
A partir de agosto de 2021, as sanções da Lei Geral de Proteção de Dados (LGPD) entram em vigor e empresas e instituições estão (ou deveriam estar) correndo atrás de adequarem suas práticas de coleta e gerenciamento de dados à nova legislação. Neste tutorial, elaborado a partir do exercício de Fréderic Le Guen e das contribuições de Rafael Zanatta no contexto do curso ‘Publicadores de dados: da gestão estratégica à abertura’, mostraremos como utilizar uma função dos editores de planilha para aplicar uma técnica de desidentificação simples.
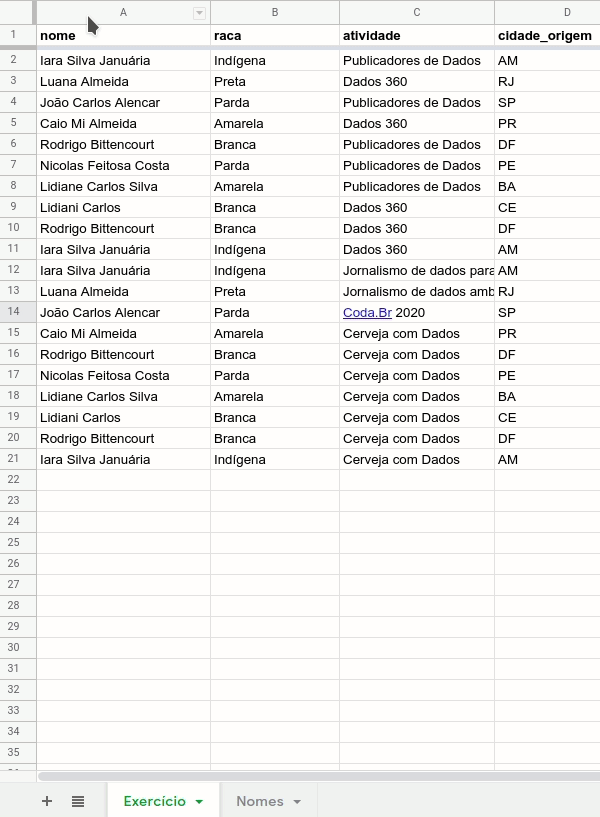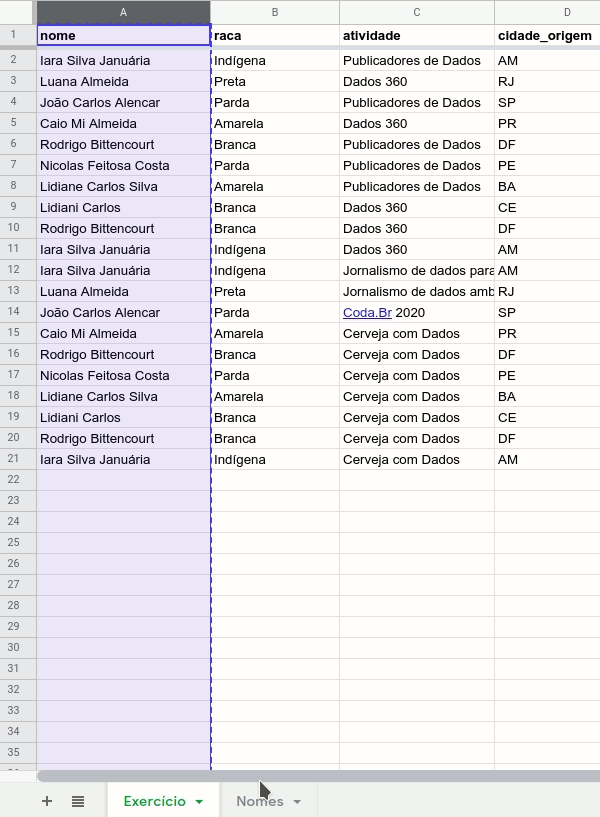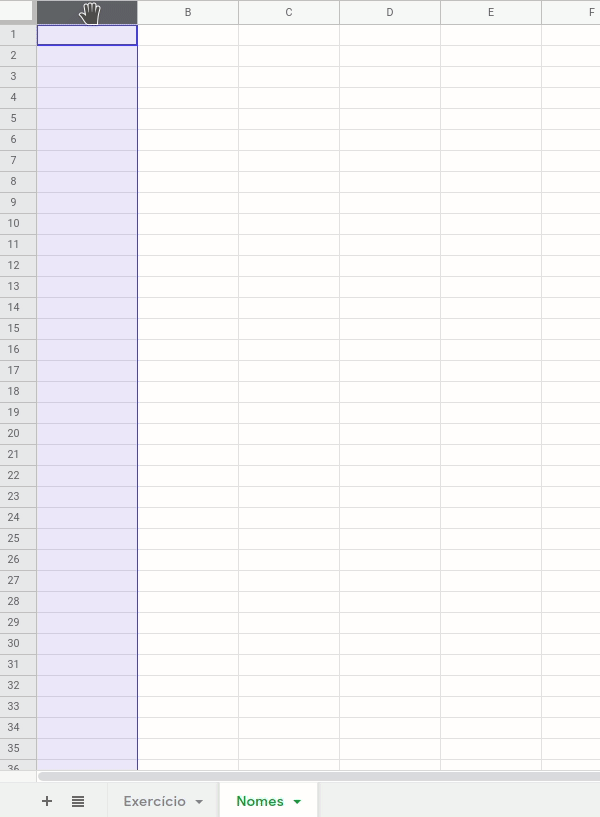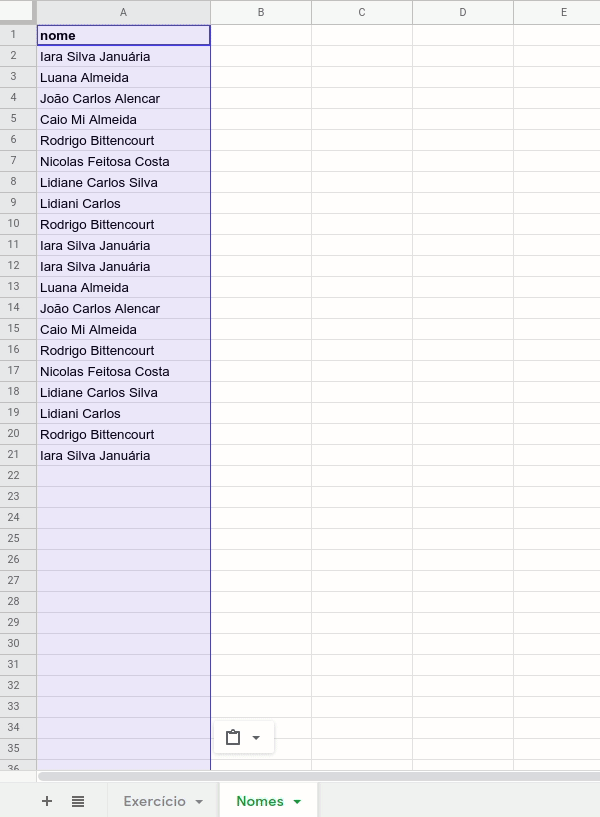
Vamos usar como base esta tabela com dados fictícios, que representam as avaliações de um grupo imaginário de pessoas sobre atividades da Escola de Dados. O objetivo é publicar avaliações sem expor a identidade das pessoas diretamente, nem reduzir as possibilidades de análise dos microdados.
Aqui, a única coluna ou variável que permite a identificação é a primeira, que traz o nome das pessoas envolvidas. Mas nem sempre este é o caso.
É possível por exemplo que, mesmo sem o nome, outras informações aparentemente mais gerais, como gênero, idade, raça, endereço e etc, permitam identificar uma pessoa de forma inequívoca. Falaremos mais sobre isso abaixo, porém, no tutorial prático, abordaremos um conjunto de dados mais simples.
Se simplesmente deletarmos este campo, perderemos informações valiosas, como a possibilidade de fazer uma média das notas das atividades por pessoa. Para preservar possibilidades analíticas e diminuir a exposição das pessoas envolvidas, podemos adotar a técnica de pseudonimização.
