
#23 Algoritmos regulados, 5 erros e 7 pecados
*Este conteúdo integra o acervo de Boletins de Dados, nossos informativos mensais sobre as principais novidades e oportunidades relacionadas ao trabalho com dados. Para acessar as edições mais recentes reunidas na seção exclusiva e receber a próxima edição em sua caixa de entrada, junte-se ao nosso programa de membresia e apoie nosso trabalho.
Abril/2021
|
Olá, Em maio, teremos o início da terceira turma do curso ‘Dados 360’ e a primeira do ‘Jornalismo de dados ambientais’, que será disponibilizado de forma aberta no mês seguinte. Ao todo, seguindo nosso compromisso pela democratização do conhecimento, e apenas no último mês, oferecemos quase 500 vagas gratuitas, com atenção especial para grupos sub-representados, em todos os estados brasileiros. Seu apoio como participante do programa de membresia é muito importante para que os dados abertos se tornem cada vez mais acessíveis Brasil afora! Caso tenha interesse em participar da próxima turma do curso Dados 360, utilize o cupom #membresia para usufruir do desconto de 20%. Por falar em democratizar conhecimentos, neste mês lançamos de forma aberta todos os materiais do curso ‘Jornalismo de dados para coberturas locais’, realizado no ano passado, e o ebook Publicadores de dados: da gestão estratégica à abertura, baseado no curso homônimo que desenvolvemos. Também temos novos webinars agendados. No dia 11 de abril às 19 horas, receberemos Fernanda Scovino, da Base dos Dados, que mostrará as possibilidades de utilização da biblioteca Python desta plataforma para análise de dados ambientais. No dia 29 de junho, mesmo horário, será a vez de lançarmos o ebook da Escola de Dados de forma aberta, com participação de Adriano Belisário, Marina Gama, Marília Gehrke e Rodrigo Menegat, que assinam a autoria dos capítulos. Os links serão enviados por email e, como participante do programa, você já tem acesso a nossa publicação. Tenha uma boa leitura e um excelente mês de maio, Adriano Belisário |
AGENDA
Oportunidades e prazos para não perder de vista
• 01/05 – Um dia após o término do International Symposium on Online Journalism, tem o 14º Colóquio Ibero-americano de Jornalismo Digital, completamente virtual, com registro gratuito.
• 01/05 – Acontece a live “Building your Data Science portfolio using GitHub” realizada pela AI Inclusive.
• 02/05 – Prazo para inscrição de palestras no V International Seminar on Statistics with R, realizado pela Universidade Federal Fluminense.
• 03/05 – Começa o I Encontro de Mulheres na Estatística e Ciência de Dados – EMECD, realizado pela Universidade Federal do Rio de Janeiro. O evento é aberto a pessoas de todos os gêneros.
• 04/05 – Abertura da csv,conf,v6, que acontecerá online com inscrições gratuitas.
• 05/05 – Prazo estendido da chamada de resumos de trabalhos acadêmicos sobre o OpenStreetMap para a conferência State of the Map.
• 06/05 – Último dia de inscrições para as bolsas anuais MJ Bear Fellowship, direcionadas a jornalistas em início de carreira.
• 10/05 – Abertura de inscrições para o curso Ciência de dados com R e o Tidyverse, organizado por grupos da Universidade Estadual de Campinas (Unicamp).
• 11/05 – Às 19h, a Fernanda Scovino vai falar sobre as possibilidades de utilização da biblioteca Python da Base dos Dados para fazer análise de dados ambientais, no webinar realizado pela Escola de Dados.
• 12/05 – Acontece o seminário “Cobrindo as maiores florestas tropicais do mundo” ministrado por Gustavo Faleiros, parte da série de apresentações semanais do Global Journalism Seminars do Reuters Institute.
• 15/05 – Último dia para aproveitar a taxa de inscrição antecipada da conferência useR! 2021.
