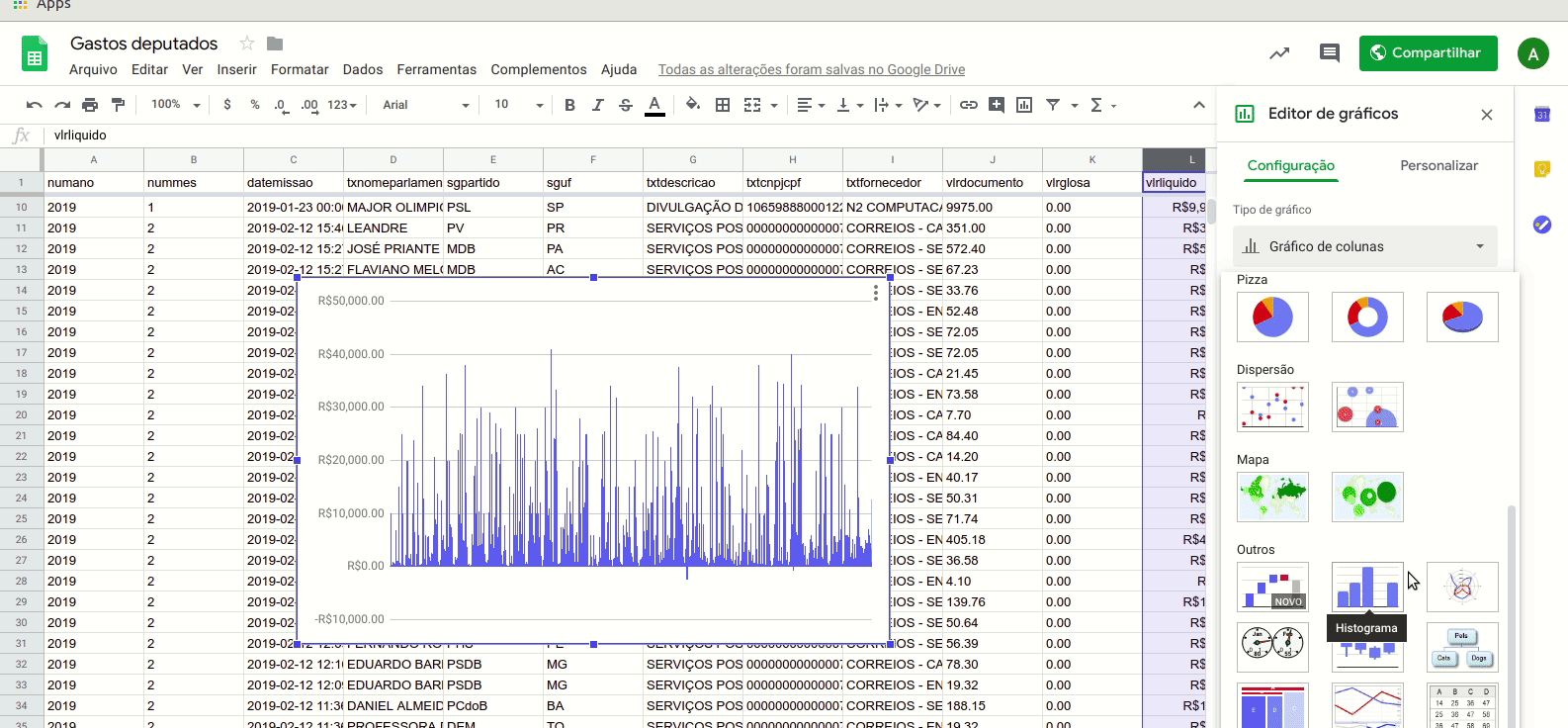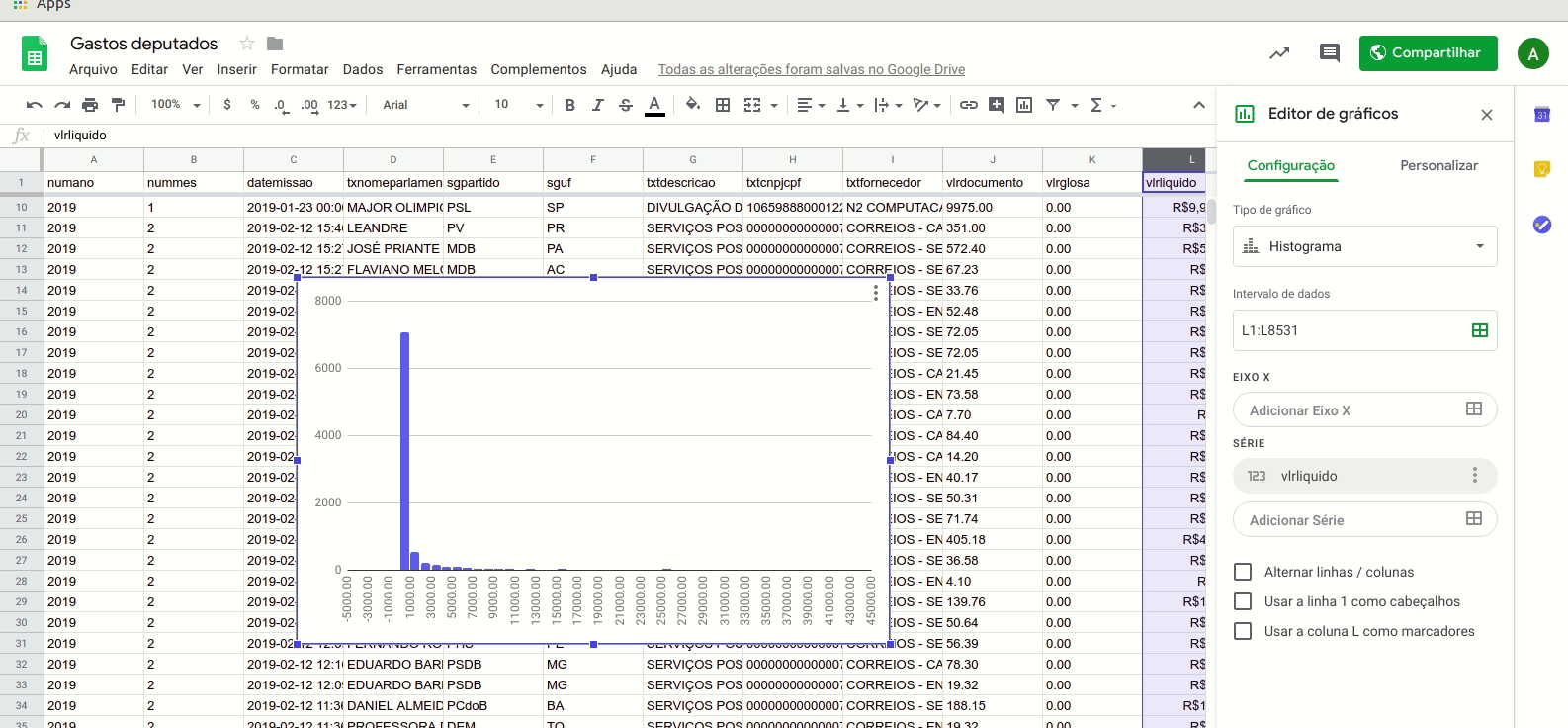
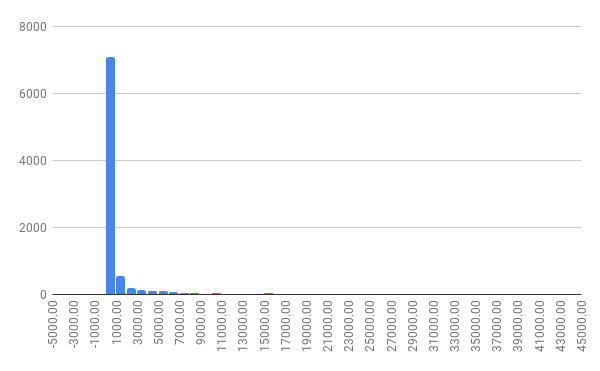
Vamos observar com cuidado o histograma, gráfico usado para visualizar a distribuição de uma série de valores numéricos contínuos. O eixo horizontal representa os valores, enquanto o eixo vertical contém o número de observações (ou despesas, no nosso caso) em cada faixa de valor. Para isto, são criados intervalos regulares (bins) para dividir os valores contínuos em colunas. Quanto maior a barra, mais observações existem naquele intervalo de valor.
Veja que os primeiros valores do eixo horizontal são negativos. Ou seja, existem alguns registros com números negativos no campo “valor líquido”. Para identificar se estes valores são erros ou registros reais, além de entender mais a fundo a metodologia de registro dos dados, poderíamos ordenar toda tabela por sua última coluna, de forma crescente. Assim, ficaria fácil identificar estes casos e investigá-los.
