
Se você já tentou explorar uma tabela muito grande no Excel ou outros editores de planilha, é provável que tenha enfrentado lentidão até para conseguir abrir o arquivo. Quando você tem muitos milhares ou até milhões de registros para analisar, então, é chegada a hora de conhecer um pouco mais sobre bancos de dados. Neste tutorial, veremos como explorar os dados por meio do SQL – structured query language ou, em bom português, linguagem de consulta estruturada.
Imagine que o banco de dados é uma enorme biblioteca que armazena todos os seus dados, com um bibliotecário de referência para auxiliar na consulta desses dados. O SQL é justamente a linguagem falada pelo bibliotecário para realizar as consultas, permitindo filtrar, cruzar, agrupar os registros de uma tabela, entre outras operações.
No banco de dados cada coluna tem um tipo definido (como “Texto” ou “Numérico”) e cada célula é representada pelo seu valor real, sem fórmulas por trás: o que você vê é o que você recebe. Tanto o editor de planilhas como o banco de dados têm seus prós e contras. No primeiro, é possível desenvolver uma boa apresentação visual, aspecto ignorado pelo banco de dados. Já os bancos de dados são superiores quando a tarefa é lidar com grandes volumes de dados.
Vantagens e desvantagens de planilhas
As vantagens de utilizar editores de planilhas para manipular são bem conhecidas:
- É fácil aprender e visualizar os dados;
- É fácil inserir e editar dados manualmente.
- Você tem várias recursos para customizar a identidade visual;
- Planilhas possuem uma estrutura muito flexível. Cada célula é única.
- Há várias integrações com outros softwares de fácil utilização;
- Fórmulas tornam o documento vivo.
- No mesmo programa, você já pode criar gráficos, comentários, além de ter correção ortográfica e etc.
Mas nem tudo são flores. Há também muitos problemas.
- Falta integridade dos dados. Como cada célula é uma unidade única, as coisas podem ficar muito inconsistentes. O que você vê não representa, necessariamente, os dados subjacentes. Um número não é necessariamente um número. Um editor de planilhas tenta fazer suposições sobre o que você quer e, às vezes, está errado. Um erro clássico é a conversão de campos com CPFs ou CNPJs para o tipo “numérico”, que remove o zero à esquerda e cria problemas com os dados.
- Não é muito bom para cruzar vários conjuntos de dados.
- Não é muito bom para responder a perguntas detalhadas com seus dados.
- Tem uma capacidade de leitura de dados limitada. À medida que a quantidade de dados aumenta, o desempenho é prejudicado. Os softwares (LibreOffice, Excel, Google Spreadsheets e outros) também possuem limites fixos para o quão grande uma planilha e suas células podem ser.
E os bancos de dados?
Se você tem um conjunto de dados muito grande ou pretende alimentar outras coisas com esses dados, aqui vai uma introdução prática, mostrando como utilizar o SQL para fazer consultas a bases de dados massivas. Na prática, você vai aprender como utilizar este “idioma” para entrevistar os dados.
Os bancos de dados em SQL são compostos por uma ou mais tabelas. Pense em uma tabela como uma planilha, com colunas e linhas, mas com mais regras. Para cada coluna é dado um nome (como “Endereço”) e definido um tipo de coluna (como “Inteiro”, “Data”, “Data + Tempo”, ou “Texto”). Você tem que escolher um tipo de coluna e permanecer com ele para todas as linhas. O banco de dados vai forçar todos os dados que você colocar para esse tipo.
Um banco de dados se concentra apenas na camada de dados das coisas e ignora a apresentação visual. Cores, fontes, bordas, formatação de dados e formatação de números basicamente não existem. O que você vê é principalmente o que você recebe. É uma boa e uma má notícia: isso significa que um banco de dados é geralmente muito bom no que ele faz, mas também muitas vezes precisa ser combinado com outras coisas a fim de criar um produto final, como um gráfico ou uma página web.
Um banco de dados é projetado para se conectar a outras coisas. Você pode utilizar, por exemplo, linguagens como Python e R para fazer consultas a bases de dados SQL. Aliás, você só está lendo este tutorial pois nosso sistema gerenciador de conteúdo fez uma consulta ao nosso banco de dados SQL quando você quis acessar esta página.
SQL: mão na massa
O programa que utilizaremos é o DB Browser for SQLite. Para fazer o download, acesse o site do programa aqui, escolha a versão compatível com seu sistema operacional e realize a instalação.
Nossos entrevistados serão os dados das candidaturas às últimas eleições brasileiras, disponibilizada pelo Tribunal Superior Eleitoral. Você pode fazer o download neste link. Depois, extraia os arquivos da pasta e busque pela tabela “consulta_cand_2018_BRASIL.csv”, que reúne informações dos candidatos às eleições de 2018, de todos os estados e para todos os cargos.
Importando os dados
Vamos começar importando nossa tabela para o DB Browser. Para isso, abra o programa e clique em “Novo banco de dados” ou utilize o atalho ctrl + N. Dê um nome para o arquivo e salve.
Em seguida, aparecerá a janela “Editar definição de tabela”. Como não vamos criar, mas apenas importar uma tabela, você pode fechar essa aba.
Para abrir a planilha “consulta_cand_2018_BRASIL.csv”, vá em Arquivo > Importar > Tabela a partir de arquivo de CSV. Depois, localize o arquivo no seu computador.
Vale ressaltar que o DB Browser só lê arquivos em .csv. Portanto, se você tem uma planilha no formato do Excel (xls), por exemplo, é necessário realizar uma conversão anteriormente. Porém, por ser um formato aberto, o CSV é um padrão muito mais prevalente na disponibilização de dados, então, raramente você terá esse tipo de problema.
Separador de campo e encoding
Na hora de importar arquivos CSV, é preciso ter muita atenção com dois parâmetros em especial: o caractere que funcionará como separador de campo e a codificação dos caracteres.
