
Com a aproximação das eleições em 2020, mais uma vez, abrem-se diversas possibilidades de realizar investigações sobre as candidaturas. Um dos temas mais quentes é a identificação de candidaturas “laranjáveis” ou suspeitas de serem ‘laranjas eleitorais” – tópico abordado no nosso curso Jornalismo de Dados para Coberturas Locais por Cecília do Lago, jornalista especialista em cobertura de eleições.
O mesmo tema foi abordado em um workshop da Conferência de Jornalismo de Dados e Métodos Digitais, o Coda.Br, em 2019. Nele, Cecília do Lago mostrou como identificar potenciais candidaturas laranjas, usando a linguagem de programação R. Confira aqui a apresentação do workshop.
Neste tutorial, porém, vamos trazer o passo a passo para identificar indícios de candidaturas laranjas utilizando um editor de planilha. O processo tem vários passos, mas é recompensador. Você verá uma situação real de cobertura jornalística baseado em dados e, baseado neste tutorial, poderá replicar o método em qualquer eleição, para qualquer município do país.

Imagem:Pixabay
Mas por que tantas laranjas?
Candidaturas “laranjas”, “fantasmas” ou “de fachada”: os nomes podem ser vários. E a prática não é novidade. Mas alguns marcos recentes nos ajudam a entender melhor este fenômeno eleitoral.
Em 2016, o Tribunal Superior Eleitoral (TSE) determinou uma cota feminina de 30% entre as candidaturas. Já naquele ano um levantamento de dados feito na Gênero e Número mostrou que os partidos recorriam a candidaturas fantasmas para bater a cota.
Por conta da imensa quantidade de candidaturas femininas fantasmas em 2016, feitas pelos partidos apenas para escapar da punição de não terem cumprido as cotas, as regras mudaram na eleição seguinte. Em 2018, o TSE determinou que haveria uma proporção igual de direcionamento do dinheiro público do fundo eleitoral para candidaturas de homens e mulheres.
Na prática, isso significa que pelo menos 30% do dinheiro público deveria ir para candidaturas de mulheres. E novamente as laranjas se multiplicaram.
Basicamente, estas candidaturas são registradas sem qualquer pretensão eleitoral de disputar o pleito. O objetivo é unicamente obter o recurso público do Fundo Eleitoral para então desviá-lo para outros finalidades ou candidaturas. Assim, temos muito recurso público injetado na campanha, mas poucos votos na urna.
Então, um ótimo indicador para apontar candidaturas suspeitas é o custo de cada voto. Ou seja, quanto dinheiro público (do Fundo Partidário e o Fundo Especial de Financiamento de Campanha) o candidato recebeu por cada voto obtido nas urnas? Existem outros parâmetros que você pode apurar em paralelo para aprofundar sua apuração (poucas empresas na despesa contratada é um deles por exemplo). Mas o custo do voto é um mais direto e uma ótima forma de começar essa cobertura.
Assim, temos um critério objetivo do que seria um indício de uma candidatura laranja, mas é importante ter cautela. Para você cravar se uma candidatura é laranja ou não, é preciso ir além das planilhas e fazer uma apuração jornalística, consultando outros dados e fontes de informação. A identificação do custo por voto é um ótimo ponto de partida para sua investigação, mas para abordar o tema de forma correta você deve levantar outras informações.
Por isso, aqui, vamos falar de candidaturas “laranjáveis” para tratar dos casos que recebem muito dinheiro público para pouco voto. Mas quais bases de dados combinar para identificar estas candidaturas laranjáveis?
Obtendo os dados
Neste tutorial, vamos usar dados da corrida à Câmara dos Deputados em Minas Gerais na eleição de 2018 para identificar a candidatura com maior custo por voto. Mas o mesmo processo pode ser adaptado para qualquer cargo, de qualquer estado ou eleição.
Nossa resposta virá do cruzamento de dados. De um lado, teremos a prestação de contas para identificar o custo das candidaturas. De outro, uma planilha total de votos por cada candidato.
Prestação de contas eleitorais
Baixe o arquivo ZIP com a prestação de contas dos candidatos em 2018 no seguinte caminho. Para acessar arquivo, usamos o Repositório de Dados Eleitorais do TSE. No menu, selecionamos a opção Prestação de Contas Eleitorais > 2018 > Candidatos.zip. Depois de baixar, descompacte o arquivo no seu computador.