• 15/05 – Encerramento da chamada de propostas de apresentações de trabalhos inéditos para a conferência Information+.
• 18/05 – Acontece o coffee talk ‘Geospatial and Statistical Standards’, da série de conversas sobre informações geoespaciais e estatísticas.
• 19/05 – Primeiro dia da Collaborative Journalism Summit, que contará três dias de programação com workshops e discussões sobre jornalismo colaborativo.
• 19/05 – A 2021 Tech and Racial Equity Conference: Anti-Racist Technologies for a Just Future, realizada pelo Center for Comparative Studies in Race & Ethnicity da Stanford University, contará com a presença de Nina da Hora (Ogunhê).
NO MUNDO DOS DADOS
Notícias e discussões quentes
Algoritmos regulados
A União Europeia quer limitar o uso de Inteligência Artificial na sociedade. É o que indica um documento vazado, de acordo com matéria da BBC publicada em abril. Segundo a nova proposta, estariam banidos sistemas de IA que manipulam comportamentos, opiniões ou decisões humanas, além daqueles que servem para vigilância indiscriminada e generalizada. Também estão na mira algoritmos utilizados para pontuação social.
A proposta estipula regras duras para as chamadas IA de “alto risco” – como algoritmos de recrutamento, de crédito financeiro ou de previsão de crimes, por exemplo – com multas equivalentes às do GDPR, o Regulamento Geral sobre a Proteção de Dados europeu. A Comissão Europeia também sugere que novos sistemas de IA tenham supervisão humana e que os sistemas de “alto risco” tenham um algo como um botão de desligar, um mecanismo de fácil desativação.
Por conter itens muito genéricos, a proposta de regulação foi criticada por alguns especialistas e organizações. Por motivo semelhante, a recém-publicada Estratégia Brasileira de Inteligência Artificial no Brasil também foi alvo de críticas. Ronaldo Lemos criticou o documento por não trazer metas, orçamento ou planejamento de implementação das propostas. E apontou que esta política ignora as disciplinas distintas do campo de IA, que requerem ações específicas.
Lemos também lembrou que o Governo Federal realizou uma consulta pública entre dezembro de 2019 e março de 2020 com inúmeras contribuições substanciais – todas ignoradas. Segundo ele, o documento está muito aquém dos planos apresentados por outros países, como Japão, Índia e Uruguai.
Dados para uma vida melhor
Este é o mote da edição de 2021 do Relatório de Desenvolvimento Mundial do Banco Mundial, que oferece planos para aproveitamento dos dados em prol do desenvolvimento social e econômico. A publicação aponta os benefícios do uso de dados por governos, empresas privadas e indivíduos, destacando a necessidade de se estabelecer um novo contrato social sobre dados, em nível nacional e internacional.
Confira o resumo do relatório em português, com as principais mensagens sintetizadas em 4 páginas.
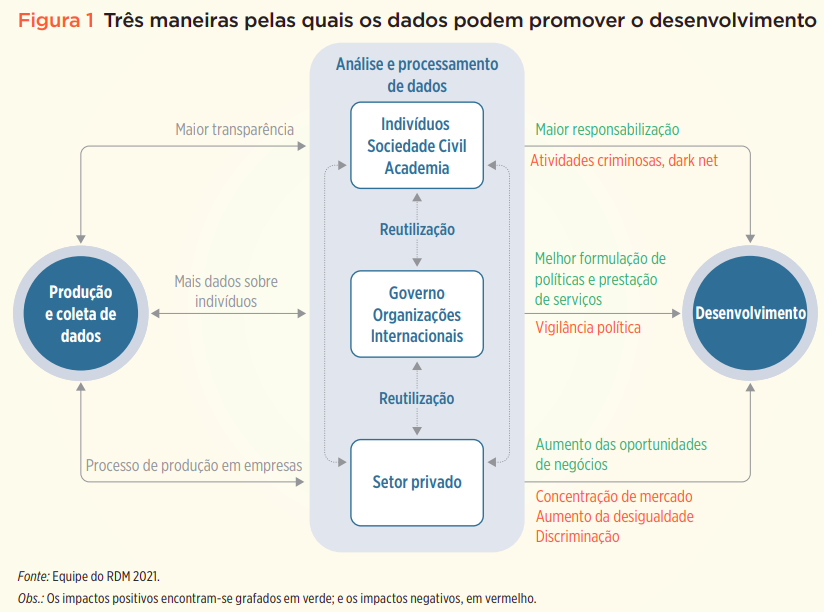
Diagrama com as interações entre atores sociais e impactos positivos e negativos dos dados na sociedade.