Pseudonimização e seus limites
Pseudonimização é uma dentre as diversas técnicas de desidentificação disponíveis. Como o nome indica, ela consiste em criar pseudônimos e então trocar os nomes originais por estes novos valores.
Basicamente, vamos criar um identificador único para cada nome e então substituir cada nome por seu respectivo identificador.
“A pseudonimização é o tratamento por meio do qual um dado perde a possibilidade de associação, direta ou indireta, a um indivíduo, senão pelo uso de informação adicional mantida separadamente pelo controlador em ambiente controlado e seguro” (Art. 13 da LGPD)
Antes de começar, é importante saber de algumas limitações deste método.
Se alguém tiver posse da tabela que relaciona cada nome real aos identificadores, conseguirá “reverter” nossa anonimização. Por isso, a LGPD exige que esta informação seja mantida “separadamente” pelo controlador dos dados em um “ambiente controlado e seguro”. Ou seja, com a pseudonimização, não se “perde a possibilidade de associação, direta ou indireta, a um indivíduo”, tal como acontece com o procedimento de anonimização, nos termos da Lei Geral de Proteção de Dados.
Além disso, mesmo que oculte os nomes, as informações ainda podem ser consideradas dados pessoais, se permitirem a reidentificação. Na nossa tabela de exemplo, só existe uma pessoa que avaliou tanto o evento ‘Publicadores de dados’ e ‘Coda 2020’. Se isso for suficiente para conseguir deduzir o nome da pessoa em questão, “considerando a utilização de meios técnicos razoáveis e disponíveis” (art. 5 da LGPD), então, mesmo com pseudônimos as informações ainda podem ser ainda podem ser consideradas como dados pessoais.