O problema do gráfico é que temos uma barra muito grande no intervalo inferior a R$ 1.000. Isso significa que a grande maioria das despesas não ultrapassa esse valor. Mas veja que há também outras barras menores. Só que a diferença entre estas e a maior coluna do gráfico é tão grande que mal conseguimos visualizá-las.
Podemos resolver esta dificuldade de leitura com um truque simples: colocando nosso eixo vertical em escala logarítmica.
Para fazer isto, basta selecionar a aba “Personalizar” no ‘Editor de Gráficos”, selecionar a opção “Eixo Vertical” e então marcar a caixa “Escala logarítmica”.
Assim, conseguiremos ver adequadamente o tamanho das colunas.
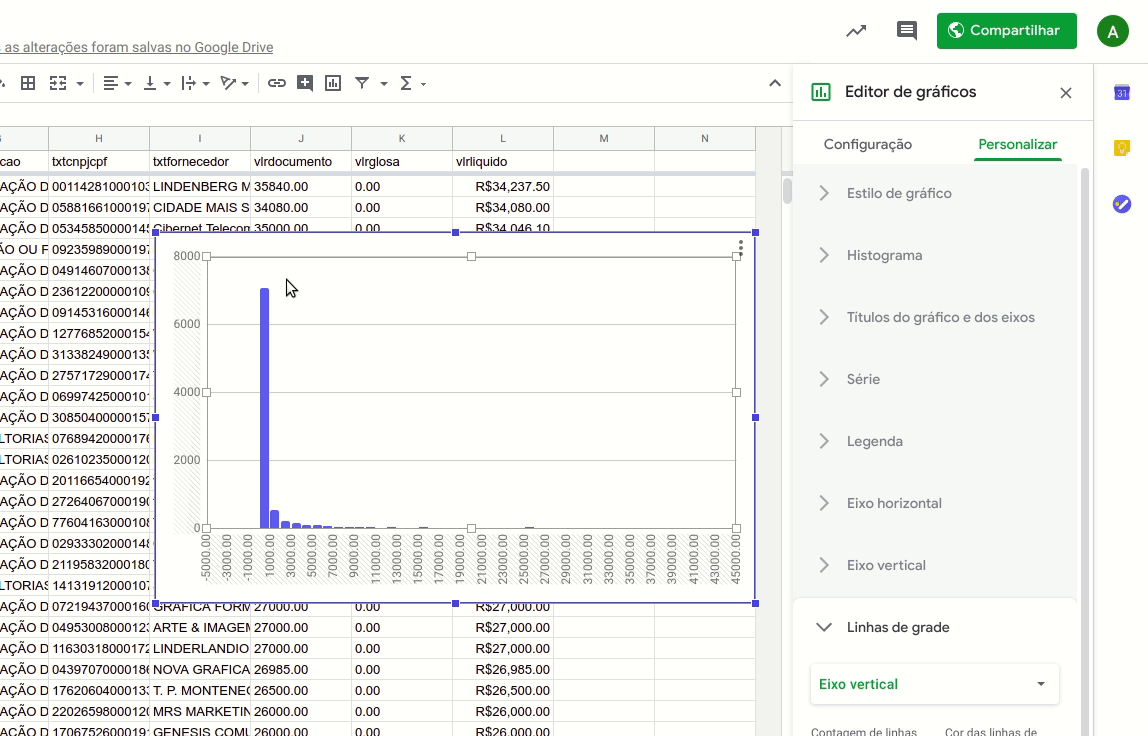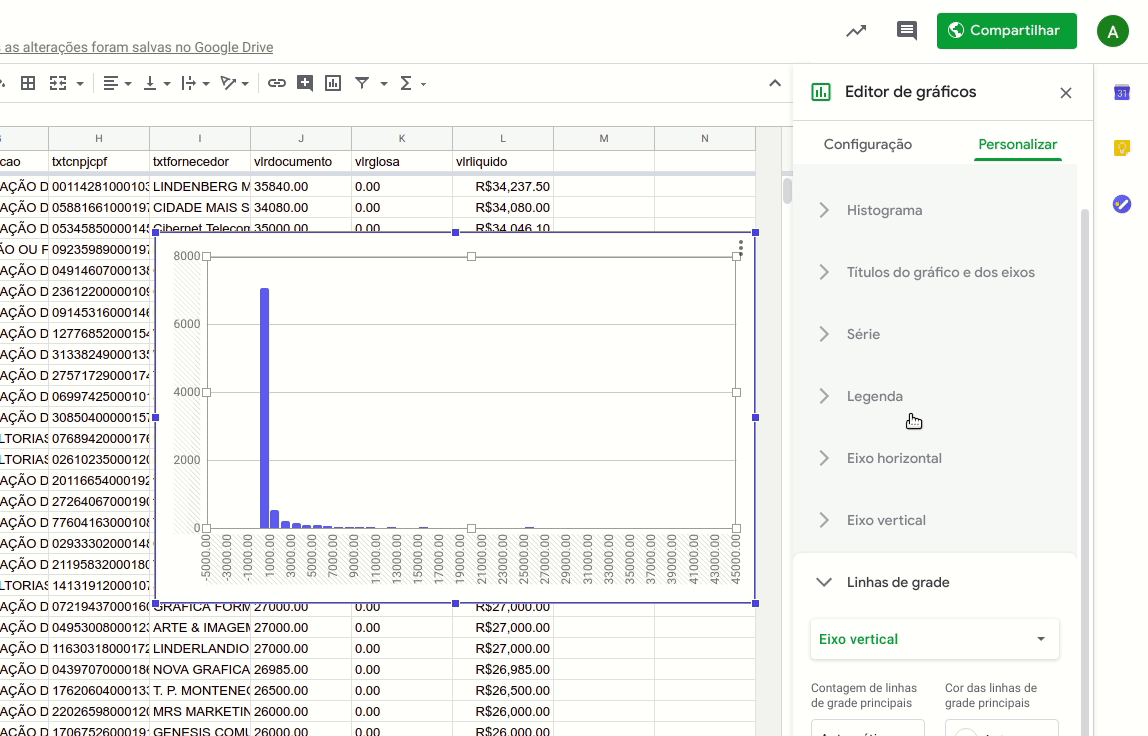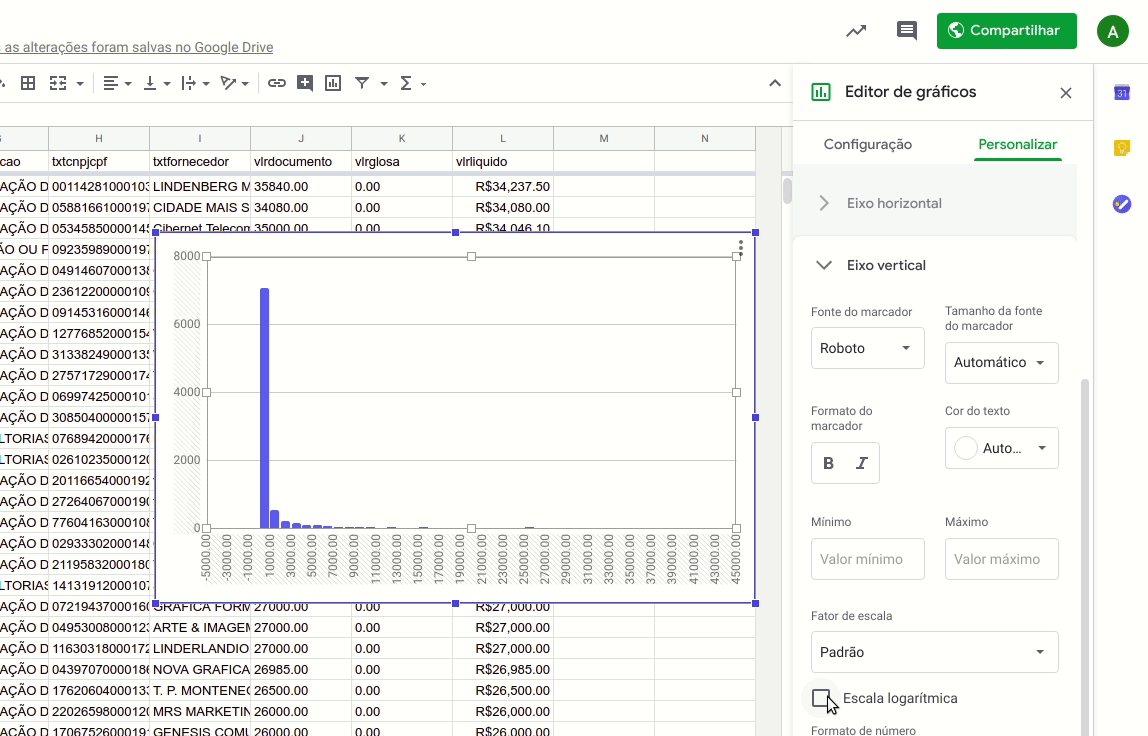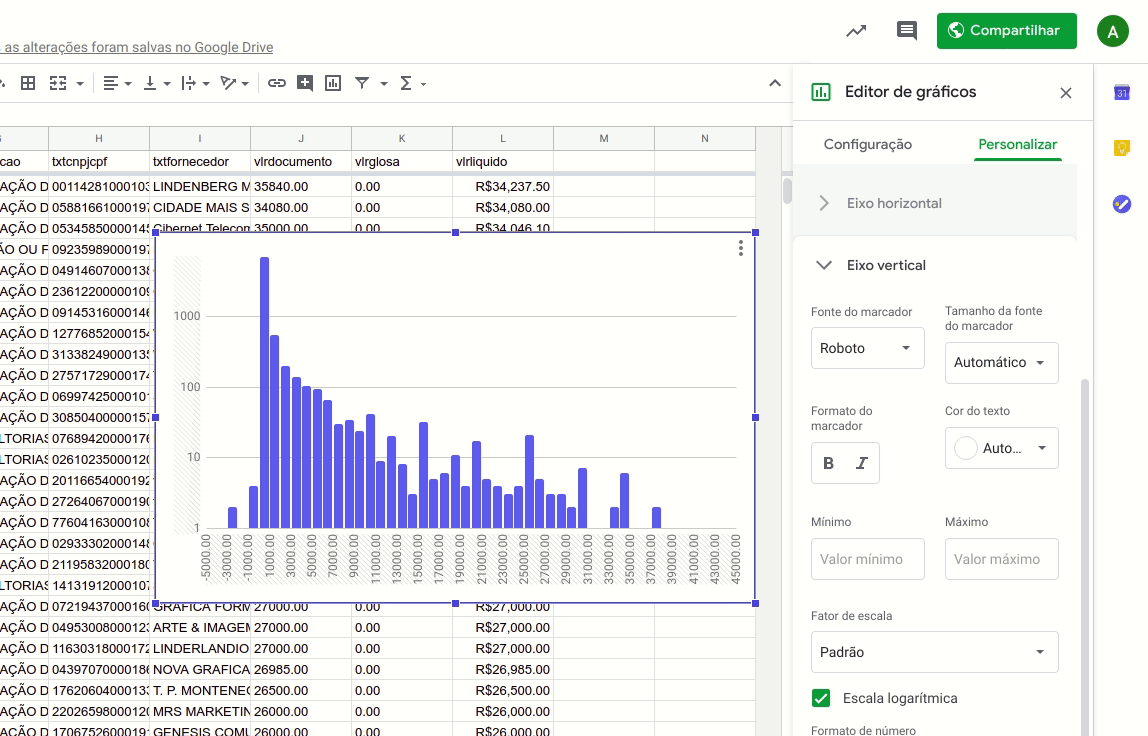
Com o eixo vertical assim, é possível visualizar melhor a diferença entre cada uma das colunas, que representam a contagem de despesas por intervalos de valor.
Passando o cursor sobre as barras, é possível ver quantas despesas estão registradas em cada faixa. No nosso caso, por exemplo, há 42 despesas entre R$ 10 e R$ 11 mil registradas nos dados.