O relatório enfatiza a necessidade de estimular a reutilização de dados, criar um acesso mais equitativo aos benefícios deles advindos, promover a confiança por meio de salvaguardas, que protejam as pessoas contra prejuízos causados pelo uso indevido, e abrir caminho para um sistema nacional de dados, descrito em mais detalhes no último capítulo da publicação.
Letramento em dados
Trazendo diversos exemplos, incluindo a metodologia da rede da Escola de Dados (School of Data), a publicação “Advancing data literacy in the post-pandemic world – A primer to catalyse policy dialogue and action” compartilha insights, traz um panorama do letramento em dados no presente e indica caminhos futuros.
A pesquisa aponta que o letramento em dados vai além das habilidades técnicas e pode ser aplicado no nível individual, organizacional ou entre grupos de organizações. Também destaca que esta é uma habilidade importante para todas as pessoas, não apenas entusiastas ou especialistas.
Na mesma toada, na Tech Republic, a jornalista N. F. Mendoza defende que está na hora de curar a fobia de dados e argumenta que o letramento em dados está se tornando fundamental para profissionais de todas as áreas das empresas de tecnologia. Mas quase sempre essa capacidade não está nivelada da mesma forma entre a equipe.
O que fazer quando pessoas com treinamento em linguagens de programação – como Python e R – precisam trabalhar com outros profissionais que lidam apenas com programas com interface gráfica, como o Excel ou o Google Sheets? Allison Horst e Jacqueline Nolis trouxeram reflexões importantes para pensar a formação dos profissionais que trabalham com dados. Leitura recomendada para quem dá aulas ou treinamentos sobre o tema.
SAIBA MAIS
Para aprender mais e aprender sempre
Aprenda Python
Muitos conteúdos fresquinhos para quem quer aprender Python. Se quiser ir se aquecendo para nosso próximo webinar, veja a postagem de Fernanda Scovino explicando como utilizar o pacote em Python da Base dos Dados.
Já se você está na estaca zero, talvez valha conferir antes o canal do Labcom da Universidade Federal do Maranhão, que está disponibilizando tutoriais gratuitos e básicos sobre Python. Porém, se você já conhece SQL e quer fazer uma transição para o Python, recomendamos este post recente de Vivienne DiFrancesco, que traz um comparativo de funções básicas para trabalhar com dados em Pandas e SQL. Ainda sobre Pandas, Parul Pandey explora mais de 50 parâmetros pouco conhecidos na função “read_csv”.
5 erros ao estudar matemática para trabalhar com machine learning
O cientista de dados Cornellius Yudha Wijaya lista cinco erros para se evitar ao estudar matemática para avançar nos seus estudos em aprendizagem de máquina. Além das sugestões abaixo, Wijaya também dá dicas de recursos adicionais para aprender mais sobre o assunto.
1) não saber quais assuntos de matemática são necessários para o tema. A sugestão é começar por Álgebra Linear, Cálculo Multivariado e Métodos de Otimização;
2) não pedir ajuda (você pode entender melhor como pedir e receber ajuda na internet no nosso tutorial recém-publicado ‘Como pedir e receber ajuda na Internet’);
3) pular para o aprendizado da matemática de Machine Learning sem conhecer o conceito dos algoritmo de aprendizagem de máquina;
4) focar em matemática para Machine Learning em vez de matemática para Ciência de Dados;
5) prender-se ao modo de aprendizagem dos tempos de escola.