É preciso estar cientes destas limitações, mas se bem aplicada a pseudonimização pode ser uma grande aliada na proteção de dados e na transparência. Vejamos então como implementar um procedimento simples de pseudonimização na prática, passo a passo, usando o editor de planilhas do Google Sheets.
PASSO 1 – FAÇA UMA CÓPIA DA PLANILHA
Acesse nossa tabela de exemplo e faça uma cópia (Arquivo > Fazer uma cópia).
PASSO 2 – CRIAR UMA NOVA ABA OU PÁGINA
Insira uma nova aba/página no documento usando o menu ‘Inserir > Nova página’ ou por meio do botão disponível na parte inferior da planilha, onde você pode também alternar entre as páginas do documento. Vamos aproveitar e mudar o nome desta nova página para “Nomes”, confira na imagem abaixo.
PASSO 3 – REMOVER AS DUPLICATAS
Agora, vamos listar cada um dos nomes que queremos anonimizar, removendo as duplicadas.
Para isso, vamos copiar o conteúdo da coluna A da tabela para a nova página.
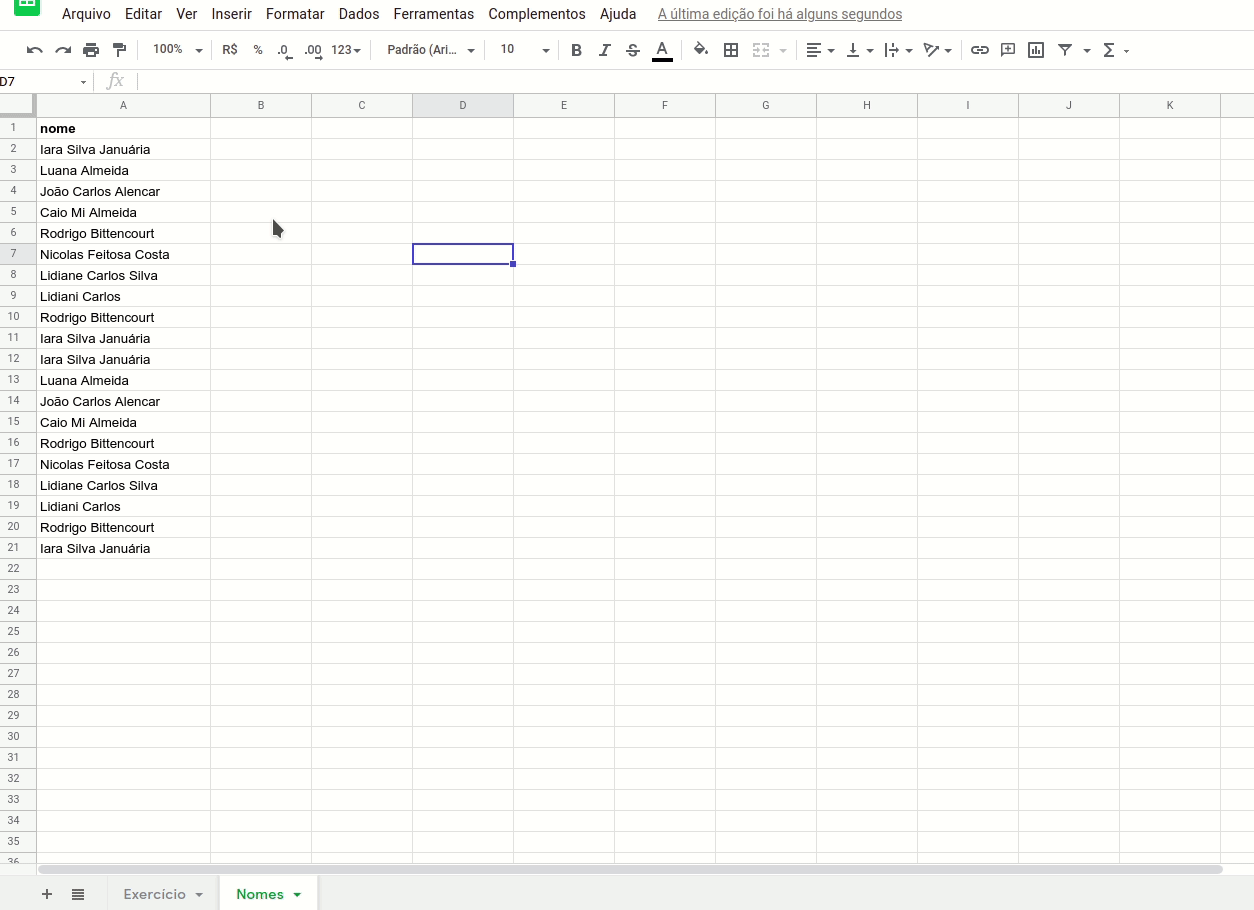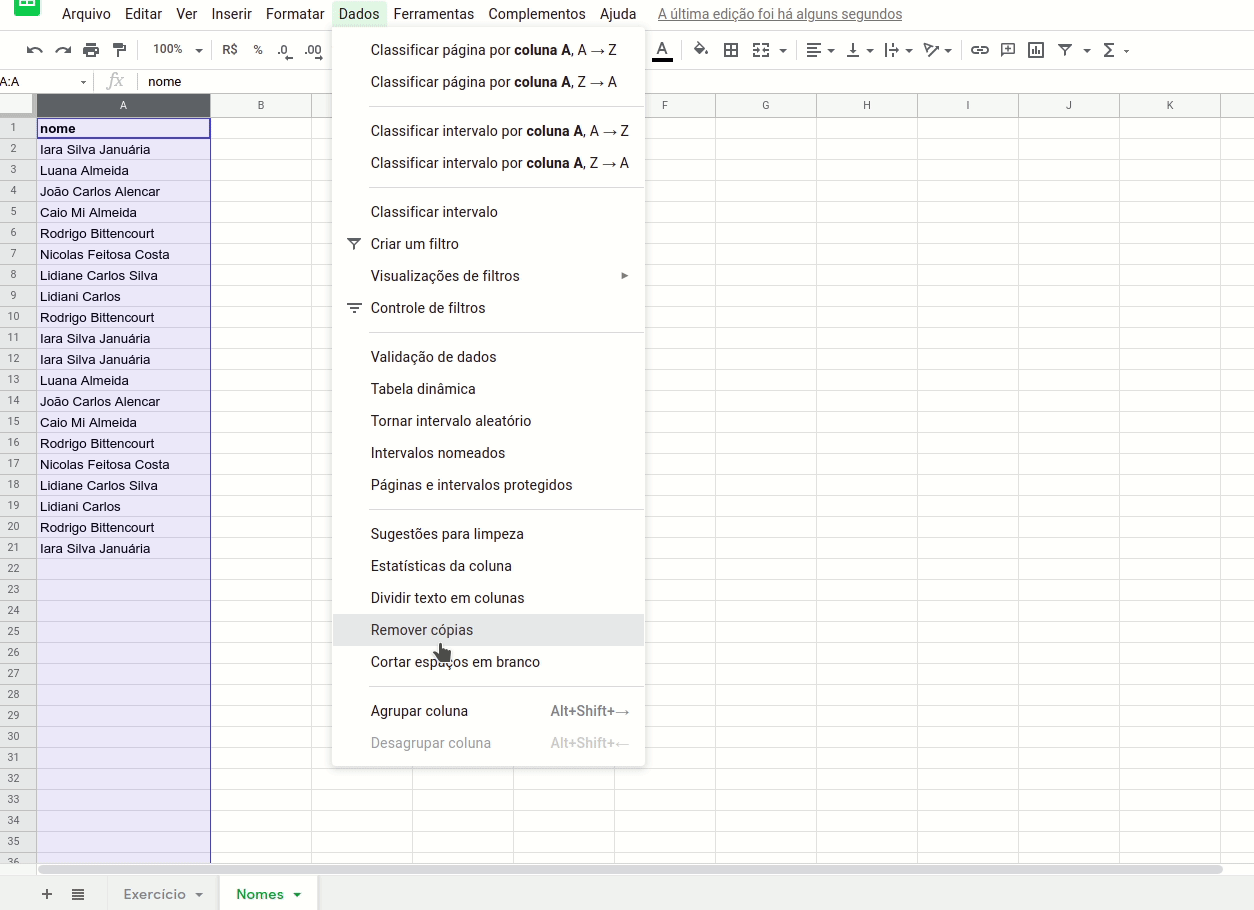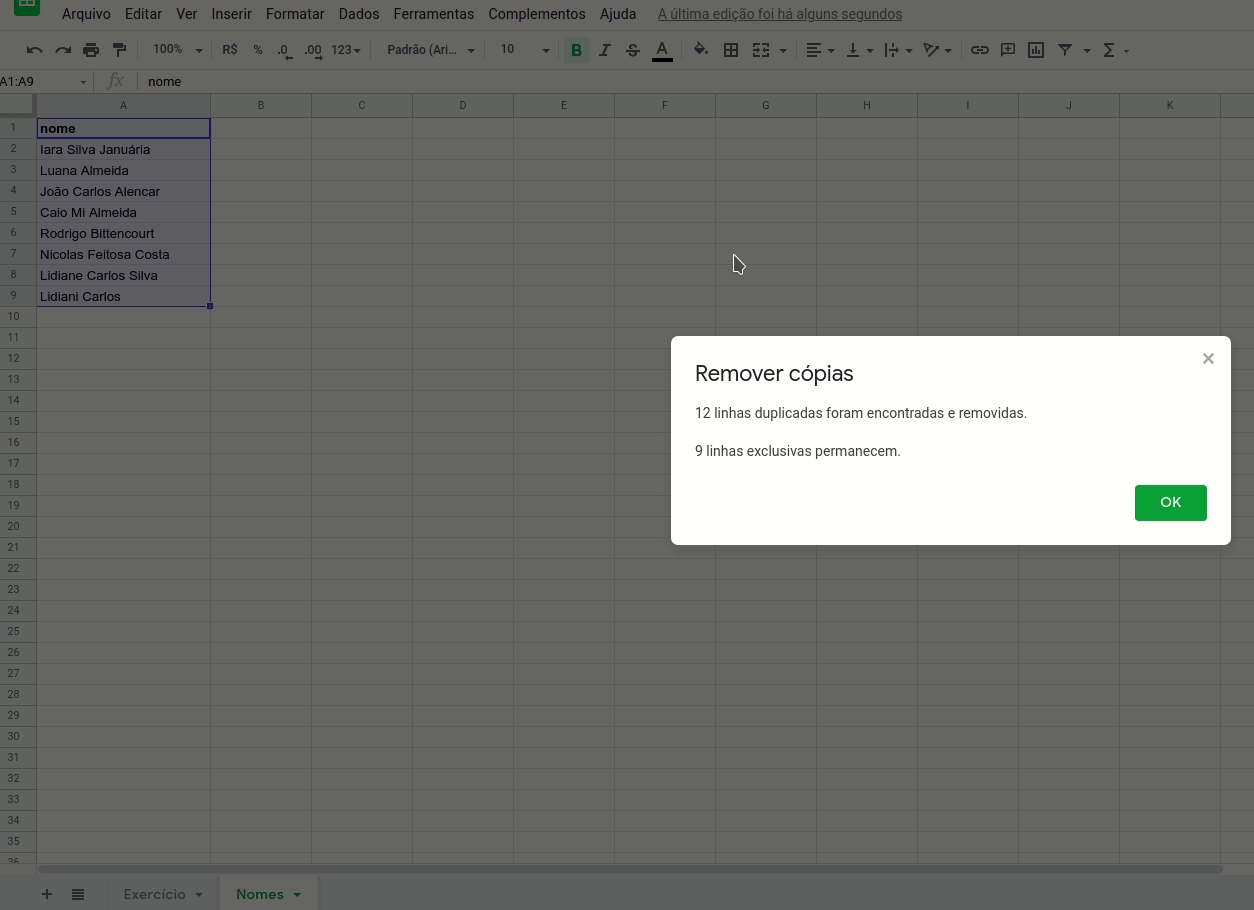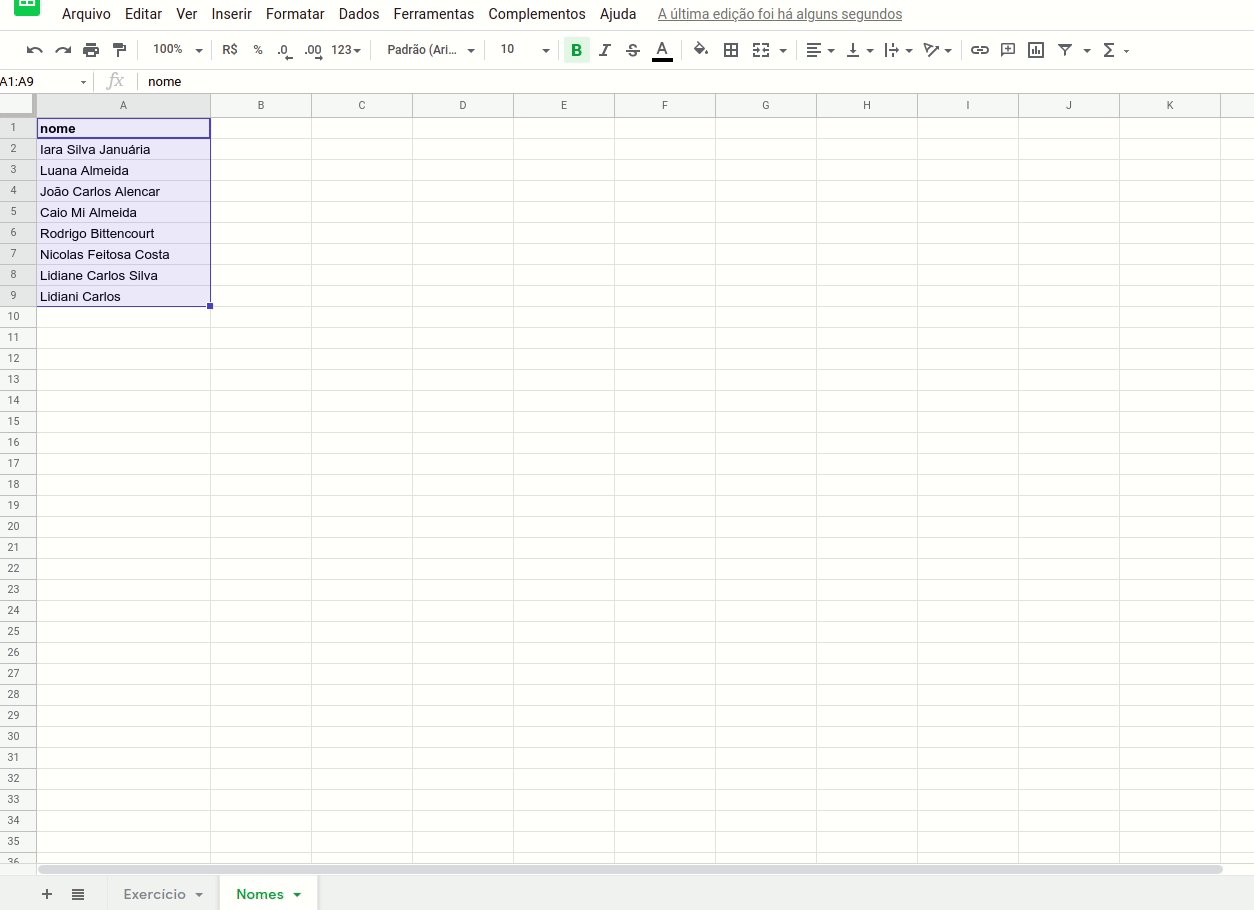
Para remover as duplicatas, basta selecionar a coluna recém-transferida para a página “Nomes” e clicar no menu ‘Dados > Remover cópias’.