O primeiro é uma parte fundamental da estrutura de um arquivo CSV. Ele indica qual caractere separa as colunas da tabela. Em geral, os separadores de campos mais comuns são a vírgula e o ponto-e-vírgula. Caso sua planilha apareça com as colunas desformatadas, então, provavelmente o “separador de campo” escolhido está errado.
Já a codificação de caracteres (encoding) é basicamente um padrão para mapear as informações “em linguagem de computador” em letras, números e, enfim, caracteres legíveis por pessoas. Caso você perceba que sua tabela tem coisas estranhas no lugar de caracteres especiais, por exemplo, então, a codificação de caracteres escolhida está errada. Os três padrões mais comuns de codificação de caracteres são o ASCII (criado em 1968), o ISO 8859-1 (1987) e o UTF-8 (1996). Provavelmente seus dados estarão em um destes três formatos.
Estas dicas anteriores valem tanto para importar as tabelas para SQL, quanto para editores de planilha. Seguindo nosso exemplo, vamos configurar o separador de campo para ponto-e-vírgula (“;”) e a codificação caractere para “ISO-8859-1”, e também marcar a opção “Nomes das colunas na primeira linha”. Após estas configurações, clique em Ok.
Navegando nos dados
Se você seguiu os passos anteriores, agora, sua tabela já está estruturada como banco de dados. Vamos para a aba “Navegar dados” para explorar o que a tabela nos oferece.
Esse é o momento de analisar as características gerais da tabela, checar se você sabe o que significa cada linha e cada uma das colunas. Mesmo sem uma pergunta estabelecida antes de baixar a base de dados, durante esta etapa, você pode ter insights interessantes.
Como em outras bases de dados abertos, no caso das tabelas disponibilizadas pelo TSE, você encontra no arquivo compactado que foi disponibilizado um arquivo chamado “leiame”. Nele, há explicações sobre a base de dados deve ser interpretada e o significado de cada uma de suas colunas.
Agora que já nos familiarizamos com a base de dados, é hora de conhecer algumas funções básicas em SQL. Para isso, vamos fazer um exercício de tradução. Iremos começar com a seguinte pergunta:
Quantas candidatas não brancas possuem ensino superior completo ou incompleto?
Para isso, precisamos executar um código em SQL que se utilize das colunas ou variáveis de nossa base de dados para fornecer uma resposta.