Para iniciados na matemática, outro conteúdo sobre o tema é o vídeo do canal ‘AI Coffee Breaks with Letitia’, que explica como redes neurais podem resolver problemas de matemática simbólica, como integração, equação diferencial ordinária, etc. A animação é uma adaptação da pré-publicação científica “Deep Learning for Symbolic Mathematics“.
Inteligência com fontes abertas
No blog do Social Links, foi publicado um “resumão” do campo, com um panorama das atividades de Open Source Intelligence (OSINT) no ano de 2021. O texto explica as definições do termo, seus usos atuais, riscos legais, desafios, métodos, técnicas e ferramentas, além de citar casos de investigações notáveis feitas com estas ferramentas e um breve resumo deste mercado no futuro próximo. Segundo a reportagem do Yahoo Finance citada, até 2026, este mercado deve atingir mais de 11 bilhões de dólares, com uma taxa de crescimento anual de 17%.
E Nico Dekens realizou um seminário sobre investigação de grupos de ódio usando as técnicas de OSINT. A apresentação traz metodologias, táticas e técnicas para trabalhar com o tema.
7 pecados capitais da análise de dados
Evitar o orgulho e respeitar os dados, mesmo quando eles contrariam nossa intuição ou expertise. Não ceder à luxúria de se relacionar com dados atraentes, porém sujos (com valores ausentes, outliers estranhos, etc). Tampouco ser preguiçoso e se contentar com a análise de apenas uma métrica.
Estes são alguns dos pecados capitais da análise de dados, listados na postagem de George Weiner. A lista segue.
Para ele, devemos também evitar a ambição de testar muitas hipóteses. Outro problema é a gula em converter muitos dados em muitos gráficos. Atente-se às estatísticas que realmente importam, sugere. O autor também faz apelos ao pensamento crítico na hora de analisar dados e repudia a inveja, como quando julgamos nosso trabalho a partir de referências externas, que muitas vezes parecem inacessíveis.
SNIPPETS
Dicas curtas e certeiras sobre o trabalho com dados
A Open Knowledge Foundation está contratando um desenvolvedor sênior com experiência em Python e front-end, para atuar em um projeto de desenvolvimento do CKAN.
•
Novidades na podosfera: Alberto Cairo e Simons Rogers estrearam o ‘The Data Journalism Podcast’ e, por aqui, tivemos o lançamento do Cidades Abertas, apresentado por Rafael Velame e Ana Paula Gomes.
•
No canal do Curso-R, vale a pena conferir o recente bate papo com Ana Carolina Moreno, Cecília do Lago e Renata Hirota sobre a carreira e campo de jornalismo de dados no Brasil.
•
Stephanie Evergreen fez uma postagem sobre alternativas ao uso da escala logarítmica em gráficos, considerada de difícil compreensão para o público não-científico. Agrupar dados ou dividir os gráficos são algumas das soluções apresentadas.
•
Em mais um excelente trabalho de visualizações de dados, o The Pudding explorou as preferências musicais em cada localidade.