 PASSO 4 – CRIAR OS IDENTIFICADORES ÚNICOS
PASSO 4 – CRIAR OS IDENTIFICADORES ÚNICOS
Para criar os identificadores únicos, vamos adotar o seguinte padrão “NOME1”, “NOME2”, “NOME3” e assim por diante. Felizmente, não precisamos fazer a numeração manualmente, basta digitar o primeiro valor e arrastar ou dar dois cliques no quadrado azul que aparece no canto inferior direito de cada célula. Confira na imagem abaixo.
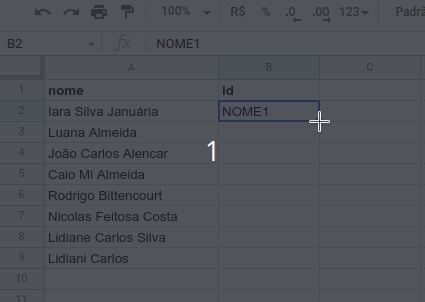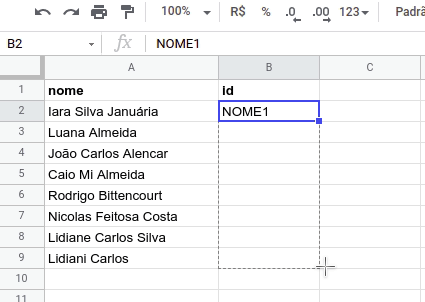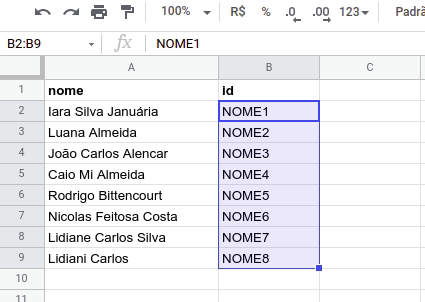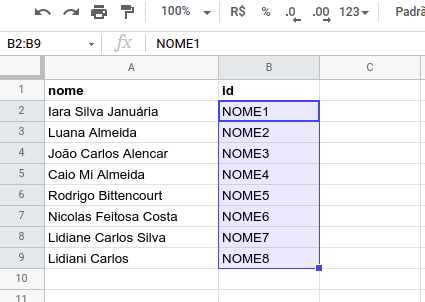 PASSO 5 – SUBSTITUIR OS NOMES PELOS IDENTIFICADORES
PASSO 5 – SUBSTITUIR OS NOMES PELOS IDENTIFICADORES
De volta a nossa tabela principal, vamos adicionar uma nova coluna que deverá ser preenchida com o identificador correspondente ao nome, de acordo com as relações que estabelecemos no passo anterior.
Se você fazer isso manualmente seria preciso seguir estas etapas para cada linha da tabela:
- Olhar o nome que está na coluna A da linha em questão.
- Consultar a primeira coluna da página que criamos com a correspondência entre nomes e identificadores, percorrendo verticalmente cada linha até encontrar o nome da etapa anterior.