No DB Browser, fazemos isso na aba “Executar SQL”.
Entrevistando dados
Agora, é hora de aprender um pouco sobre como utilizar SQL para fazer perguntas e consultas a bases de dados.
Tudo começa com a seleção das colunas que ajudam a responder à consulta que queremos. Antes de “traduzir” a pergunta que formulamos acima, faremos um exercício mais simples: como podemos selecionar todos os registros de todas colunas de uma base de dados?
Qualquer consulta a uma base SQL precisa de duas “palavras mágicas”: SELECT e FROM. Afinal, você quer selecionar algo (select) de algum lugar (from). Após o comando SELECT, precisamos definir as colunas desejadas. E após o FROM especificamos a tabela que contém estas colunas.
No nosso caso, a tabela se chama “consulta_cand_2018_BRASIL” e vamos usar um truque para não ter que digitar o nome de todas as colunas: o asterisco, que é um caractere “coringa” para retornar todas as colunas. Então, nossa primeira consulta fica assim:
select * from consulta_cand_2018_BRASIL
Para fazer sua consulta, clique no botão play ou use os atalhos F5 ou ctrl + R.
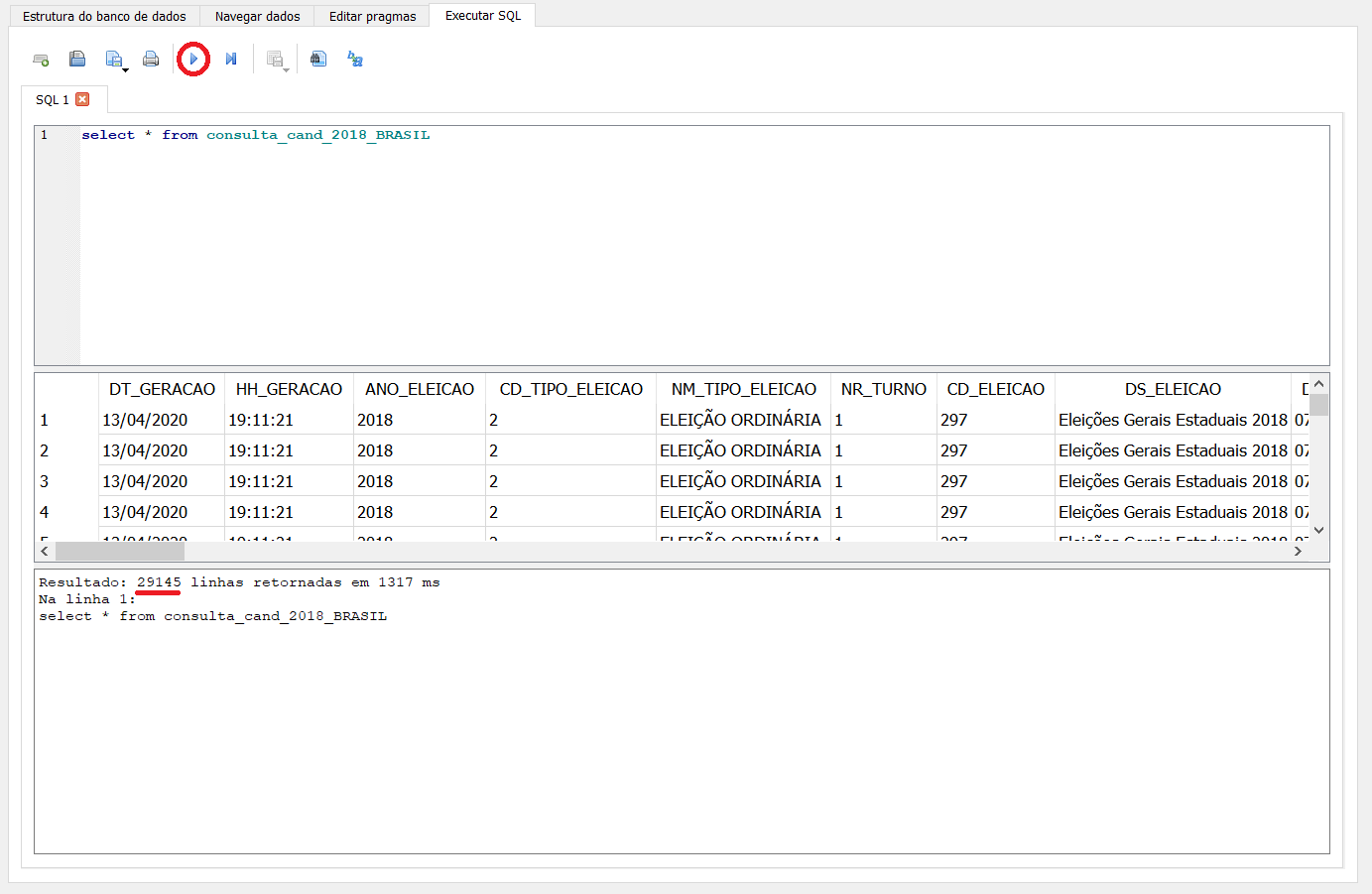
Fácil, né? O resultado retornado foi de 29.145 linhas. Como neste caso, cada linha significa um candidato, podemos interpretar que este é também o número de candidaturas em 2018. Agora, vamos incrementar um pouco mais nossa consulta.
Filtrando resultados
Já vimos que a estrutura básica de uma consulta SQL envolve o comando SELECT para selecionarmos as colunas desejadas e o FROM para definir a tabela que será o “alvo” de nossa consulta.
Agora, veremos como podemos fazer filtros, ou seja, selecionar registros que atendam a uma determinada condição. Como queremos saber quantas candidatas não brancas possuem ensino superior incompleto ou completo, vamos primeiro fazer o filtro por gẽnero.
No SQL, podemos filtrar as linhas usando a palavra WHERE. Depois, definimos qual coluna queremos usar como filtro e, então, qual valor esperado para este filtro. No nosso exemplo, a coluna que indica o gênero das pessoas que se candidatam se chama DS_GENERO e o valor desejado é ‘FEMININO’. Então, nosso código fica assim:
select * from consulta_cand_2018_BRASIL
where DS_GENERO = ‘FEMININO’
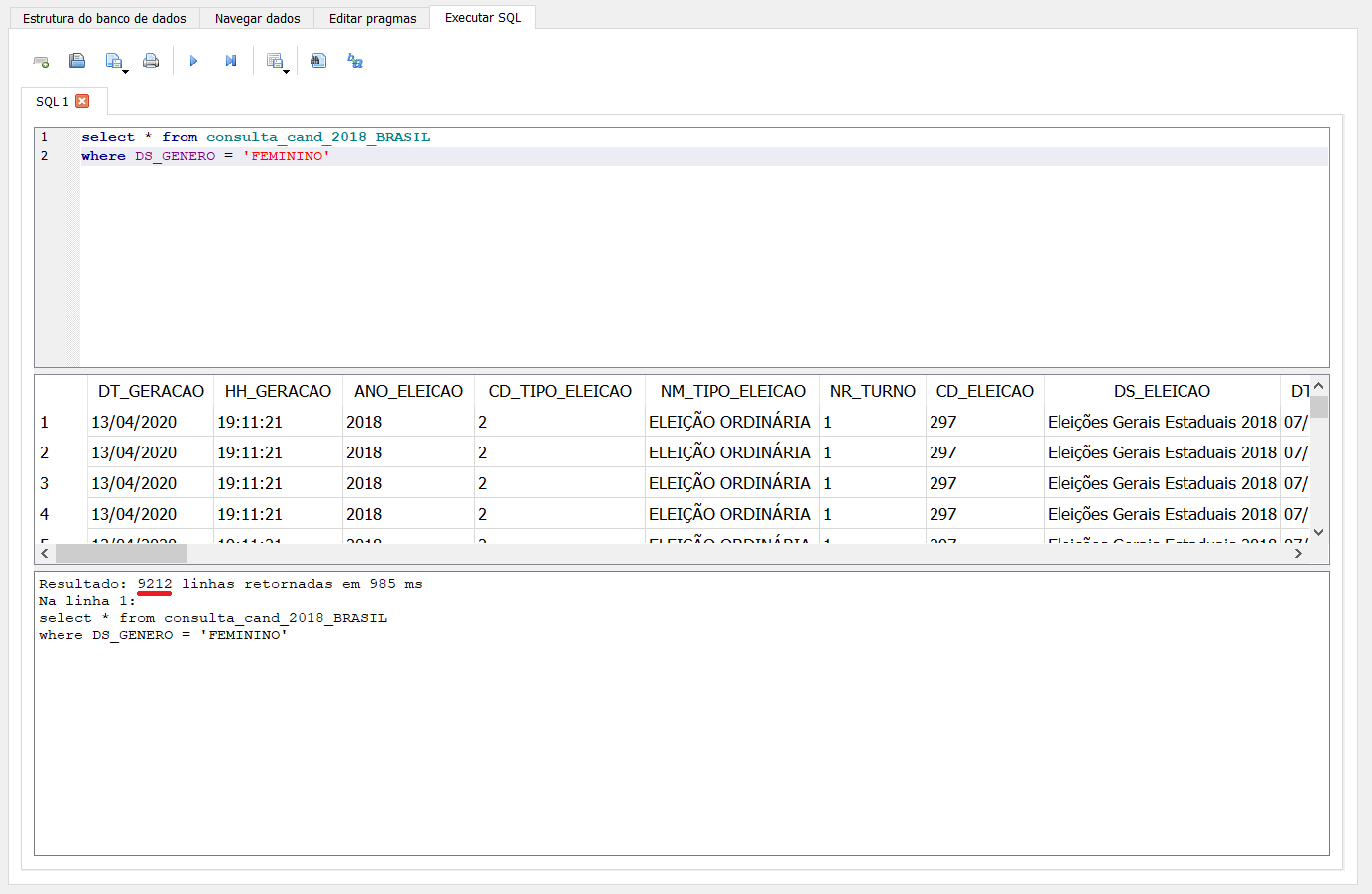
Lembre de utilizar as aspas simples para definir o texto que deve ser filtrado na coluna também.