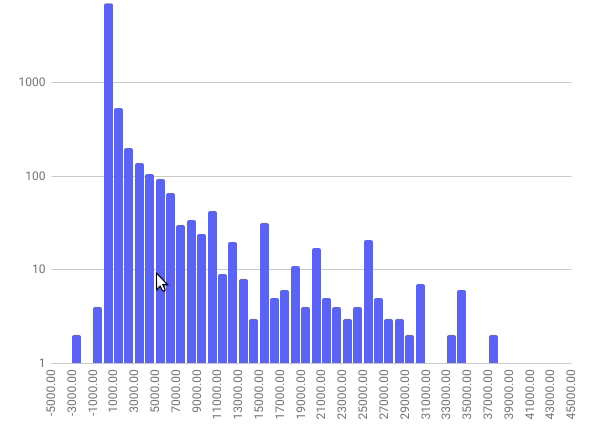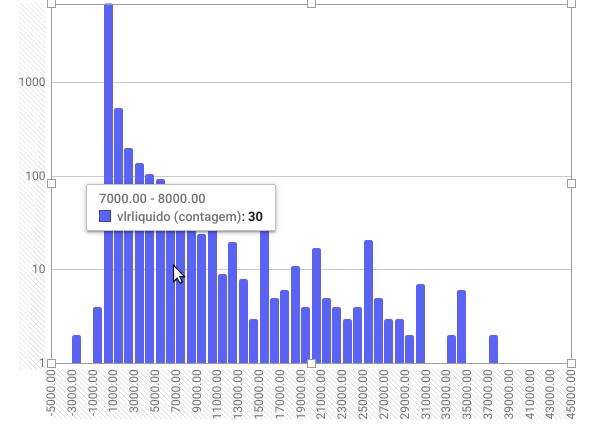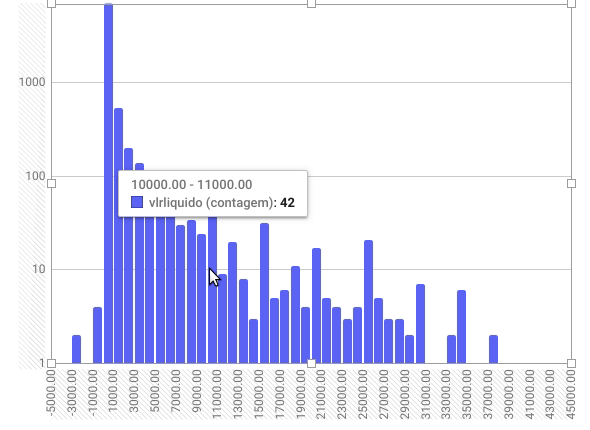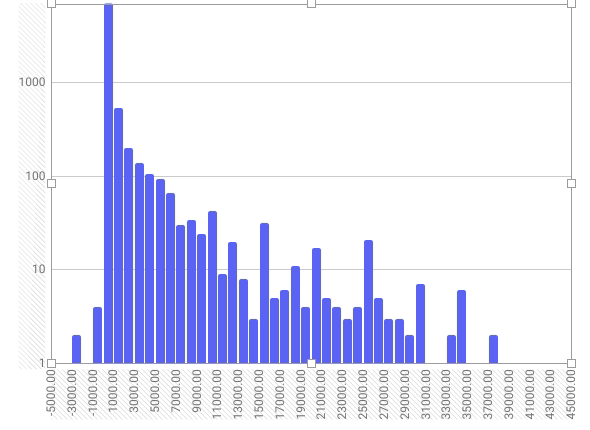
O histograma nos dá uma visão geral de como os valores de uma determinada variável estão distribuídos. Ele é uma das ferramentas mais básicas para analisar dados.
Se você quer saber mais sobre o assunto, confira também nossos dois tutoriais de introdução à análise de dados, onde demos um panorama do campo e apresentamos conceitos básicos de estatística descritiva.
* Este tutorial foi escrito por Adriano Belisário, coordenador da Escola de Dados









Excelente material. Obrigada
Gostei dessa dinâmica. Dá para praticar as buscas e assimilar o conteúdo das vídeo-aulas.
Didática muito boa, fácil entendimento.
Abç
Fantástico como este curso nos leva a perceber e aprender como o uso dos dados amplia nossas possibilidade de produção de grandes reportagens e de esclarecimento sobre muitas informações que estão abertas mas que não são exploradas de forma jornalística.
Maravilhoso
Maravilhoso tutorial. Se esquecer algum detalhe, só olhar aqui.
Não conhecia a técnica da escala logaritma, e olha que já li vários artigos e textos sobre análise de dados. BEM interessante!
Gerenciamento gráfico muito interessante. Obrigada
Nossa! Muito bom este tutorial! Estava com várias dúvidas e me esclareceu todas.
Execelente material!
Nunca tive acesso a um material tão esclarecedor! O jornalismo de dados nos abre um mundo de possibilidades e análises. Excelente!
Esclarece, de fato, a mecânica da coisa. Bem interessante.
Bem didático e muito bem explicado, mas achei ruim que prá fazer junto com o tutorial a nossa própria busca, some a janela do tutorial. Poderia abrir uma nova janela, prá trabalharmos nossos dados em conjunto com o tutorial. E confesso que sem fazer junto, ainda acho bem complicado.