- Retornar como resultado o identificador presente na segunda coluna da tabela com as relações (aba “Nomes”) e preencher no local adequado.
É precisamente isso que a função VLOOKUP ou PROCV faz. O nome e a forma como você irá chamá-la vai depender das configurações do seu editor de planilha, mas o funcionamento básico da função é o mesmo em todos os softwares.
A função receberá quatro parâmetros entre os parênteses, separados uns dos outros por ponto-e-vírgula.
1) Primeiro, apontamos o valor ou a célula que queremos buscar. No caso, o nome listado na coluna A de nossa aba.
2) Depois, definimos onde queremos buscar este valor, tomando o cuidado para que o identificador que permitirá o cruzamento seja a primeira coluna selecionada. No exemplo, queremos buscar no intervalo das duas primeiras colunas da nossa aba “Nomes”.
3) Depois, considerando o intervalo definido acima, dizemos qual é a coluna que queremos retornar.
4) Por fim, o último parâmetro diz a respeito dos critérios de classificação. Em geral, vamos usar sempre “falso”.
Vamos colocar esta função em ação na aba ‘Exercício’. Use uma coluna vazia ou insira uma nova ao lado da coluna com os nomes (selecione a coluna A e vá no menu Inserir > Coluna à direita).
No caso, escolhemos a segunda opção e criamos uma nova coluna B chamada “identificador”. Vamos inserir a fórmula nesta coluna ao lado do nome, começando pela linha 2.