O resultado foi de que há 9.212 pessoas com gênero “feminino” registradas na tabela.
Antes de prosseguir na nossa pergunta, vamos filtrar e organizar as colunas que serão exibidas no resultado. Clique em abrir aba e em uma nova SQL, digite a consulta a seguir:
select DS_COR_RACA as cor, DS_GRAU_INSTRUCAO as instrucao from consulta_cand_2018_BRASIL where DS_GENERO = ‘FEMININO’
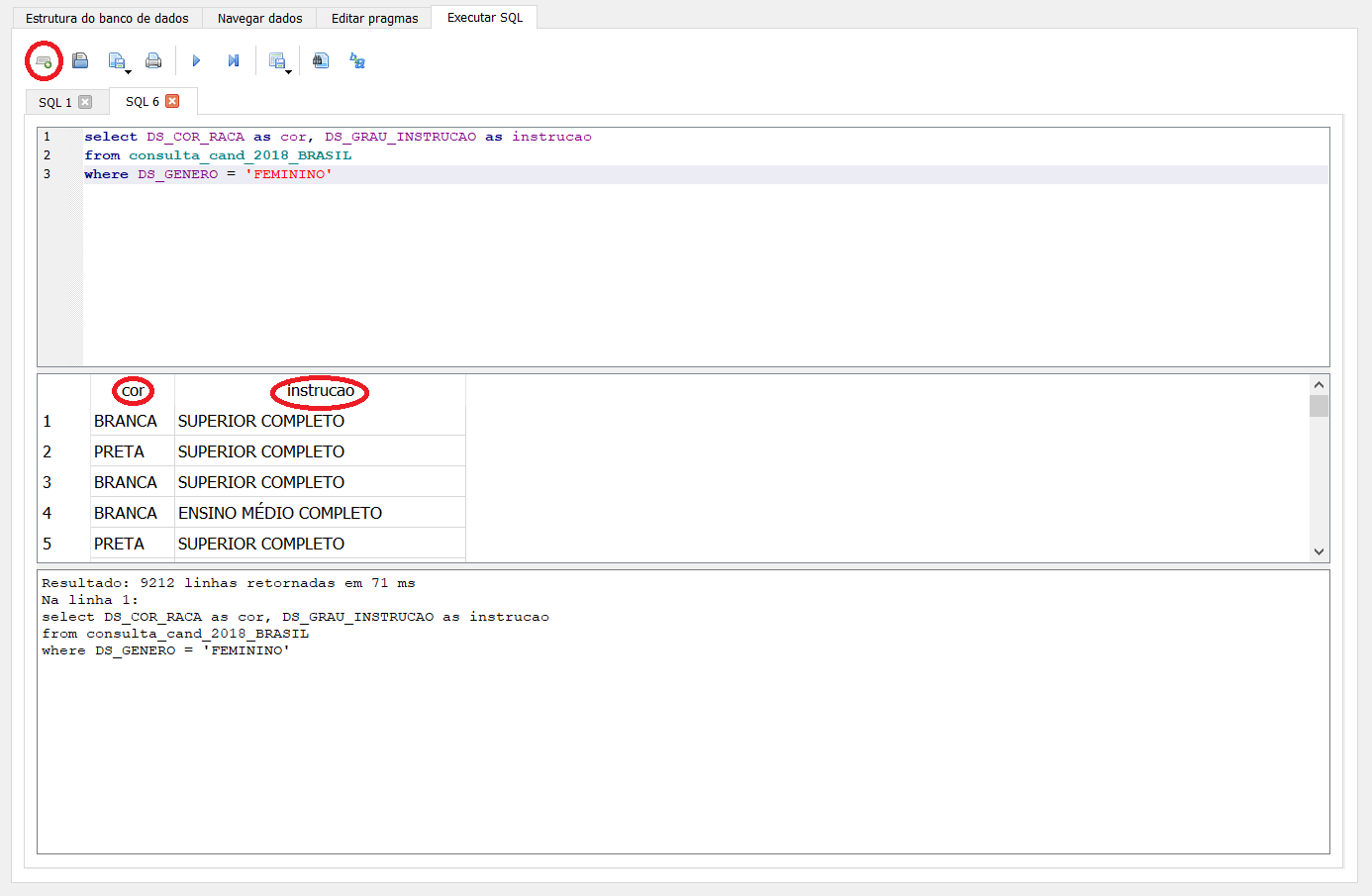 Agora, ao invés de selecionarmos todo o conteúdo da tabela, selecionamos apenas as colunas que nos interessam, e as renomeamos utilizando a função as.
Agora, ao invés de selecionarmos todo o conteúdo da tabela, selecionamos apenas as colunas que nos interessam, e as renomeamos utilizando a função as.