Total de votos por candidatos
Vamos baixar o número de votos das candidaturas do site do Cepesp Data, que agrega e facilita o acesso a dados do TSE. Para isso, selecione a página Resultados Eleitorais. No menu, escolha as seguintes opções:
- Cargo: Deputado Federal
- Agregação Regional: UF
- Agregação Política: Candidato
- Ano: 2018
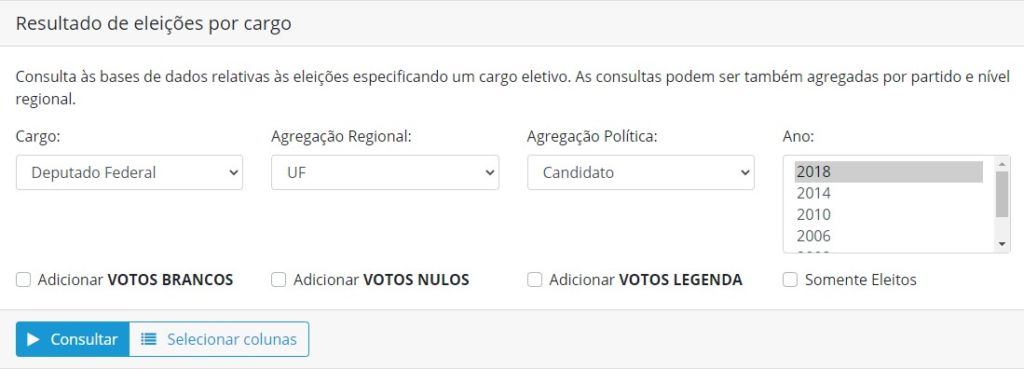
Clique no botão ‘Selecionar colunas’ e adicione a opção “SEQUENCIAL CANDIDATO”.
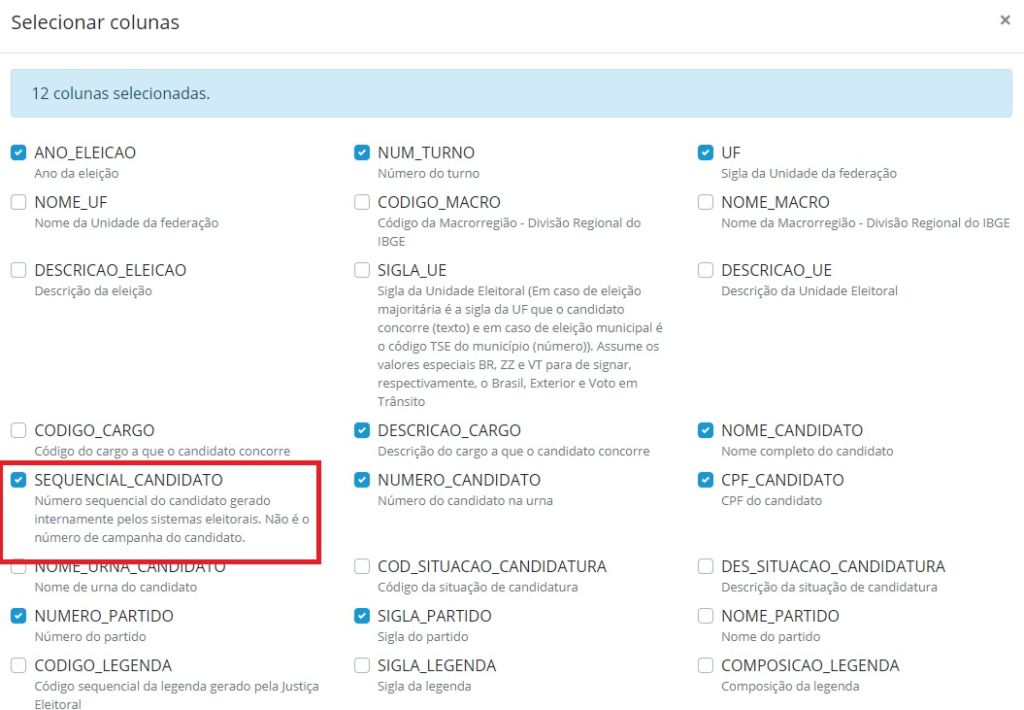
Então, certifique-se que a opção “QTDE_VOTOS” também está marcada e, depois, clique no botão “Consultar”.
Por fim, clique no botão verde “CSV” para baixar a planilha e salvar como um arquivo no seu computador.
Com os dados baixados, vamos fazer a análise desejada.
Aqui, vale uma dica: ao lidar com bases muito grandes no Google Spreadsheets e outros programas é ideal liberar ao máximo a memória do seu computador (memória RAM) fechando outros programas e outras abas do navegador, enquanto você trabalha com dados. Caso você encontre problemas de forma recorrente para lidar com bases muito grandes em editores de planilha, vale dar uma olhada em nosso tutorial sobre SQL ou usar alguma linguagem de programação, como Python ou R.