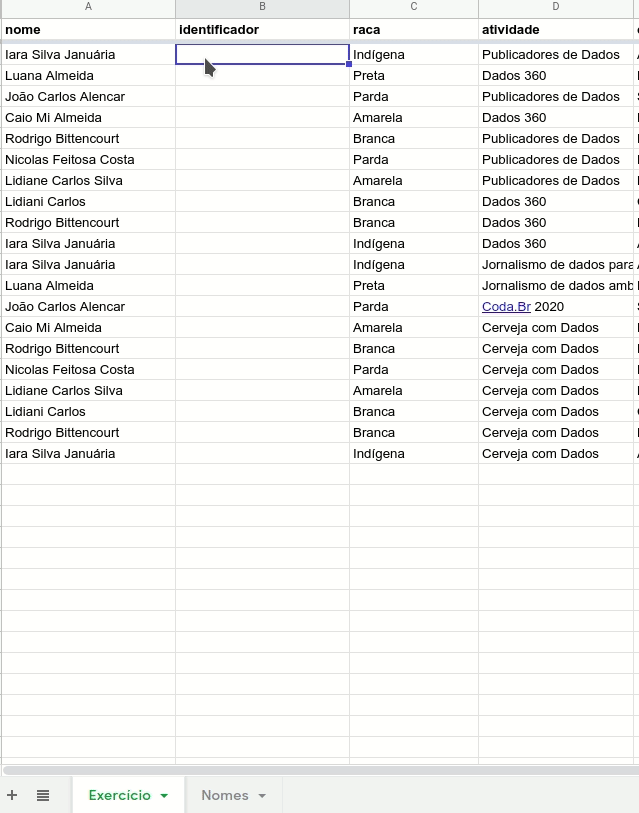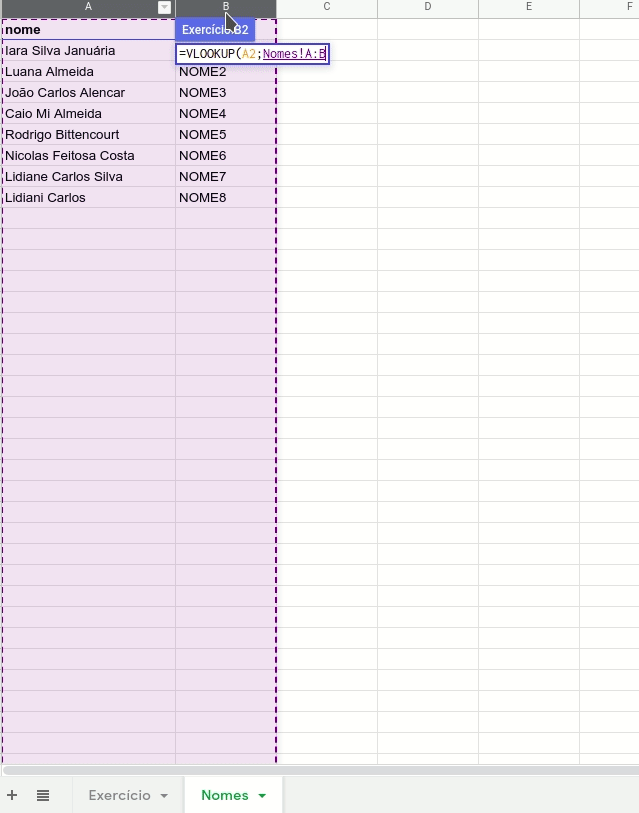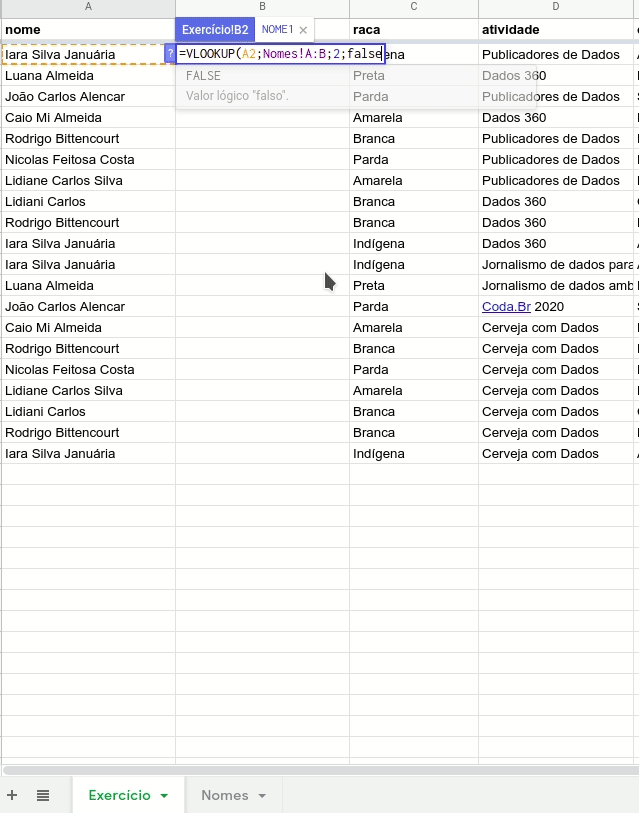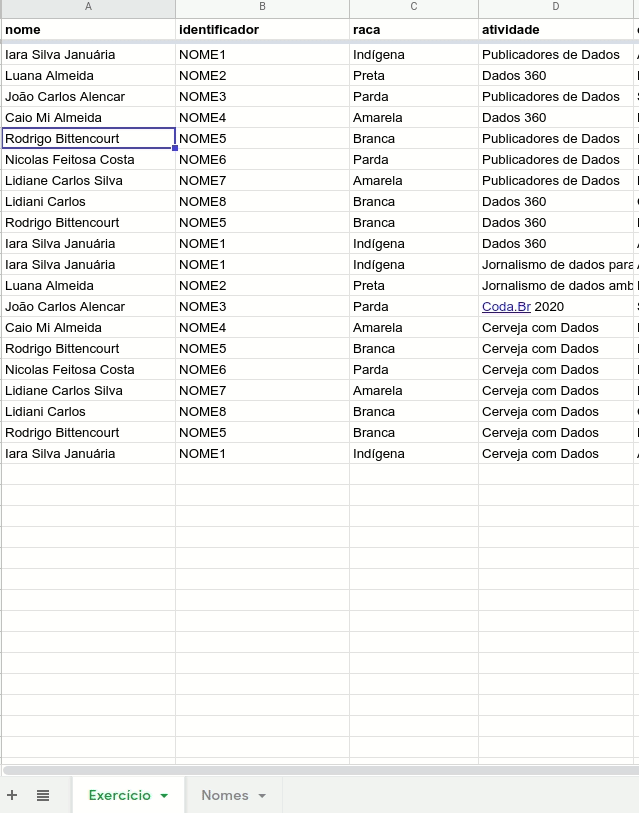
A fórmula é a seguinte.
=VLOOKUP(A2;Nomes!A:B;2;false)
A2 é a coluna com o nome que queremos buscar.
Nomes!A:B é onde queremos buscar, ou seja, na aba “Nomes”, usando o intervalo das duas primeiras colunas (coluna A e coluna B).
2 indica que queremos como resultado a segunda coluna do intervalo definido anteriormente (ou seja, a coluna B).
O último parâmetro mantenha sempre como false, a menos que você tenha necessidades avançadas de melhoria no desempenho. Tenha cuidado pois a omissão deste parâmetro pode levar a resultados equivocados. Para entender mais sobre a função, consulte a documentação do Google Sheets.
CONCLUSÃO
Pronto, agora bastaria deletar a coluna original com os nomes e você já teria uma tabela anonimizada, que preserva as possibilidades de análise dos dados.
Ficou com dúvidas? Alguma experiência ou referência sobre o tema para compartilhar? Deixe um comentário abaixo!
*Este tutorial foi elaborado por Adriano Belisário com base no exercício de Fréderic Le Guen e nas contribuições de Rafael Zanatta no contexto do curso Publicadores de Dados.









muito obrigado pela aula
Muito bom, obrigada
excelente, obrigada!