Vamos filtrar então para que os resultados retornem apenas candidatas que tenham ensino superior completo ou incompleto. Adicione and instrucao like ‘SUPERIOR%’
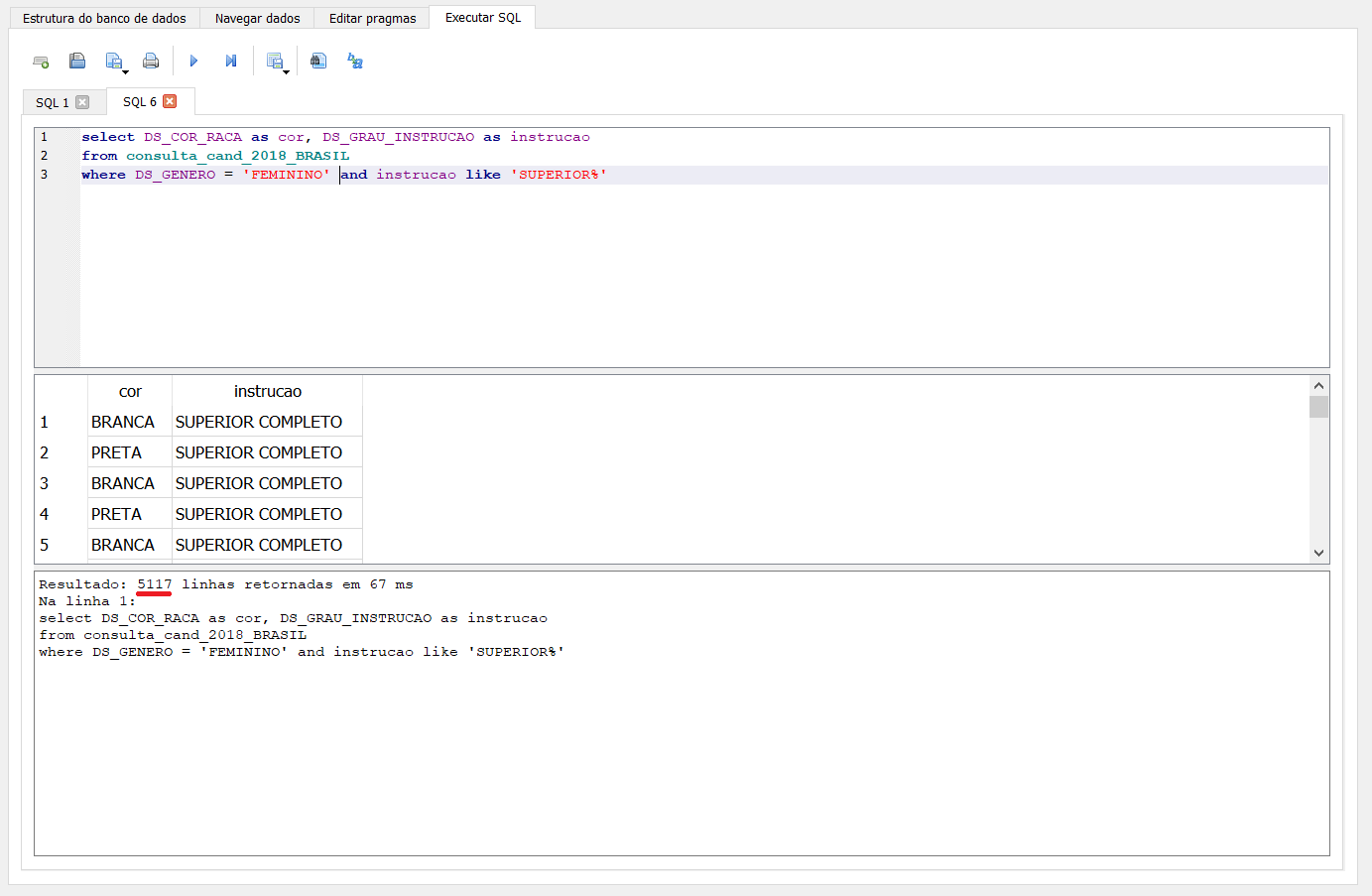 O operador like permite trazer todos os registros similares a “SUPERIOR”, podendo ter algo de diferente após a palavra, por isso é adicionado a % ao final do termo. Sabemos agora então que das 9.212 candidatas, 5.117 possuem ensino superior completo ou incompleto.
O operador like permite trazer todos os registros similares a “SUPERIOR”, podendo ter algo de diferente após a palavra, por isso é adicionado a % ao final do termo. Sabemos agora então que das 9.212 candidatas, 5.117 possuem ensino superior completo ou incompleto.