Descobrindo as receitas das candidaturas
Abra uma planilha em branco Google Spreadsheets (sheets.new) e importe (Arquivo > Importar) os dados obtidos no site do TSE com a receita dos candidatos do seu estado (no nosso caso, “receitas_candidatos_2018_MG.csv”).
Depois, indique a ponto-e-vírgula (“;”) como separador e escolher “Não” na opção “Converter texto em números, datas e fórmulas”.
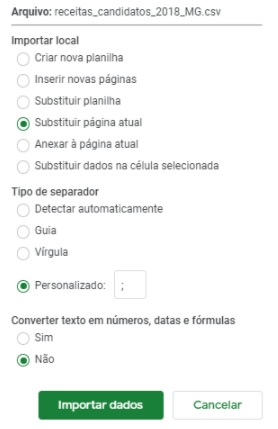
A depender do seu computador e o estado selecionado – e consequentemente o tamanho do arquivo -, este processo pode demorar um pouco.
Depois do carregamento da planilha, transforme a coluna VR_RECEITA (Coluna BE, a última) em Número. Clique na coluna BE e depois no menu Formatar > Número > Moeda.
Se os valores não forem formatados para reais, vá em Arquivo > Configurações da planilha e na seção Localidade selecione o país “Brasil’.
Configure também o campo SQ_CANDIDATO como texto.
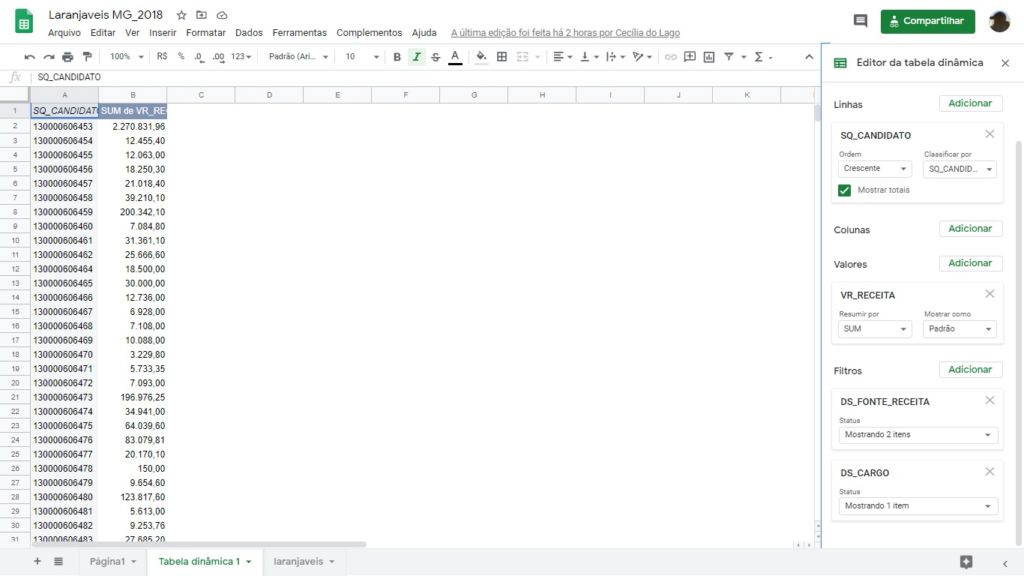
Agora, crie uma tabela dinâmica (Dados > Tabela dinâmica) para realizarmos a soma dos valores recebidos por candidatura. Selecione “OK” na janela que irá abrir para criar uma nova página. Se você nunca trabalhou com isso, sugerimos a leitura deste nosso tutorial sobre tabela dinâmica.
Na tabela dinâmica, selecione as seguintes opções.
- Linhas > Adicionar > SQ_CANDIDATO: pois queremos agregar os dados usando um identificador de cada candidatura.
- Valores > VR_RECEITA: pois queremos somar a receita das candidaturas.
Depois, aplique os seguintes filtros:
- Filtro > Adicionar > DS_FONTE_RECEITA: deixe selecionado só “Fundo Partidário” e “Fundo Especial” para filtrar as receitas oriundas de recursos públicos.
- Filtro > Adicionar > DS_CARGO > deixar selecionado só “Deputado Federal”: aqui, você pode usar a opção ‘limpar’ para desmarcar a seleção dos demais cargos e então selecionar apenas aquele de seu interesse.
- Filtro > Adicionar > DS_NATUREZA_RECEITA > Deixar selecionado só “Financeiro”: para filtrar apenas as receitas financeiras.
Ao final do processo, a configuração da tabela dinâmica deve ficar como na imagem abaixo.
Cruzando com o total de votos
Agora, nesta mesma planilha, importe o arquivo CSV do Cepesp Data (Arquivo > Importar > Upload e selecione o arquivo).