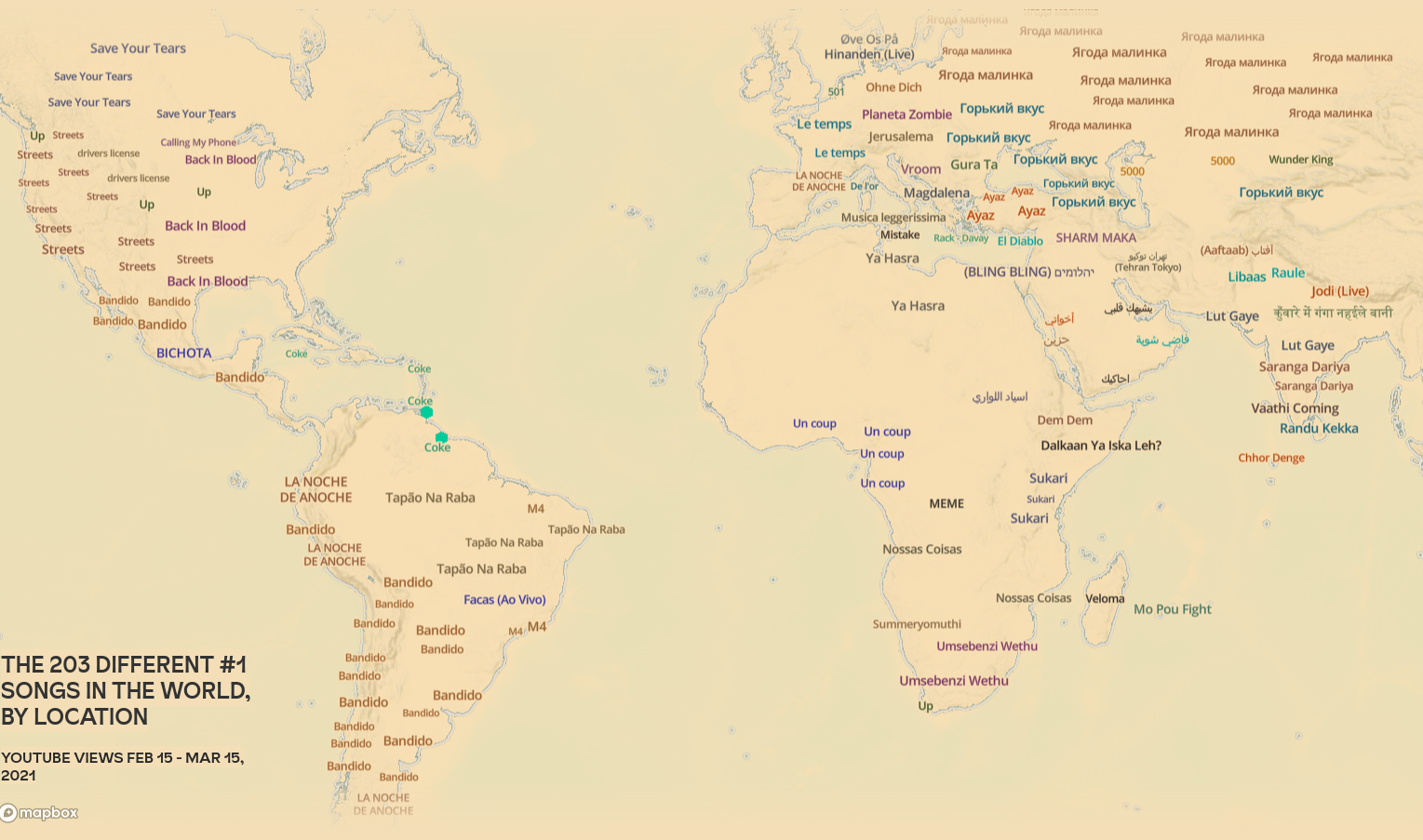
Mapa mundial das preferências musicais elaborado pelo The Pudding.
•
Acaba hoje, 30 de abril, a edição de 2021 da ISOJ (International Symposium on Online Journalism). Atividades sobre dados fizeram parte da programação, como este como comunicação segura para receber denúncias e vazamentos.
•
A Universidade Federal do Paraná disponibilizou um curso inteiro sobre estatística, que foi realizado remotamente devido à pandemia.
•
Também no YouTube, o webinar WikiProject Brazilian Laws traz um treinamento técnico em modelagem e importação do arcabouço da legislação brasileira para o Wikidata.
•
O Pollicy lançou um relatório recente sobre o futuro dos dados, a partir de uma perspectiva afrofeminista, e fez um fio no Twitter sobre o assunto.