Respondendo a nossa pergunta, quantas dessas não são brancas? Adicione and cor != ‘BRANCA’
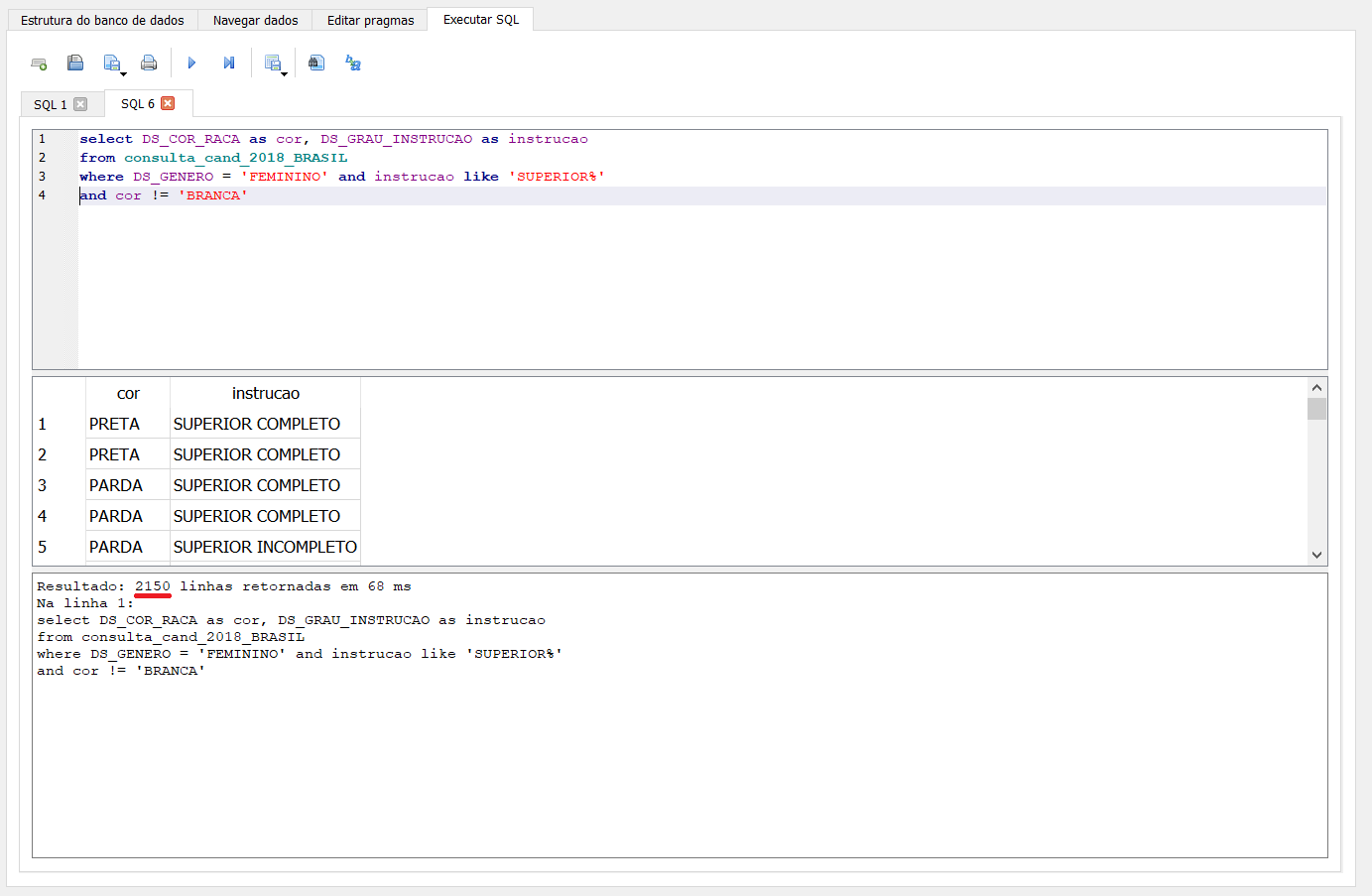
O operador != representa diferença e, nesse caso, permitiu que todos os registros diferentes de “BRANCA” na coluna “cor” fossem exibidos.
Das 5.117 candidatas que possuem ensino superior completo ou incompleto, 2.150 candidatas são pretas, pardas, amarelas ou indígenas.
Agora que nossa pergunta foi respondida, vamos além! Queremos saber quantas candidatas há de cada cor nas categorias ensino superior completo e ensino superior incompleto. Para isso, adicione count (*) as resultado antes de from consulta_cand_2018_BRASIL e group by instrucao, cor ao final da consulta.
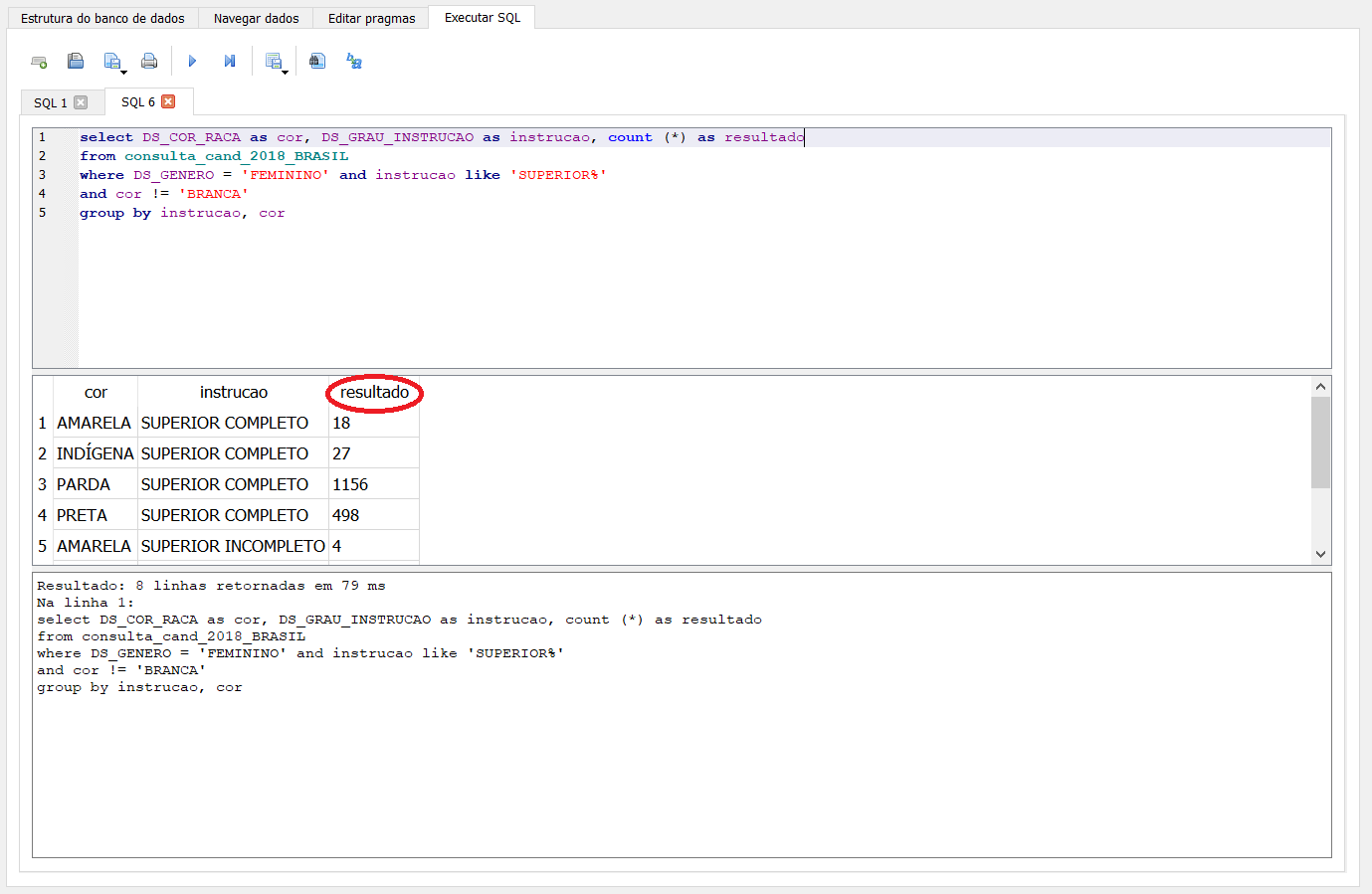 A função group by agrupa os registro de coluna a partir dos registros de outra. Nesse caso, foram agrupados os registros da coluna cor, pelos registros da coluna instrucao.