Na caixa com opções de importação que irá aparecer, selecione a opção ‘Inserir novas páginas’ e desabilite a conversão automática de texto para número, datas ou fórmulas.
Então, importe os dados. Não é necessário alterar o separador de campo.
Depois de importar os dados, defina o cabeçalho para “travar” a primeira linha. Se você não sabe fazer isso, veja este tutorial básico sobre planilhas.
Nesta aba recém-importada, o total de votos por candidatos deve estar na coluna M. Agora, iremos adicionar uma nova coluna, ao lado, para obter o total de receitas listados na tabela dinâmica.
Nomeie a célula N1 como DINHEIRO_PUBLICO e, na célula N2, faça uma procura vertical (PROCV/VLOOKUP) para “puxar” os dados da tabela dinâmica. Se você nunca trabalhou com isso, sugerimos a leitura deste tutorial sobre procura vertical.
Para usar esta fórmula, lembre-se que precisamos definir quatro parâmetros:
- O identificador que servirá como base para o cruzamento. No nosso caso, a informação da coluna SEQUENCIAL_CANDIDATO do candidato em questão, ou seja, a célula F2.
- O intervalo dos dados que devem ser cruzados, que em nosso exemplo é a tabela dinâmica recém construída, então, teremos: ‘Tabela dinâmica 1’!A:B
- Considerando o intervalo anterior, identificamos a ordem da coluna que queremos retornar. Como buscamos o total das receitas da tabela dinâmica, que está na segunda coluna (B), vamos indicar aqui o valor 2.
- Por último, vamos manter a opção FALSO. Para mais detalhes sobre este parâmetro, confira o tutorial acima.
Ou seja, sua fórmula deve ficar assim:
=PROCV(F2;’Tabela dinâmica 1′!A:B;2;FALSO)
Para aplicar esta fórmula nas demais linhas, basta dar dois cliques no quadrado azul que aparece no canto inferior direito, quando você seleciona alguma célula.
A maioria das células ficará como “#N/A”. Isso porque a tabela do CEPESP tem candidatos de todo o Brasil, porém a tabela de onde ele está “trazendo” os números só tem valores de gastos em candidatos do estado de MG.
Descobrindo o custo por voto
Agora, temos em uma coluna o total de votos e noutra ao lado o dinheiro público injetado na candidatura. Vamos fazer uma divisão simples entre elas para chegar ao custo por voto.
Na coluna O, vamos criar uma nova coluna chamada CUSTO_VOTO, que irá dividir DINHEIRO_PUBLICO por QTDE_VOTOS.
Para isso, basta adicionar a fórmula abaixo na célula O2:
=N2/M2
E repetir o mesmo processo de clicar no retângulo azul para aplicar a divisão para as demais linhas.
Agora, vamos ordernar a tabela coluna CUSTO_VOTO: selecione a coluna O, clique em Dados e selecione a opção ‘Classificar página por coluna O’. Vamos usar a ordem decrescente (Z -> A)
É importante selecionar a opção ‘classificar página’ e não ‘classificar intervalo’, pois esta segunda pode arruinar sua análise de dados.
Por fim, vamos filtrar a coluna UF (Dados > Filtrar) para deixar apenas as candidaturas de Minas Gerais. E também na coluna CUSTO_VOTO vamos desmarcar o resultado #N/A (o último da lista) para visualizar mais facilmente os resultados.
Voilà!
Se deu tudo certo, sua tabela deve estar parecida com esta. E a candidata com maior CUSTO_VOTO em MG é JULIARINA APARECIDA. A sexta na fila é CAMILA FERNANDES, que foi indiciada nas eleições de 2018 justamente por conta das suspeitas de candidatura laranja.
Agora é com você. Com estes indícios em mão, cabe ao repórter ir atrás de mais informações que possam confirmar ou rejeitar as suspeitas de candidaturas de laranja.
Por fim, em caso de dúvidas ou dificuldades neste exercício, recomendamos que você poste sua questão em nosso Fórum de Jornalismo de Dados.
* Este tutorial foi elaborado por Cecília do Lago, Juan Torres e Adriano Belisário, com base nas aulas de Cecília do Lago no curso de jornalismo de dados local.









UAU… apesar de ter tido problemas baixando os dados da FGV CEPESP (o servidor deles parece estar fora do ar ou com problemas pra processar os CSVs) consegui dar uma volta usando o número de urna dos candidatos que eu tinha baixado antes quando tentei o desafio por conta própria. Eu falhei no desafio por problemas de RAM, depois que o LibreOffice travou pela 4a vez eu desisti. O lado bom é que eu estava seguindo a lógica certa, pelo menos. Com os arquivos daqui eu consegui completar o desafio direitinho no Google Planilhas, agradecido