INSPIRA
Trabalhos e iniciativas inovadoras para te inspirar

“Podemos compartilhar dados anônimos com terceiros”. Se você já leu essa frase em algum lugar, faça o teste do The Observatory of Anonymity.
O site interativo, disponível em inglês, questiona as técnicas de anonimização de dados mostrando que, com as informações certas, pode ser muito fácil identificar uma pessoa. Respondendo a perguntas a respeito da sua localização, dia de aniversário, gênero, estado civil, religião, raça e nível educacional, você descobre qual a probabilidade de encontrar outras pessoas com o mesmo perfil.
Um alerta: na maioria dos casos, as chances são bem pequenas, o que torna a probabilidade de re-identificação do seu perfil bem grande. E, fique tranquilo, as suas respostas não serão coletadas, nem armazenadas por nenhum servidor.
Os idealizadores da plataforma desenvolveram um modelo estatístico para avaliar a probabilidade de re-identificação dos usuários. O modelo foi publicado no artigo ‘Estimating the success of re-identifications in incomplete datasets using generative models’ e a abordagem foi validada em 210 conjuntos de dados.
A iniciativa foi mencionada por Cory Doctorow, que destacou que ataques de re-identificação são “sutis, variados e muito, muito difíceis de se defender” e “altamente automatizáveis”. O jornalista também mostrou este artigo de opinião do New York Times, exemplo prático de uma investigação feita pelo The Times Privacy Project que evidencia a facilidade em se re-identificar dados anônimos e rastrear a localização de quase qualquer pessoa utilizando dados de softwares de localização disponíveis em celulares.
UPDATE
Atualize-se com as novidades de softwares e bases de dados
A partir de maio, a Agência Nacional de Petróleo irá disponibilizar gratuitamente cerca de 2 terabytes de dados sobre bacias sedimentares brasileiras, visando incentivar investimentos e concessões no setor de óleo e gás.
•
A Base dos Dados facilitou o acesso a diversos indicadores educacionais nacionais, incorporando dados do INEP, e lançou sua biblioteca para R.
•
A DadosJusBrasil disponibilizou os dados relacionados às remunerações dos membros do Ministério Público Federal e código do raspador de dados utilizado.
•
A OSF atualizou um banco de dados global sobre abortos, com informações de 1990 a 2018, trazendo também informações sobre a fonte e qualidade dos dados.
•
O Distrito Federal lançou o Sistema Distrital de Informações Ambientais (SISDIA), uma plataforma que pretende compartilhar, armazenar, atualizar e compartilhar dados espaciais ambientais do Distrito Federal.
•
O Facebook publicou o Casual Conversations, um conjunto de dados com mais de 45.000 vídeos e 3.000 participantes, cujo principal objetivo é servir como parâmetro para avaliação da performance de modelos de inteligência artificial já treinados em relação a vieses de gênero, raça e idade.
•
O RAWGraphs disponibilizou seu código-fonte publicamente.
•
A versão web do Google Photos ganhou o recurso Google Lens com reconhecimento óptico de caracteres (OCR), dando a possibilidade de extrair textos de imagens.
•
A IDE Spyder chega à versão 5 trazendo alguns recursos interessantes, dentre eles uma nova API para estender os plugins principais, nova arquitetura para acessar e escrever opções de configuração e temas novos e melhorados.
•
VS Code também com novos recursos, na versão 1.55. Dentre os destaques, a melhoria na utilização de notebooks, na acessibilidade e suporte oficial ao Raspberry Pi.
•
O Mapbox disponibilizou novos recursos para sua API de imagens estáticas.
•
O Portal.js é um front-end em Javascript para portais de dados abertos, podendo ser usado em um único conjunto de dados ou em um catálogo, a partir do CKAN
Sugestões? Envie um e-mail para [email protected].
Autoria

Escola de Dados