A função group by agrupa os registro de coluna a partir dos registros de outra. Nesse caso, foram agrupados os registros da coluna cor, pelos registros da coluna instrucao.
A função count (*) contou quantos registros há em cada grupo, e a partir do operador as, exibimos esse resultado em uma nova coluna chamada resultado.
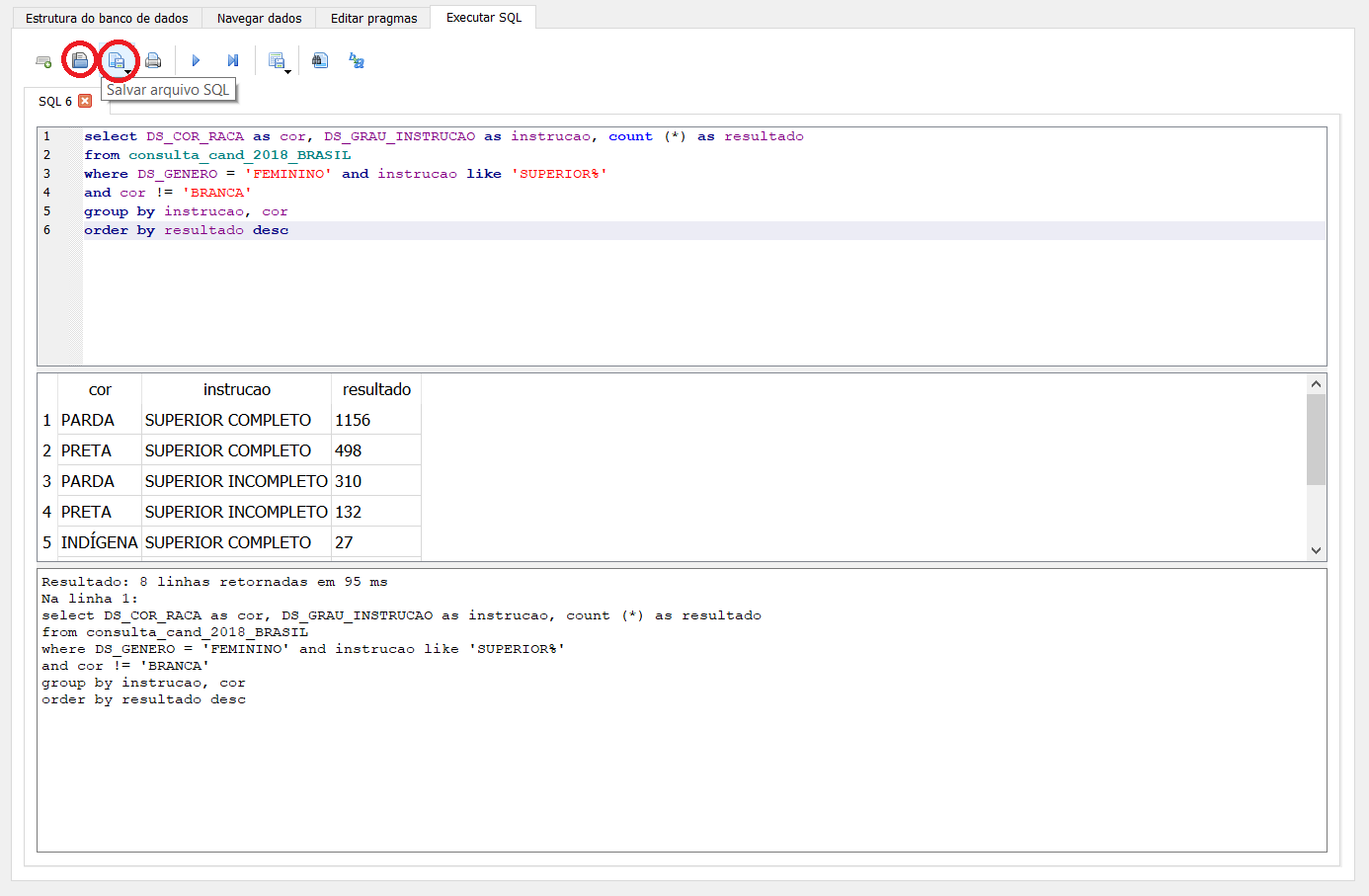
Por fim, podemos organizar esse resultado utilizando a função order by. Ela organiza os registros automaticamente em ordem ascendente (asc). Por isso, se quiser em ordem descendente, é necessário adicionar o desc. Adicione ao final da consulta order by resultado desc
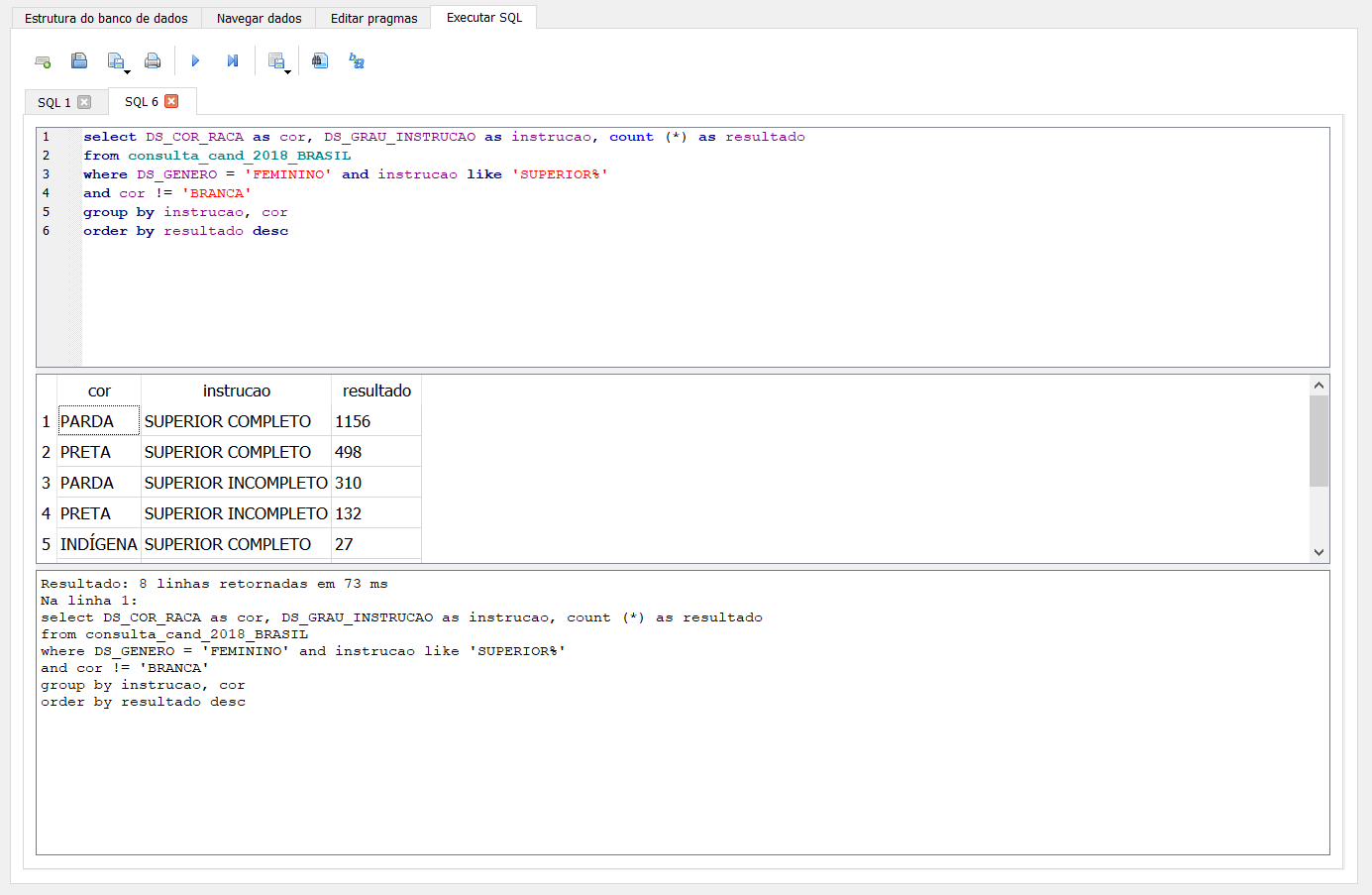 Antes de fechar o projeto, você pode salvar a consulta realizada clicando em Salvar arquivo SQL. Depois, você pode executá-la novamente no mesmo ou em outro projeto, clicando no botão do lado esquerdo, Abrir arquivo SQL.
Antes de fechar o projeto, você pode salvar a consulta realizada clicando em Salvar arquivo SQL. Depois, você pode executá-la novamente no mesmo ou em outro projeto, clicando no botão do lado esquerdo, Abrir arquivo SQL.
Este tutorial foi escrito por Manuella Caputo e revisado por Edilaine dos Santos e Adriano Belisário. O texto foi baseado no módulo “SQL para grandes bases de dados” ministrado por Álvaro Justen no curso online sobre jornalismo de dados, organizado pelo Knight Center em parceria com a Escola de Dados. Para acessar o conteúdo completo do curso, clique aqui. Também foram utilizados o texto ‘SQL – Database vs Excel’ publicado por Noah Veltman e traduzido pela Escola de Dados no site iMasters (parte 1 e parte 2).









Gostei, muito bem explicado, ajudou muito para a compreensão inicial de perguntas em grandes bases, obrigado!
Muito bem explicado e motivador para quem está começando com SQL. Parabéns.
Bem legal esse tutorial!!!!
Bom o suficiente para tirar aquele medo bobo e curto o suficiente para deixar aquele gostinho de quero mais…. agora é: bora apreender SQL!!!
Muito bem explicado, a dificuldade é a dificuldade natural de quem está iniciando. Obrigado.